拡張分析における ChatGPT の機能の探索: 5 つのユース ケースの説明!

序章
拡張分析は、機械学習と自然言語処理を組み合わせてより正確で効率的な洞察を提供するデータ分析へのアプローチです。 このアプローチの重要なツールの 1 つは、OpenAI によって開発された大規模な言語モデルである ChatGPT です。 このモデルは幅広いテキスト データでトレーニングされており、自然言語による質問応答、データの視覚化、コンテンツ作成など、さまざまなタスクを支援するために使用できます。
この記事では、自然言語による質問応答、データ視覚化、コンテンツ作成、データ生成など、拡張分析における ChatGPT の 5 つのユース ケースについて説明します。
ChatGPT による拡張分析、5 つのユースケース
1. 自動化されたデータクリーニングと前処理
ChatGPT は、重複データや欠落データを特定して削除するなど、大規模なデータセットのクリーニングと前処理を支援できます。 たとえば、pandas DataFrame で重複する行を削除するサンプル コードは次のようになります。
import pandas as pd
df = pd.read_csv("transactions.csv")
df = df.drop_duplicates()
df.to_csv("transactions_cleaned.csv", index=False)2. 質問応答のための自然言語処理
ChatGPT を使用すると、自然言語で尋ねられた質問を理解し、回答することができます。 これにより、より直感的で使いやすいデータ操作が可能になります。
たとえば、ユーザーは「2020 年の会社の総収益は?」と尋ねることができます。 ChatGPT は、データセットから関連情報を抽出し、正確な応答を提供できます。 このユース ケースのサンプル コードには、NLTK や spaCy などの自然言語処理ライブラリを使用して、ユーザーの質問を処理し、データセットから関連情報を抽出することが含まれます。
import nltk
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
# Load the dataset
data = # load your dataset here
# Define a function to process the user's question
def process_question(question):
# Tokenize the question
tokens = word_tokenize(question)
# Perform lemmatization on the tokens
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in tokens]
return lemmatized_tokens
# Define a function to extract the relevant information from the dataset
def extract_info(lemmatized_question, data):
if "total" in lemmatized_question and "revenue" in lemmatized_question:
total_revenue = data["revenue"].sum()
return total_revenue
# Process the user's question
question = "What was the total revenue for the company in 2020?"
lemmatized_question = process_question(question)
# Extract the relevant information from the dataset
total_revenue = extract_info(lemmatized_question, data)
# Print the result
print("Total revenue for the company in 2020: ", total_revenue)3. 異常検出
ChatGPT は、データ内の異常なパターンや外れ値を特定するのに役立ちます。 たとえば、マハラノビス距離法を使用してデータセット内の異常を検出するサンプル コードは次のようになります。
from pyod.models.mcd import MCD
import numpy as np
X = np.array(df[['Quantity', 'Price', 'Total']])
clf = MCD()
clf.fit(X)
anomalies = clf.predict(X)4. 予測モデリング
ChatGPT は、予測や分類などのタスクのための機械学習モデルのトレーニングと展開を支援できます。 たとえば、製品価格を予測するためにランダム フォレスト リグレッサーをトレーニングするためのサンプル コードは次のようになります。
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
X = df[['Quantity', 'Total']]
y = df['Price']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
rf = RandomForestRegressor(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
print("R2 score on test set: {:.2f}".format(rf.score(X_test, y_test)))5. データの視覚化
ChatGPT は、チャート、プロット、マップなどのさまざまな種類の視覚化を生成して、データをより理解しやすくするのに役立ちます。 たとえば、顧客 ID ごとの総収益の棒グラフを作成するサンプル コードは次のようになります。
import matplotlib.pyplot as plt
revenue_by_customer = df.groupby('Customer ID')['Total'].sum()
revenue_by_customer.plot(kind='bar')
plt.xlabel("Customer ID")
plt.ylabel("Total Revenue")
plt.show()RATH による拡張分析の自動化
従来の BI ソフトウェアに慣れていて、Augmented Analytics トレインに飛び乗りたいビジネス ユーザーにとって、RATH は究極のソリューションです。
RATH (opens in a new tab) は、拡張分析エンジンを使用してパターン、洞察、因果関係を発見することで探索的データ分析ワークフローを自動化し、これらの洞察を強力な自動生成された多次元データ視覚化で提示します。
RATH (opens in a new tab) はオープンソースです。 RATH GitHub にアクセスして、次世代の Auto-EDA (opens in a new tab) ツールを体験してください。 また、データ分析のプレイグラウンドとして RATH オンライン デモをチェックすることもできます。

機能は次のとおりです。
| 機能 | 説明 | プレビュー |
|---|---|---|
| AutoEda (opens in a new tab) | パターン、洞察、因果関係を発見するための拡張分析エンジン。 ワンクリックでデータ セットを探索し、データを視覚化する完全自動化された方法。 |  |
| データの可視化 (opens in a new tab) | 有効性スコアに基づいて多次元データの視覚化を作成します。 | 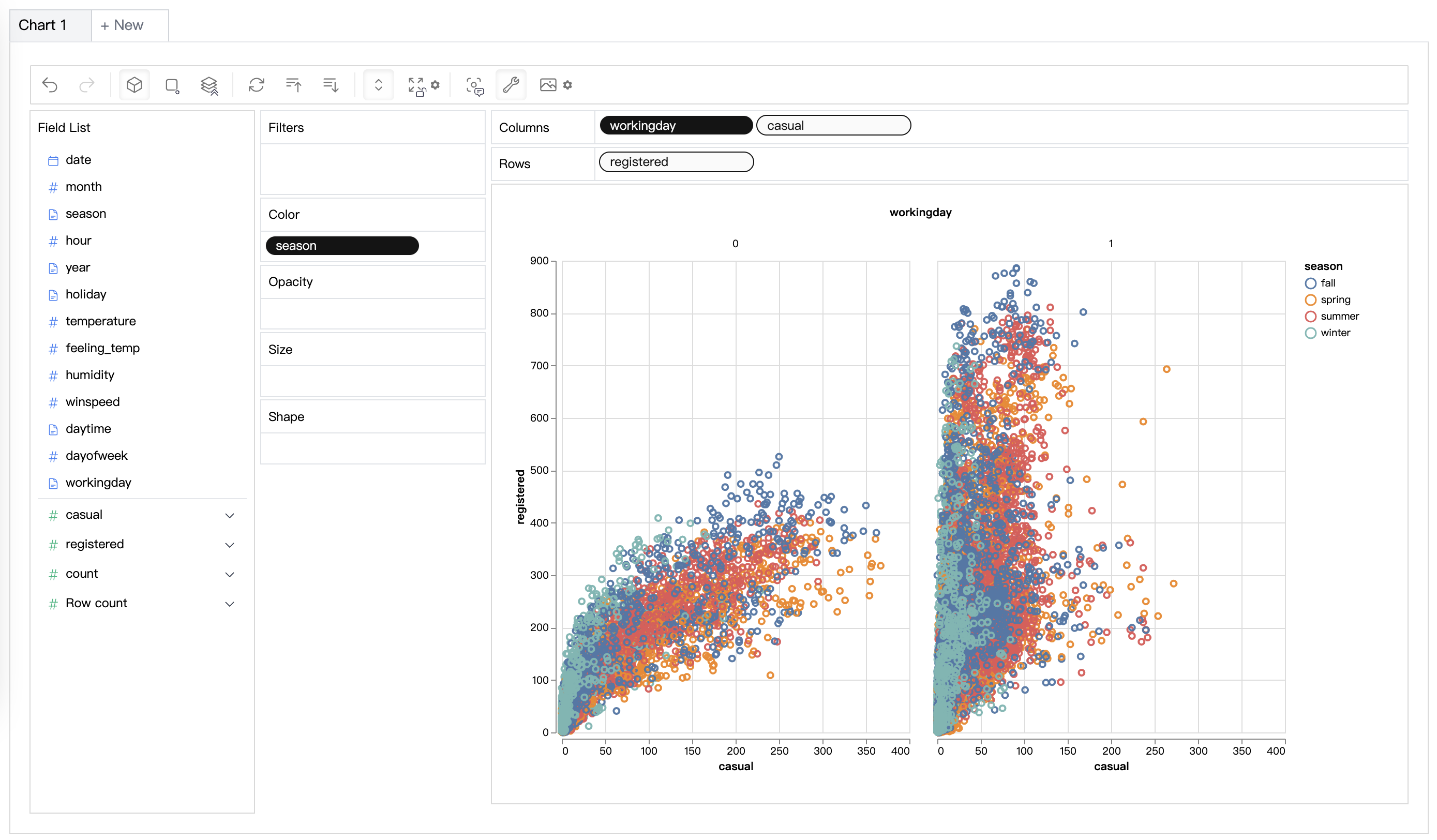 |
| Data Wrangler (opens in a new tab) | データとデータ変換の概要を生成するための自動化されたデータ ラングラー。 | 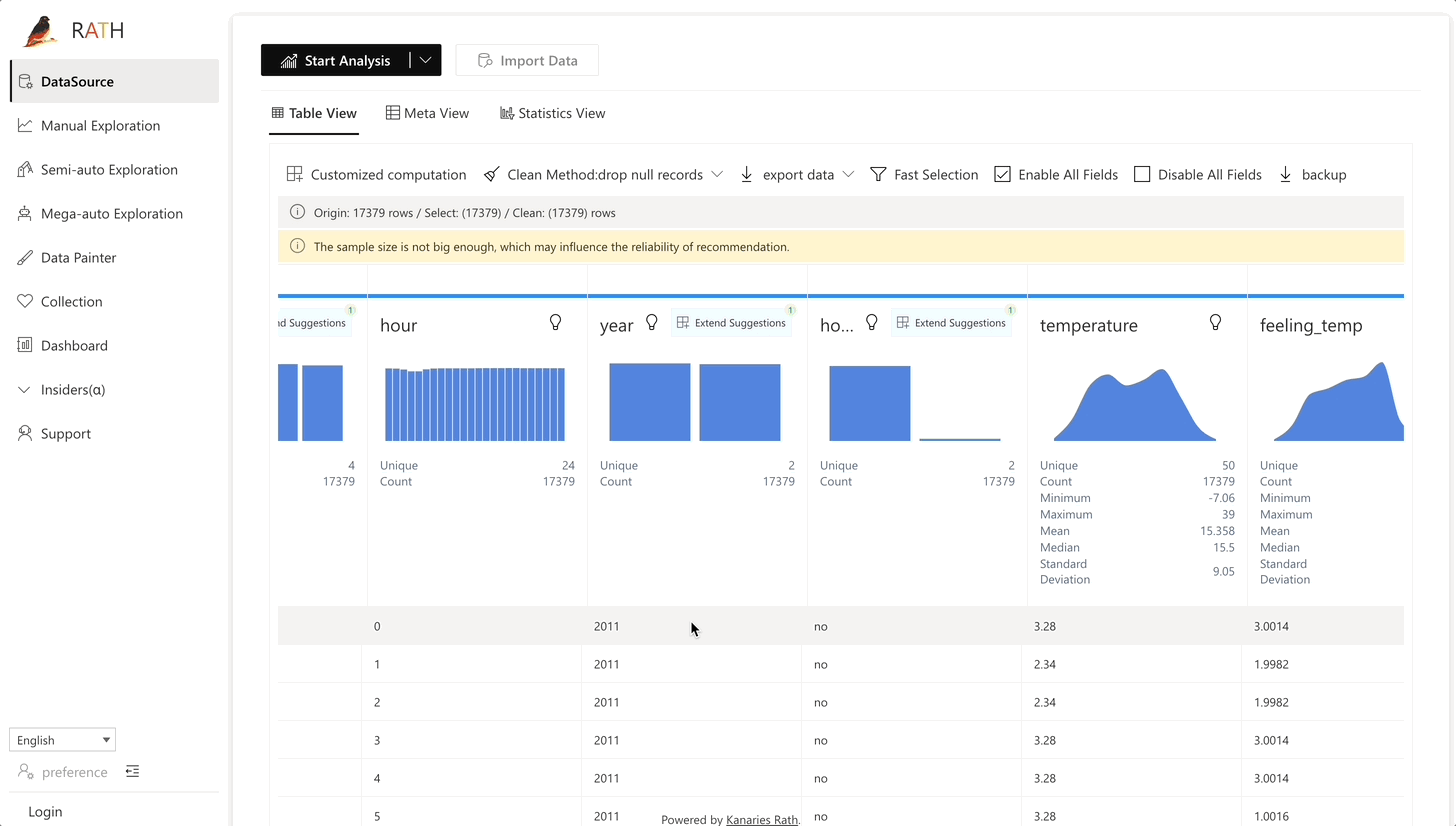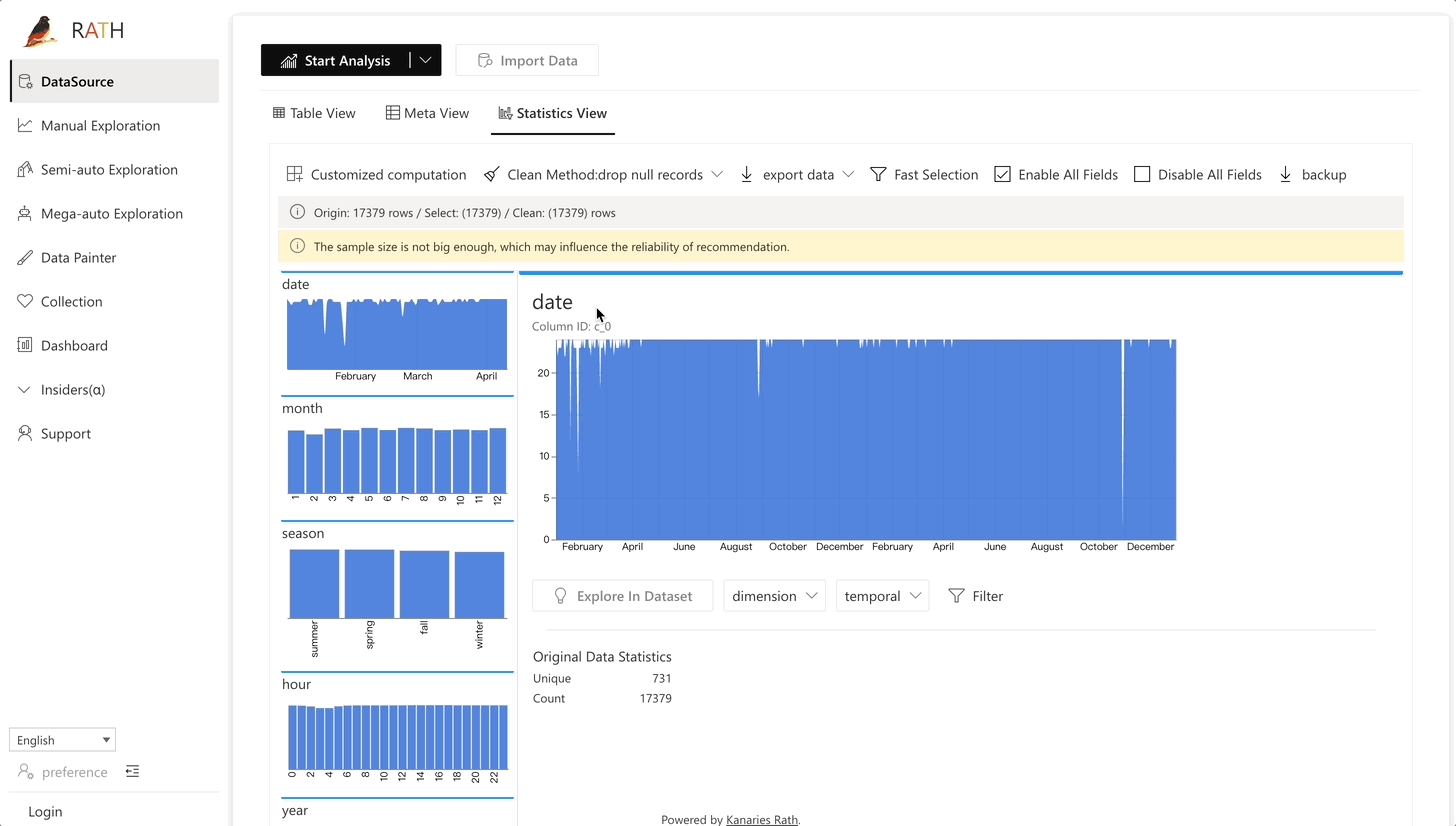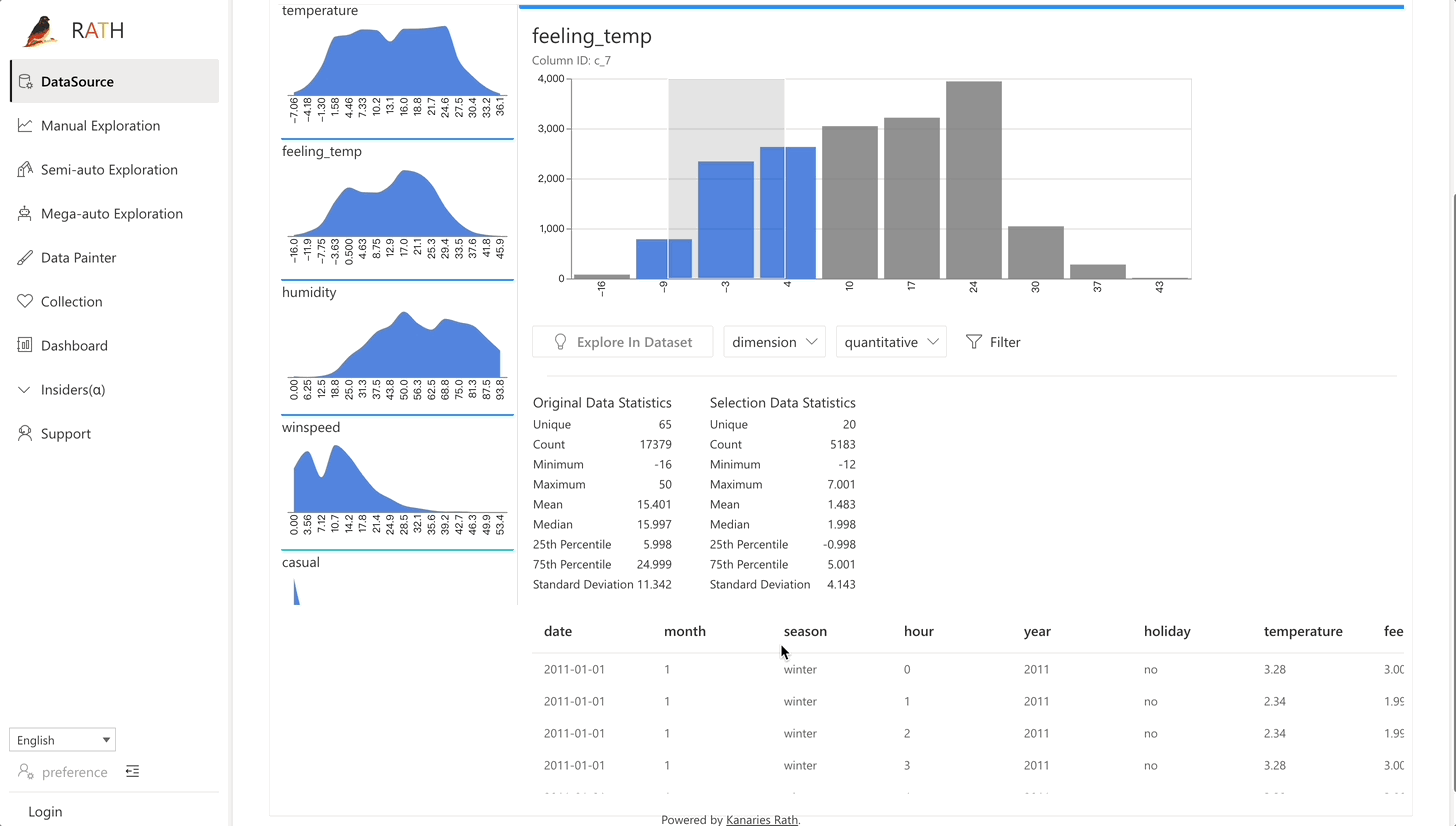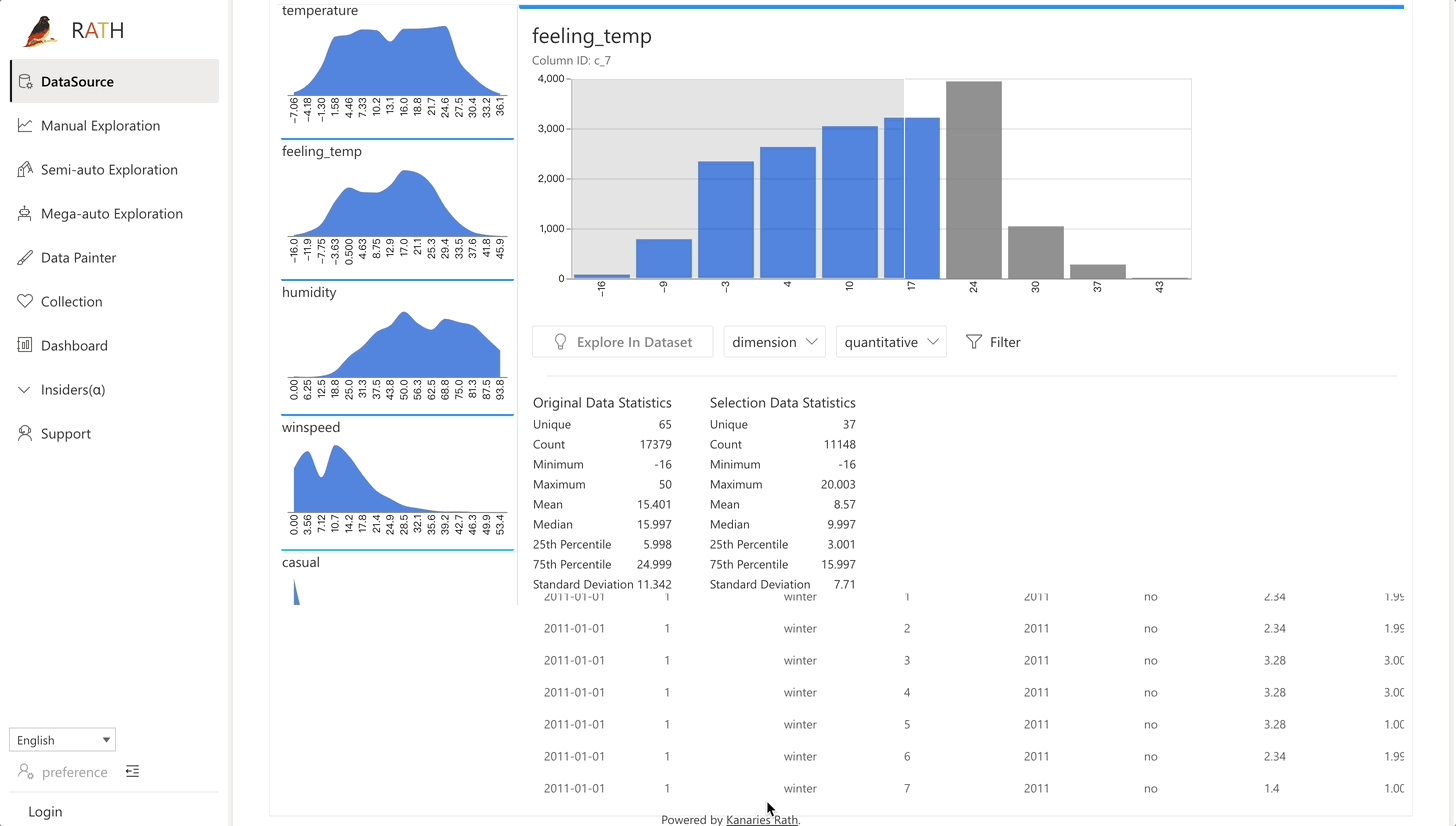 |
| データ探索コパイロット (opens in a new tab) | 自動データ探索と手動探索を組み合わせます。 RATH はデータ サイエンスの副操縦士として働き、あなたの興味を学習し、拡張分析エンジンを使用して関連する推奨事項を生成します。 | 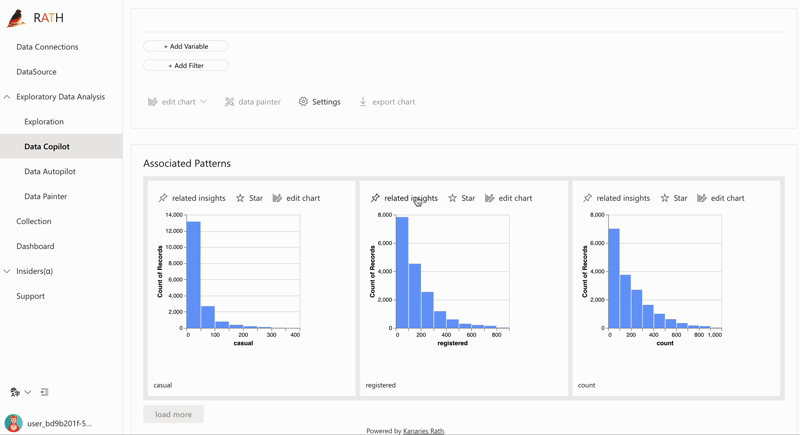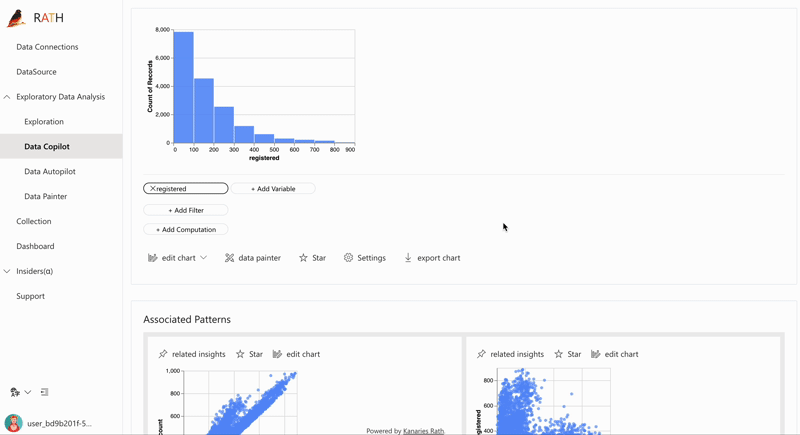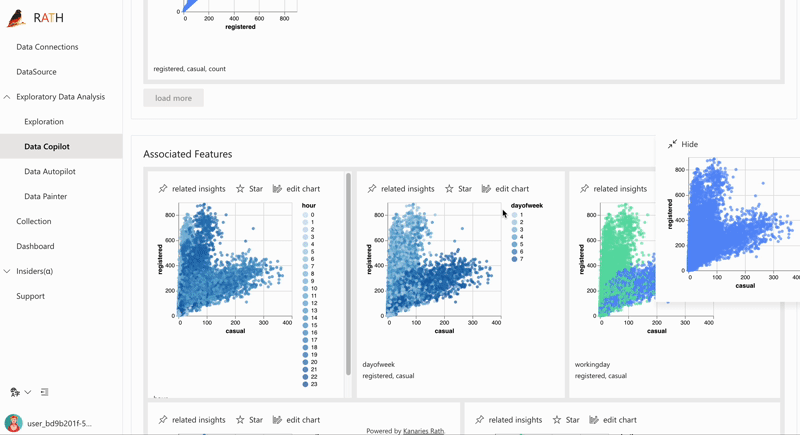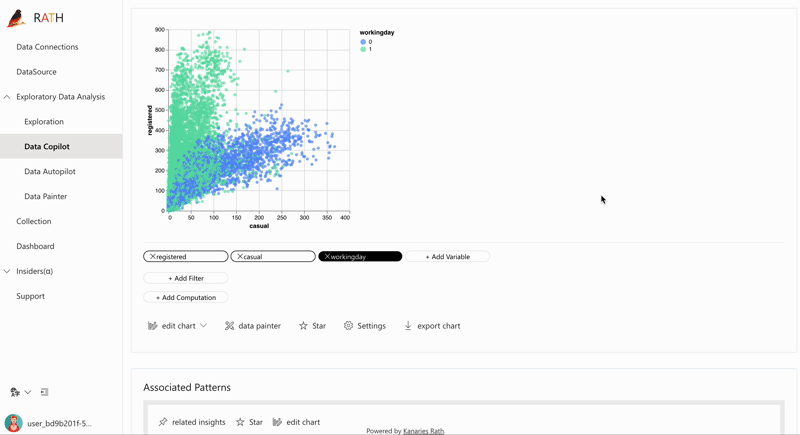 |
| Data Painter (opens in a new tab) | さらなる分析機能を使用して、データを直接色付けすることで探索的データ分析を行うためのインタラクティブで直感的かつ強力なツールです。 | 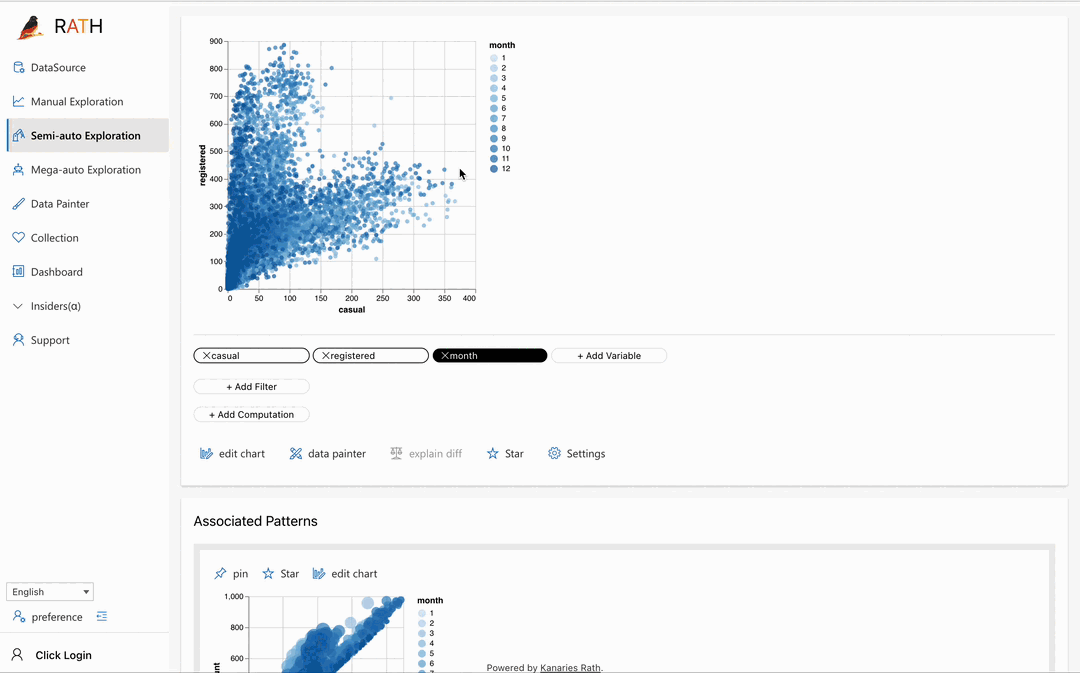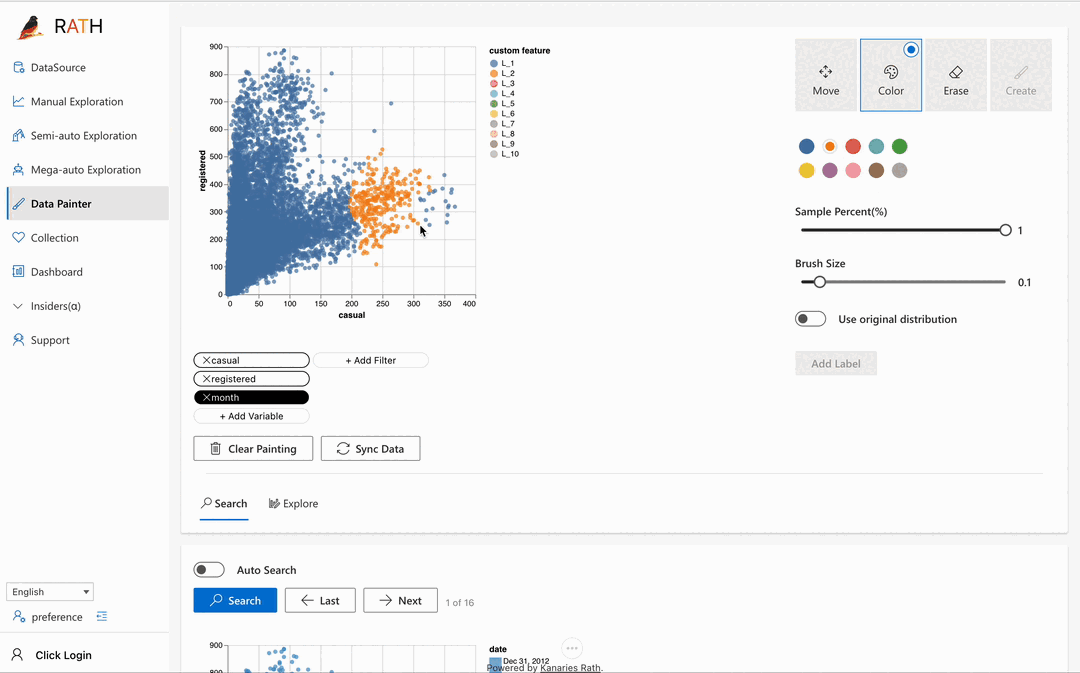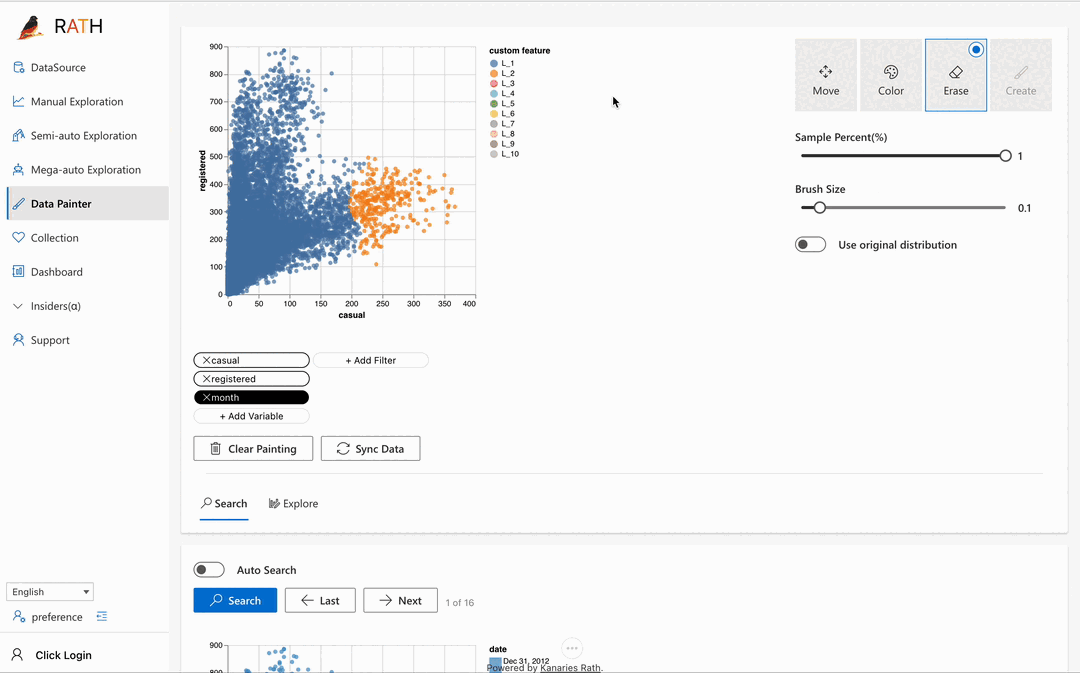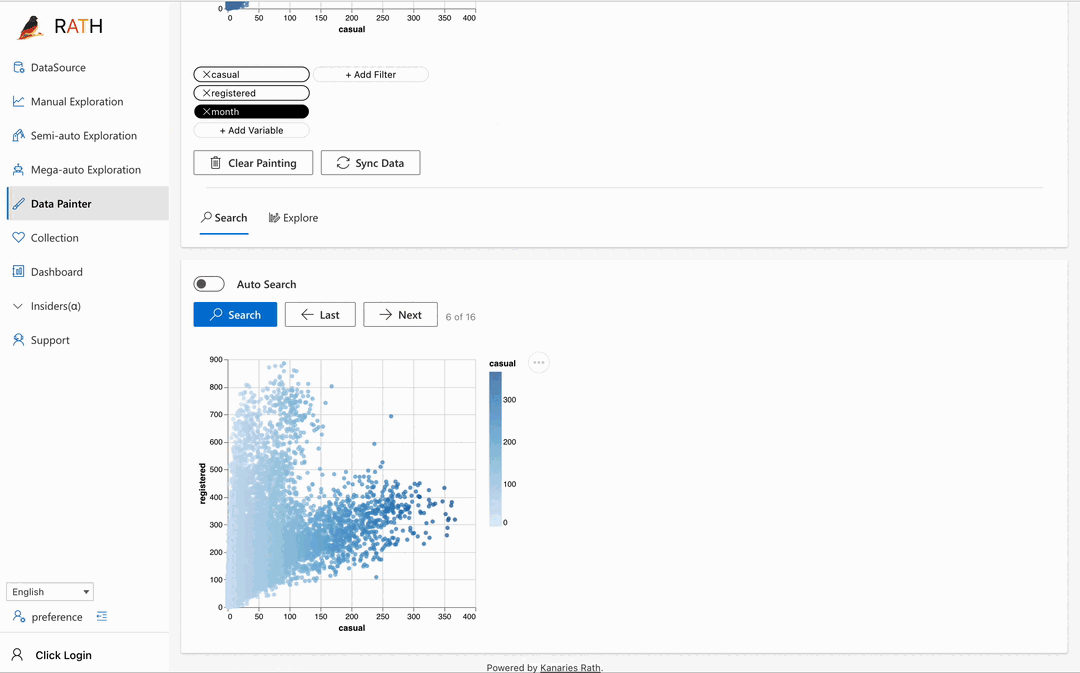 |
| ダッシュボード | 美しいインタラクティブなデータ ダッシュボードを構築します (ダッシュボードに提案を提供できる自動ダッシュボード デザイナーを含む)。 | 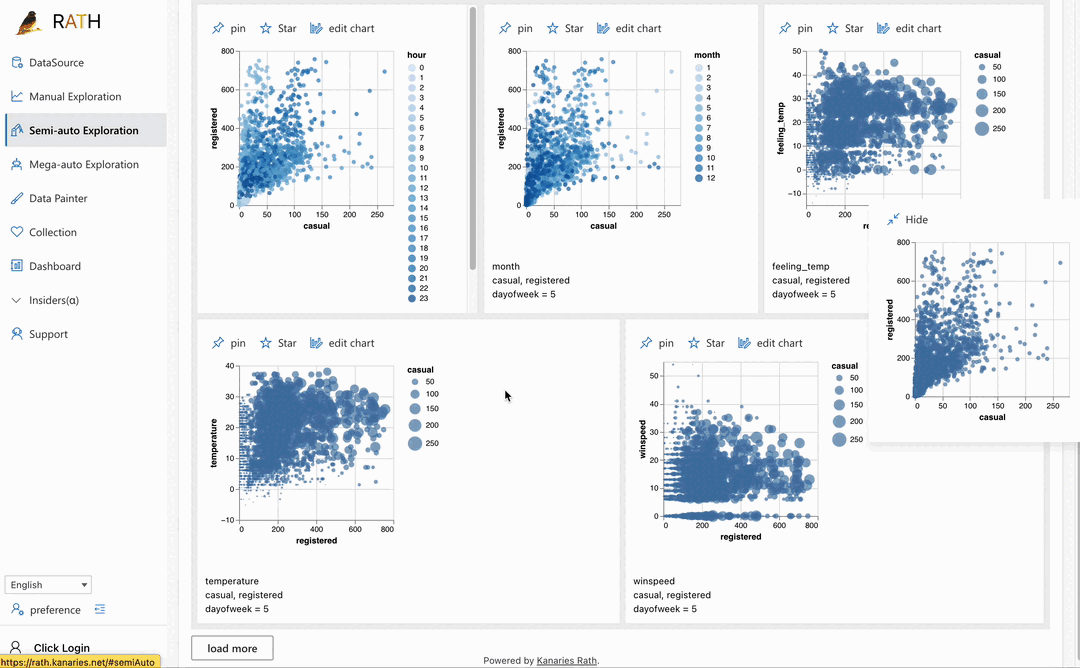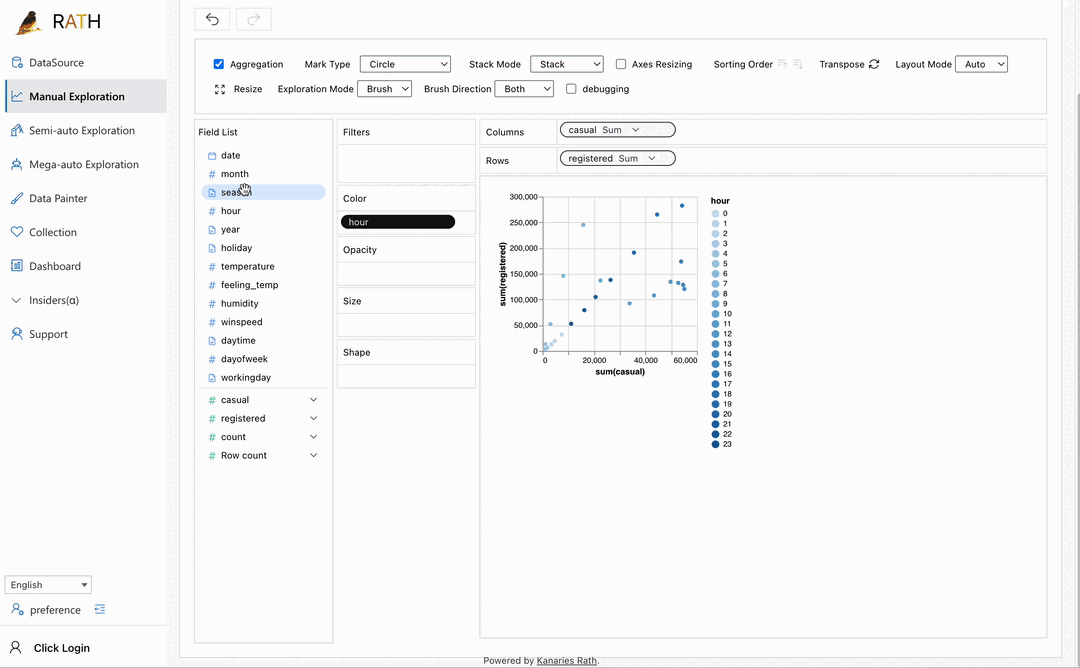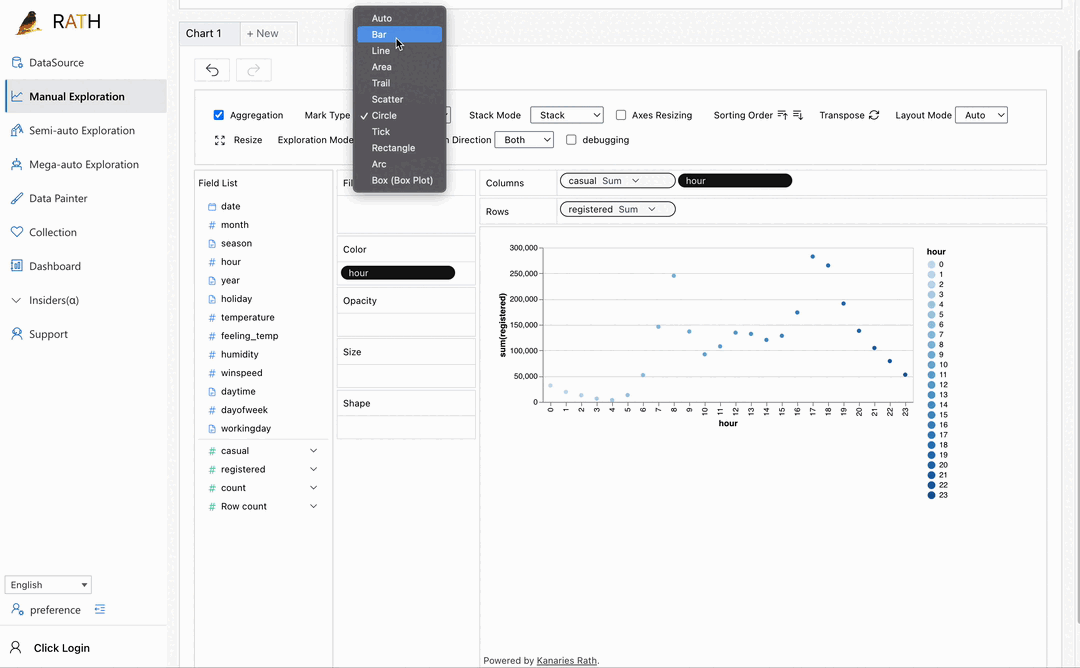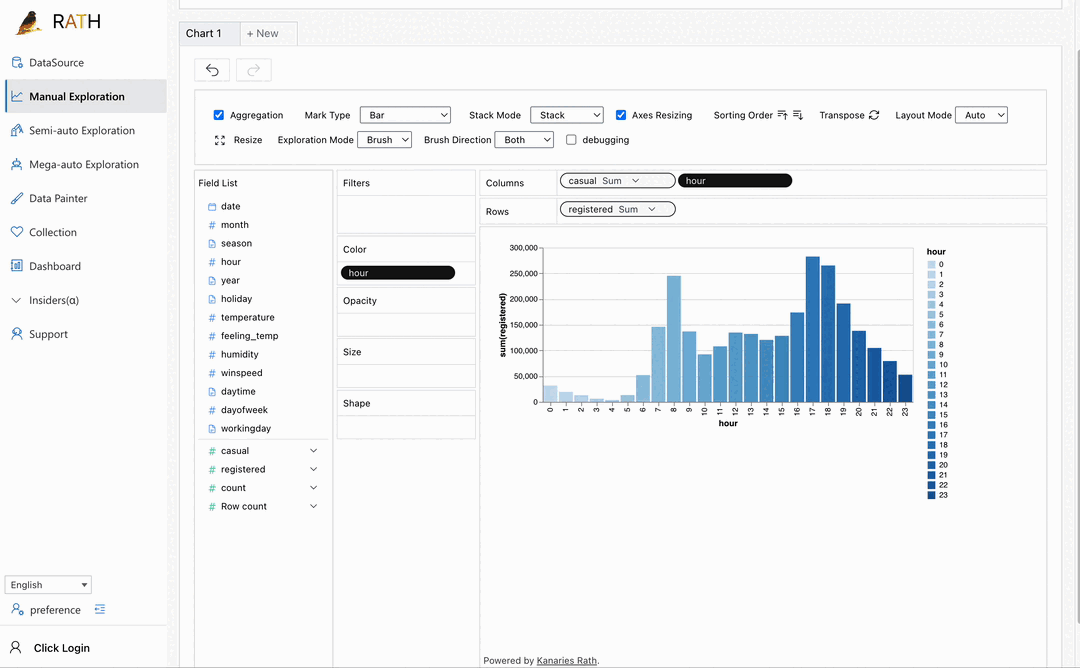 |
| 因果分析 (opens in a new tab) | 複雑な関係分析の因果関係の発見と説明を提供します。 | 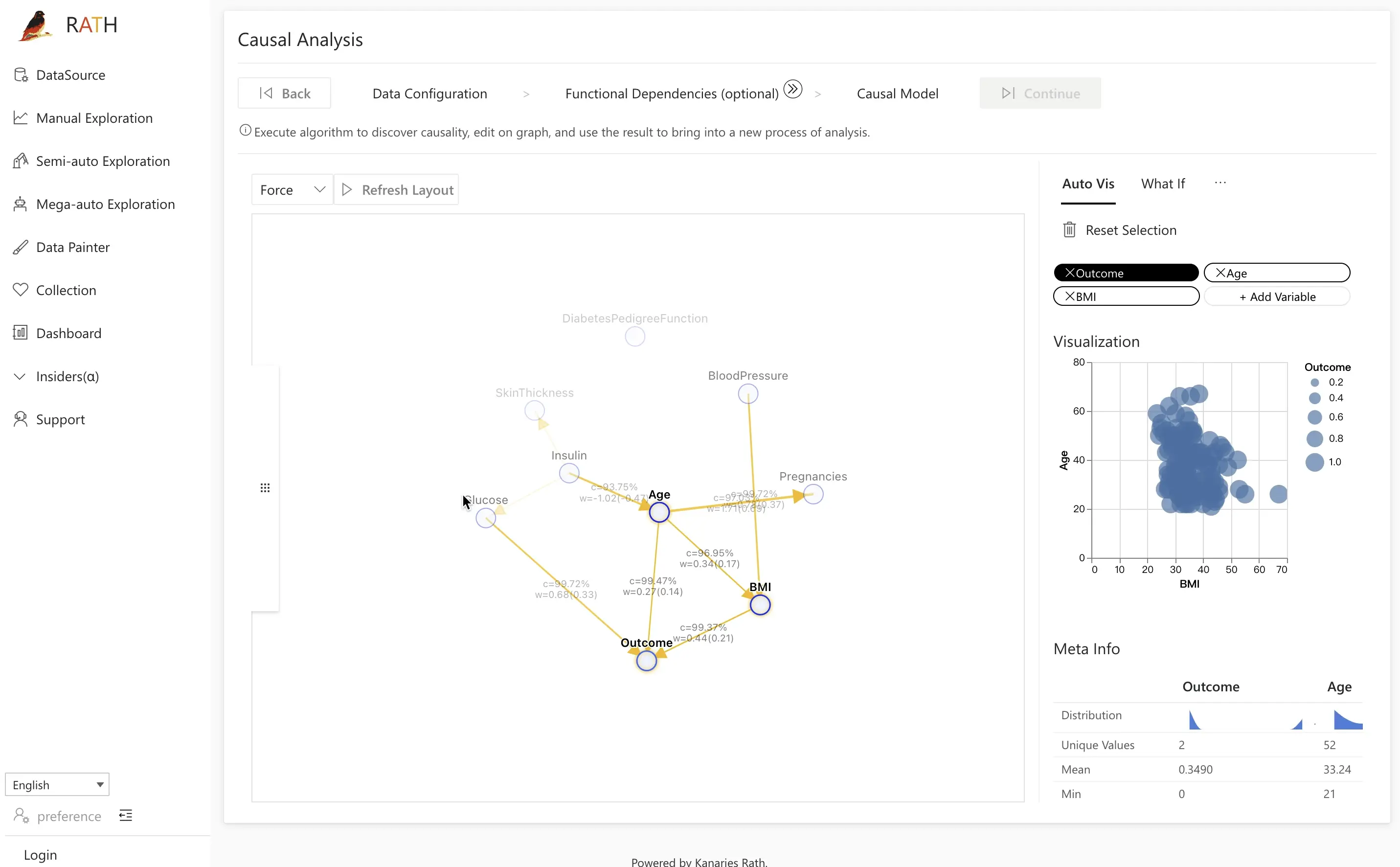 |
RATH は幅広いデータ ソースをサポートしています (opens in a new tab)。 RATH に接続できる主要なデータベース ソリューションの一部を以下に示します: MySQL、ClickHouse、Amazon Athena、Amazon Redshift、Apache Spark SQL、Apache Doris、Apache Hive、Apache Impala、Apache Kylin、Oracle、および PostgreSQL。
結論
結論として、拡張分析は、組織がデータを理解し、より良い意思決定を行うのに役立つ強力なツールです。 人工知能と機械学習の力を活用することで、拡張分析は、データ分析に関連する退屈で時間のかかるタスクの多くを自動化できます。 この記事で提供されているユース ケースとサンプル コードは、この分野における ChatGPT の機能を垣間見ることができます。 さらに、リアルタイムのデータ分析を可能にするフレームワークである RATH を ChatGPT と組み合わせて使用すると、さらに強力で効率的な洞察を得ることができます。