Vicuna-13B : Une alternative open source à ChatGPT qui impressionne GPT-4

Le domaine des chatbots a connu des avancées significatives ces dernières années avec le développement de grands modèles de langage (LLM) tels que ChatGPT d'OpenAI. Cependant, les détails de l'architecture et de la formation de ChatGPT restent mystérieux, ce qui rend difficile pour les chercheurs de s'appuyer sur ses succès. C'est là qu'intervient Vicuna - une alternative open source à ChatGPT soutenue par un ensemble de données robuste et une infrastructure scalable. Dans cet article, nous plongerons dans les capacités de Vicuna, comment elle a été développée et son potentiel pour la recherche future.
Qu'est-ce que Vicuna, ou Vicuna-13B ?
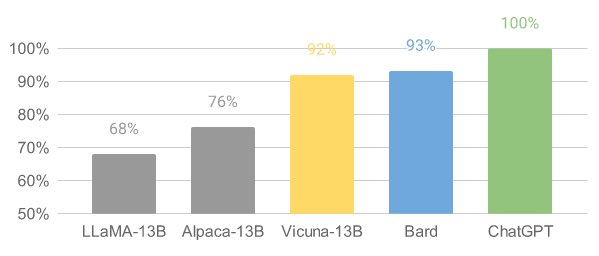
Vicuna (opens in a new tab) est un modèle de chatbot open source appelé Vicuna-13B, créé par une équipe de chercheurs de l'UC Berkeley, CMU, Stanford et l'UC San Diego. Il a été construit en affinant le modèle LLaMA sur des conversations partagées par les utilisateurs de ShareGPT et des évaluations préliminaires montrent qu'il atteint plus de 90 % de la qualité de ChatGPT. Notamment, le coût de la formation de Vicuna-13B est d'environ 300 $.
Comment se comporte Vicuna ?
Vicuna a démontré des performances impressionnantes lors d'évaluations préliminaires. En affinant Vicuna avec 70 000 conversations partagées par les utilisateurs de ChatGPT, le modèle devient capable de générer des réponses détaillées et bien structurées. Sa qualité est comparable à celle de ChatGPT et dépasse celle d'autres modèles tels que LLaMA et Stanford Alpaca dans plus de 90 % des cas.
Développement de Vicuna : infrastructure de formation et de mise en service
L'équipe Vicuna a collecté environ 70 000 conversations à partir de ShareGPT.com et a amélioré les scripts de formation fournis par Alpaca. Ils ont utilisé PyTorch FSDP sur 8 GPU A100 pour la formation et ont mis en place un système de mise en service distribué léger. L'équipe a également réalisé une évaluation préliminaire de la qualité du modèle en créant un ensemble de 80 questions diverses et en utilisant GPT-4 pour évaluer les sorties du modèle.
Pour former Vicuna, l'équipe a affiné le modèle de base LLaMA en utilisant des conversations partagées par les utilisateurs. Ils ont veillé à la qualité des données en convertissant HTML en markdown et en filtrant les exemples inappropriés ou de mauvaise qualité. Ils ont également apporté diverses améliorations à la recette d'entraînement, telles que des optimisations de la mémoire, la gestion des conversations multi-tours et la réduction des coûts via des instances spot.
Le système de mise en service construit pour Vicuna est capable de servir plusieurs modèles avec des travailleurs distribués. Il prend en charge des extensions flexibles pour les travailleurs GPU à la fois sur des clusters sur site et dans le cloud. En utilisant un contrôleur tolérant aux pannes et la fonctionnalité de spot géré dans SkyPilot, le système de mise en service peut bien fonctionner avec des instances spot moins chères provenant de plusieurs clouds, ce qui réduit les coûts de mise en service.
L'équipe Vicuna a publié le code de formation, de mise en service et d'évaluation sur GitHub (opens in a new tab).
Évaluer les chatbots avec GPT-4
L'évaluation des chatbots est une tâche complexe, mais l'équipe Vicuna propose un cadre d'évaluation basé sur GPT-4 pour automatiser l'évaluation des performances des chatbots. Ils ont élaboré huit catégories de questions pour tester divers aspects des performances des chatbots et ont constaté que GPT-4 peut produire des scores relativement cohérents et des explications détaillées de ces scores. Cependant, ce cadre d'évaluation proposé n'est pas encore une approche rigoureuse, car les grands modèles de langage tels que GPT-4 sont sujets à l'hallucination. Le développement d'un système d'évaluation complet et normalisé pour les chatbots reste une question ouverte nécessitant des recherches supplémentaires.
Limitations et recherche future
Vicuna, comme d'autres grands modèles de langage, présente des limites dans les tâches impliquant du raisonnement ou des mathématiques. Il peut également avoir des difficultés à s'identifier de manière précise ou à garantir l'exactitude factuelle de ses sorties. De plus, il n'a pas été suffisamment optimisé en termes de sécurité, de réduction de la toxicité ou de lutte contre les biais. Néanmoins, Vicuna sert de point de départ ouvert pour de futures recherches visant à résoudre ces limitations, ainsi que d'autres percées récentes dans le domaine de l'IA telles que Auto-GPT et LongChain.
FAQ
-
Comment puis-je obtenir et utiliser les poids du modèle Vicuna 13-b ? Pour utiliser le modèle Vicuna 13-b, vous devez télécharger le modèle LLaMa 13B d'origine et appliquer les poids delta fournis par l'équipe de Vicuna. Les poids delta peuvent être trouvés sur https://huggingface.co/lmsys/vicuna-13b-delta-v0 (opens in a new tab).
-
Comment appliquer les poids delta au modèle LLaMa 13B ? Vous pouvez appliquer les poids delta en suivant la commande dans le référentiel FastChat : python3 -m fastchat.model.apply_delta --base /chemin/vers/llama-13b --target /chemin/de/sortie/vers/vicuna-13b --delta lmsys/vicuna-13b-delta-v0. Cette commande téléchargera et appliquera automatiquement les poids delta sur le modèle de base.
-
Puis-je convertir le modèle Vicuna 13-b au format llama.cpp/gpt4all ? Oui, le modèle Vicuna 13-b peut être quantifié au format llama.cpp/gpt4all. Le modèle ne modifie que légèrement les poids existants, sans changer la structure.
-
Y a-t-il des problèmes de licence liés à l'utilisation du modèle Vicuna 13-b ? L'équipe de Vicuna publie les poids sous forme de poids delta afin de respecter la licence du modèle LLaMa. Cependant, l'utilisation du modèle à des fins commerciales peut néanmoins poser problème en raison de complications juridiques potentielles.