Une introduction à PyGWalker : Boostez vos visualisations Streamlit
PyGWalker (opens in a new tab) est une bibliothèque exceptionnelle en Python qui transforme les dataframes Python en une interface intuitive de style "tableau", facilitant la visualisation des données.
Traditionnellement utilisé dans Jupyter pour aider les data scientists à plonger dans leurs ensembles de données, PyGWalker brille par sa polyvalence lorsqu'il est combiné à Streamlit. Le charme de Streamlit réside dans sa capacité à créer des applications de données facilement, sans nécessiter de compétences en technologies frontend ou backend. En d'autres termes, vous pouvez créer et partager des tableaux de bord sans tracas.
L'intégration de PyGWalker (opens in a new tab) avec Streamlit vous permet d'établir votre propre "tableau web". Cela permet le partage de tableaux de bord et permet aux utilisateurs d'explorer librement l'interface glisser-déposer intuitive de PyGWalker (opens in a new tab). Les mises à jour récentes ont également introduit une fonction "chat-to-charts", activée simplement en ajoutant une clé API.
Ce qui distingue PyGWalker (opens in a new tab), c'est sa conception native pour le cloud. Grâce à sa capacité à se connecter à une multitude de bases de données cloud, OLAP ou DW, vous êtes assuré d'une expérience hautes performances, surpassant de nombreux outils BI traditionnels coûteux.
Prêt à créer un PyGWalker basé sur le cloud avec Streamlit ? Plongeons-y.
Configuration des dépendances :
pip install pygwalker
pip install streamlitPour ce tutoriel, nous utiliserons un ensemble de données sur les séismes, qui peut être chargé à partir d'un fichier CSV.
def get_df() -> pd.DataFrame:
df = pd.read_csv("./Significant Earthquake_Dataset_1900_2023.csv")
df["Time"] = pd.to_datetime(df["Time"]).dt.strftime('%Y-%m-%d %H:%M:%S')
return dfUne fois chargé, alimentez le jeu de données à PyGWalker :
from pygwalker.api.streamlit import get_streamlit_htm
html = get_streamlit_html(df, use_kernel_calc=True, spec="./spec/geo_vis.json", debug=False)Ensuite, affichez simplement le HTML de PyGWalker à l'aide de Streamlit :
import streamlit.components.v1 as components
components.html(get_pyg_html(df), width=1300, height=1000, scrolling=True)Lancez votre application :
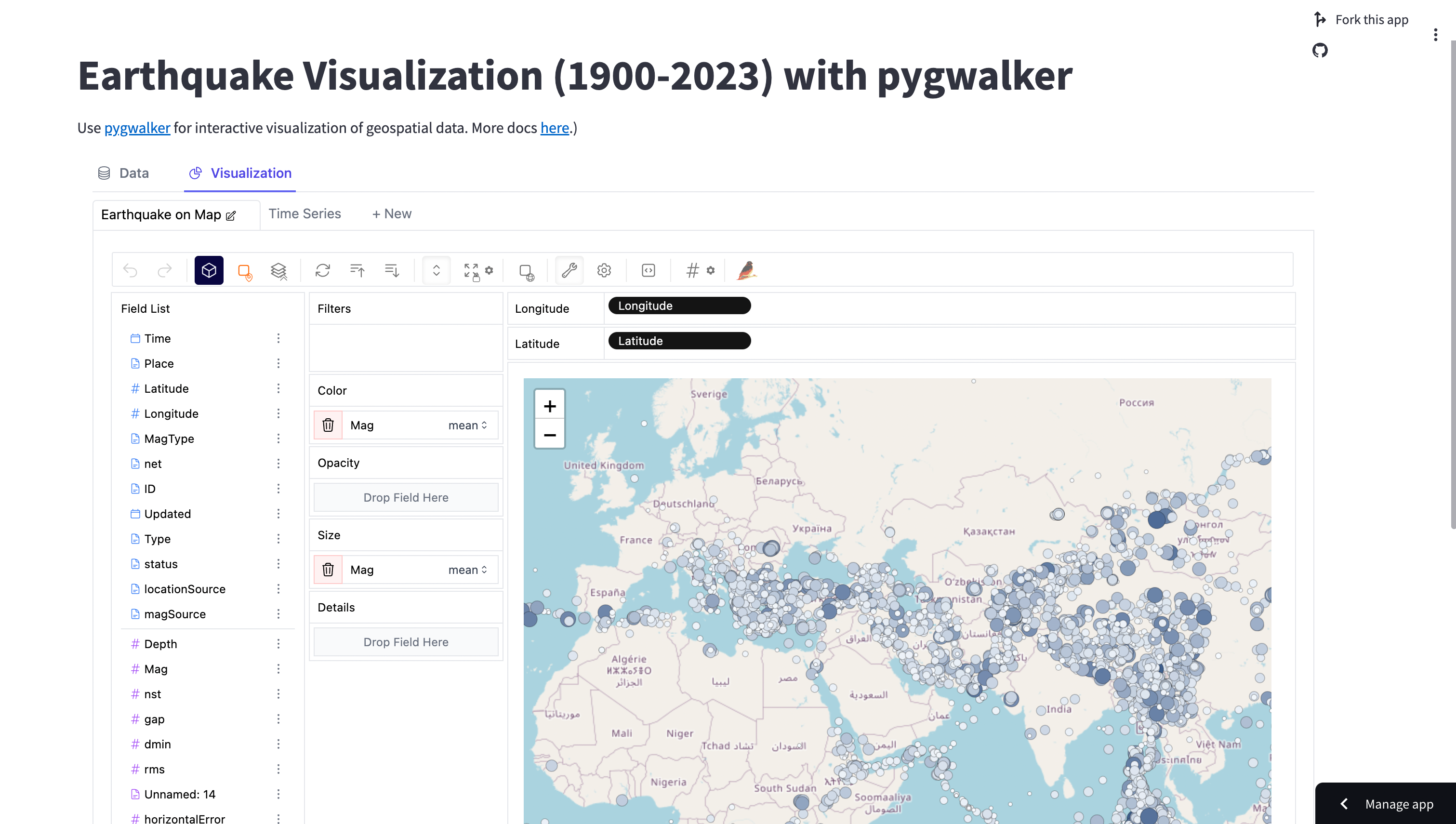
Boostez vos requêtes avec le nouveau moteur de PyGWalker
Depuis la version 0.3, PyGWalker a intégré le moteur de calcul basé sur DuckDB, garantissant des requêtes de données plus rapides, même avec des ensembles de données étendus.
Pour l'activer, ajoutez simplement le paramètre use_kernel_calc :
pyg.walk(df, use_kernel_calc=True)Bien que cela fonctionne parfaitement dans des environnements tels que Jupyter, Streamlit impose certaines limites de transfert de données entre le frontend et le backend. Cependant, grâce à l'équipe de développement de Kanaries, il existe une solution simple :
from pygwalker.api.streamlit import init_streamlit_comm
init_streamlit_comm()Conclusion
La combinaison de PyGWalker avec Streamlit ouvre la voie à la création d'applications de visualisation de données interactives en ligne avec un code minimal. Plongez-y et transformez vos explorations de données dès aujourd'hui !