ChatGPT はデータ アナリストに取って代わることができますか? ChatGPT で複雑な SQL クエリを簡単に生成

序章
SQL (Structured Query Language) は、リレーショナル データベースのデータを管理および操作するために広く使用されているプログラミング言語です。 企業や組織は、データを保存、取得、分析する必要があります。 ただし、SQL クエリの作成は、特に複雑なクエリや大規模なデータベースの場合、時間がかかり、エラーが発生しやすい作業になる可能性があります。
この記事では、OpenAI によって開発された大規模な言語モデルである ChatGPT が効率的な SQL クエリを生成する機能について説明します。 ChatGPT が複雑なクエリをすばやく生成し、高い精度と再現率でデータをフィルタリングし、既存のクエリを最適化する方法を示します。
サンプル データベースを生成する
わかりやすくするために、例として次のサンプル データベースを用意しています。
表 1: 本
このテーブルには、タイトル、著者、出版社、ISBN など、書店にあるすべての書籍に関する情報が含まれます。
CREATE TABLE books (
book_id INT PRIMARY KEY,
title VARCHAR(255),
author VARCHAR(255),
publisher VARCHAR(255),
isbn VARCHAR(13)
);表 2: 顧客 このテーブルには、書店に登録した顧客に関する情報 (名前、電子メール アドレス、電話番号など) が格納されます。
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255),
phone VARCHAR(20)
);表 3: 注文
このテーブルには、注文した顧客、注文した本、注文日、注文ステータスなど、顧客が行ったすべての注文に関する情報が格納されます。
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
book_id INT,
order_date DATE,
status VARCHAR(20),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id),
FOREIGN KEY (book_id) REFERENCES books(book_id)
);表 4: 在庫
このテーブルは、ストア内の各書籍の現在の在庫レベルを追跡します。
CREATE TABLE inventory (
book_id INT PRIMARY KEY,
quantity INT,
FOREIGN KEY (book_id) REFERENCES books(book_id)
);これらは、書店データベースを使い始めるために必要な基本的なテーブルです。 特定のニーズに応じて、追加のテーブルまたは列をこれらのテーブルに追加することができます。
データ集約のための ChatGPT プロンプト
データベースを操作する際の最も一般的なタスクの 1 つは、データの集計です。 特定の条件に基づいてデータを要約することを指します。 たとえば、特定の製品カテゴリの総売上や、特定の部門の従業員の平均給与を計算します。 集計クエリは、記述するのが複雑になる可能性があり、人間にとってはかなりの時間がかかる場合があります。
ただし、ChatGPT はこれらのクエリを迅速かつ正確に生成できます。 データの構造と目的の出力を理解し、最小限の労力で必要な情報を取得できる効率的なクエリを生成できます。 これにより、エラーのリスクが軽減され、ユーザーの時間が節約されます。
次のプロモーションを使用して ChatGPT によって生成されたデータ集計クエリの例を次に示します。
"Find the top 5 bestselling books in the last quarter, along with their authors and total sales revenue." (「前四半期のベストセラー本トップ 5 を、その著者と総売上高とともに検索します。」)
この集計を実行するには、書籍、注文、および在庫テーブルを結合し、結果を書籍および著者別にグループ化し、前四半期の注文でフィルター処理し、各書籍の総売上高を計算する必要があります。 最後に、結果を収益で並べ替え、出力を上位 5 冊に制限する必要があります。
ChatGPT は、これを実現するために次の SQL コードを生成します。
SELECT books.title, books.author, SUM(inventory.quantity * orders.price) AS revenue
FROM books
JOIN inventory ON books.book_id = inventory.book_id
JOIN orders ON inventory.book_id = orders.book_id
WHERE orders.order_date >= DATEADD(QUARTER, -1, GETDATE())
GROUP BY books.title, books.author
ORDER BY revenue DESC
LIMIT 5;データフィルタリング
データベースを操作する際のもう 1 つの重要なタスクは、データ フィルタリングです。 これは、特定の基準に基づいてデータベースから特定のデータを抽出することを指します。 たとえば、特定の場所で顧客が行ったすべての取引や、会社に 5 年以上勤務しているすべての従業員を抽出します。 クエリのフィルタリングは、作成が複雑になる可能性があり、人間にとってはかなりの時間がかかる場合があります。
ChatGPT は、これらのクエリを高い精度と再現率で生成できます。 データの構造と目的の出力を理解し、最も関連性の高いデータを取得できるクエリを生成できます。 これにより、分析と意思決定のためのより正確なデータが得られます。 この ChatGPT プロンプトを使用して生成されたデータ フィルタリング クエリの例を次に示します。
"Find all the books published by 'Penguin Random House' and currently in stock, sorted by author name in ascending order." (「「ペンギン ランダム ハウス」が発行し、現在在庫のあるすべての書籍を、著者名の昇順に並べ替えて検索します。」)
このフィルタリングを実行するには、本と在庫テーブルを結合し、「ペンギン ランダム ハウス」が発行した本でフィルタリングし、現在在庫のある本のみを選択する必要があります。 最後に、著者名の昇順で結果を並べ替える必要があります。
ChatGPT は、この要件を満たすために次の SQL コードを生成します。
SELECT books.title, books.author, books.publisher, inventory.quantity
FROM books
JOIN inventory ON books.book_id = inventory.book_id
WHERE books.publisher = 'Penguin Random House' AND inventory.quantity > 0
ORDER BY books.author ASC;クエリの最適化
新しい SQL クエリを生成するだけでなく、ChatGPT は既存のクエリの最適化にも役立ちます。 クエリの構造とパフォーマンスを分析することにより、ChatGPT は、クエリをより高速かつ効率的に実行できる改善を提案できます。 たとえば、ChatGPT は、データベースの機能を活用するために、インデックスの使用やクエリの書き換えを提案できます。
クエリの最適化は、特に大規模で複雑なデータベースの場合、人間にとって難しい作業になる可能性があります。 ChatGPT はこのタスクを簡素化し、データベースのパフォーマンスを向上させるのに役立ちます。 この ChatGPT プロンプトを使用して生成されたクエリ最適化の例を次に示します。
"Find the top 10 customers who have spent the most on books in the last year, along with their total spending and average spending per order." ("過去 1 年間に書籍に最も多く支出した上位 10 人の顧客を、その合計支出額と注文ごとの平均支出額とともに見つけます。")
このクエリを最適化するには、結果を生成するためにデータベースが実行する必要がある操作の数を最小限に抑える必要があります。 以下に、検討できる最適化手法をいくつか示します。
-
インデックスを使用する: customers テーブルと orders テーブルの関連する列にインデックスを追加して、結合とフィルタリング操作を高速化します。
-
結合前の集計: 顧客テーブルと注文テーブルを結合してから結果を集計する代わりに、最初に注文テーブルを顧客ごとに集計してから、結果のテーブルを顧客テーブルと結合できます。
-
サブクエリを使用する: 顧客テーブルと注文テーブルを直接結合する代わりに、サブクエリを使用して注文テーブルを日付範囲でフィルター処理し、各顧客の注文ごとの合計支出と平均支出を計算できます。
ChatGPT によって生成されたこれらの最適化を実装する SQL クエリの例を次に示します。
SELECT customers.name,
total_spending,
total_spending / order_count AS avg_spending_per_order
FROM (
SELECT customer_id,
SUM(price * quantity) AS total_spending,
COUNT(*) AS order_count
FROM orders
WHERE order_date >= DATEADD(YEAR, -1, GETDATE())
GROUP BY customer_id
) AS order_totals
JOIN customers ON order_totals.customer_id = customers.customer_id
ORDER BY total_spending DESC
LIMIT 10;別の自動データ分析オプション: RATH
効率的な SQL クエリを生成する ChatGPT の機能に加えて、RATH (opens in a new tab) もあります。これは、Tableau などのデータ分析および視覚化ツールに代わるオープンソースのツールです。 RATH は、Exploratory Data Analysis (EDA) ワークフローを拡張分析エンジンで自動化することにより、データ分析を次のレベルに引き上げます。
RATH は幅広いデータ ソースをサポートしています (opens in a new tab)。 RATH に接続できる主要なデータベース ソリューションの一部を以下に示します: MySQL、ClickHouse、Amazon Athena、Amazon Redshift、Apache Spark SQL、Apache Doris、Apache Hive、Apache Impala、Apache Kylin、Oracle、および PostgreSQL。
RATH (opens in a new tab) はオープンソースです。 RATH GitHub にアクセスして、次世代の Auto-EDA (opens in a new tab) ツールを体験してください。 また、データ分析のプレイグラウンドとして RATH オンライン デモをチェックすることもできます。

主な RATH 機能は次のとおりです。
| 機能 | 説明 | プレビュー |
|---|---|---|
| AutoEda (opens in a new tab) | パターン、洞察、因果関係を発見するための拡張分析エンジン。 ワンクリックでデータ セットを探索し、データを視覚化する完全自動化された方法。 | 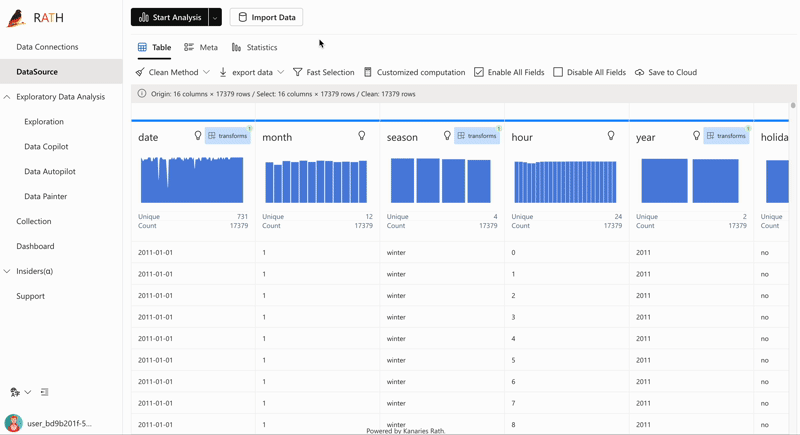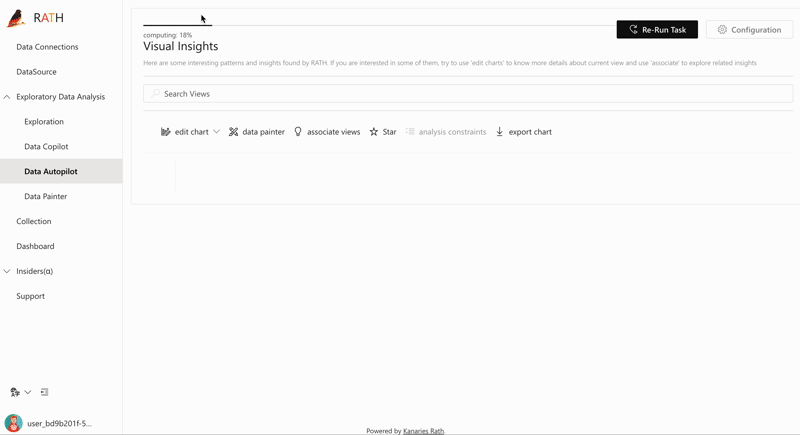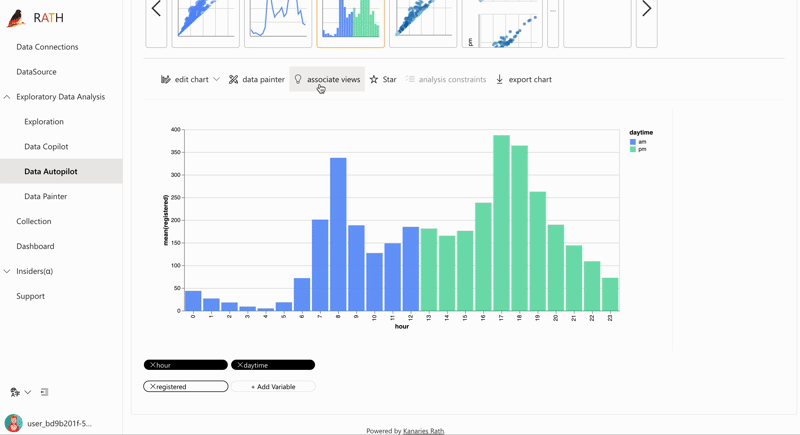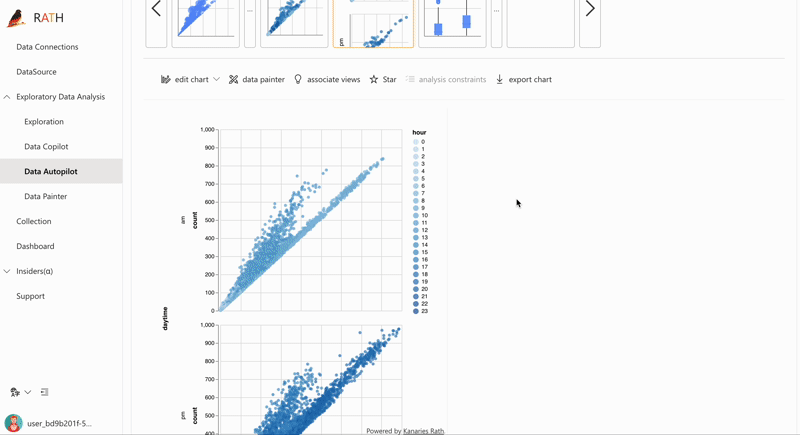 |
| データの可視化 (opens in a new tab) | 有効性スコアに基づいて多次元データの視覚化を作成します。 | 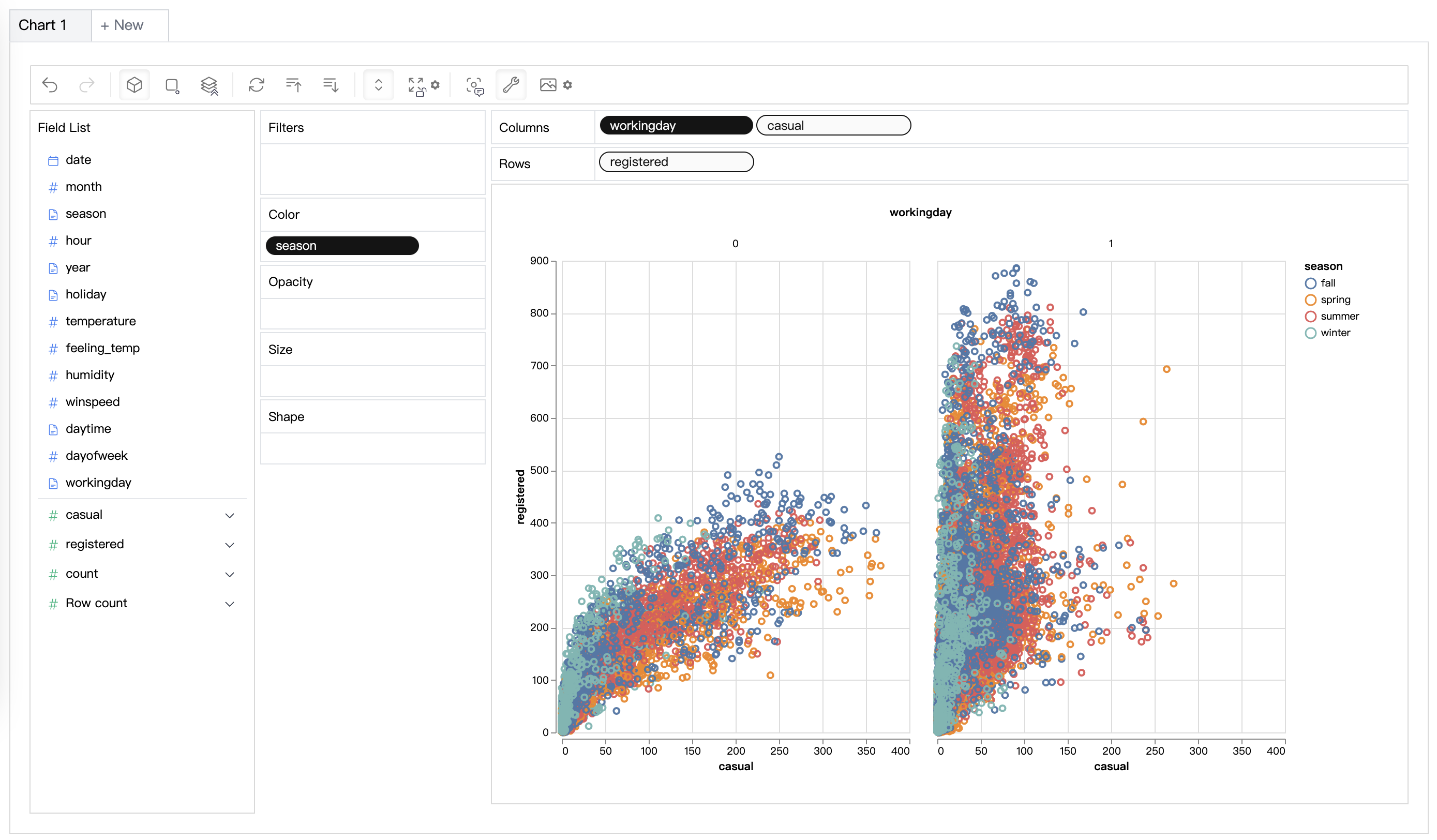 |
| Data Wrangler (opens in a new tab) | データとデータ変換の概要を生成するための自動化されたデータ ラングラー。 | 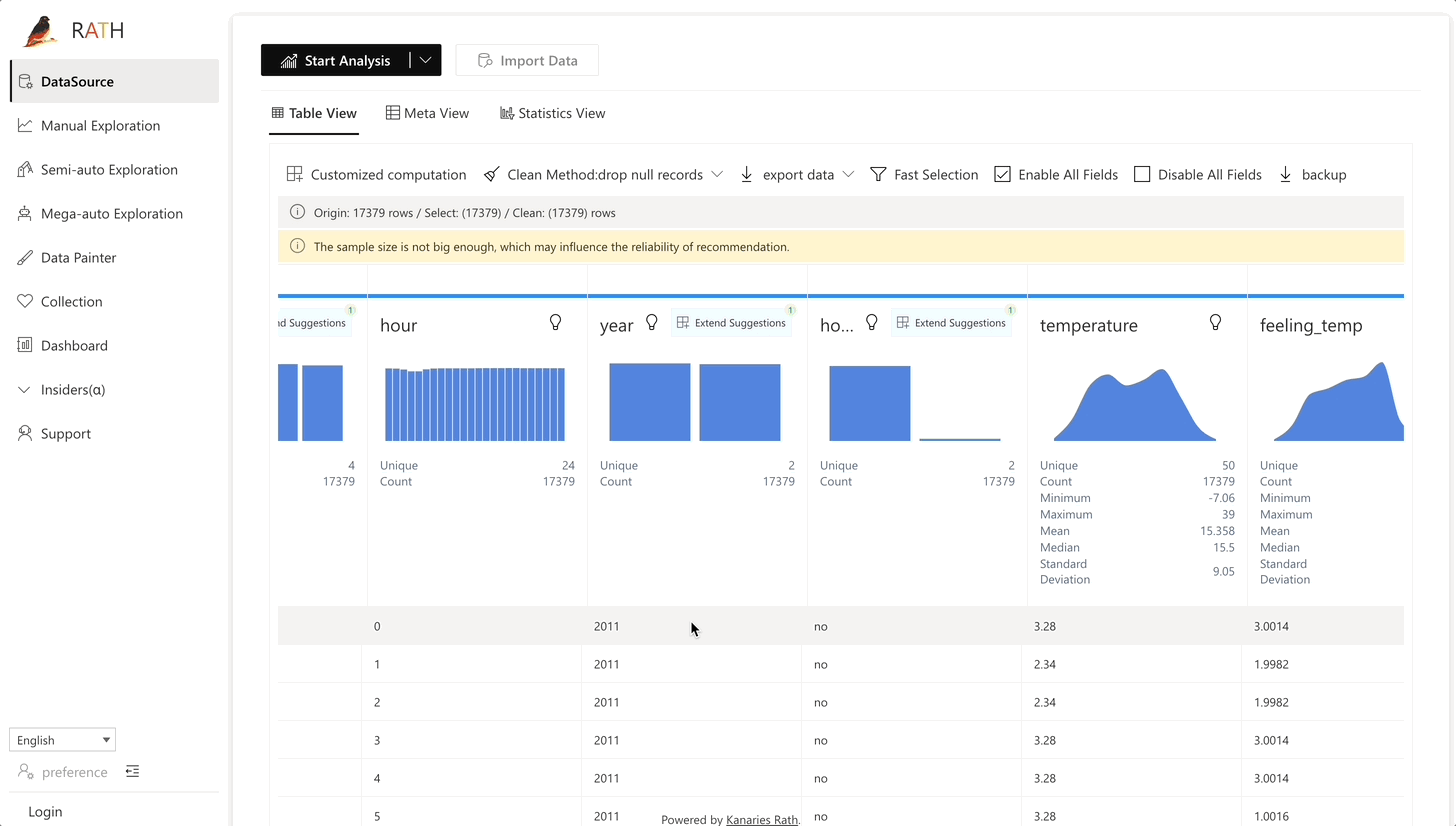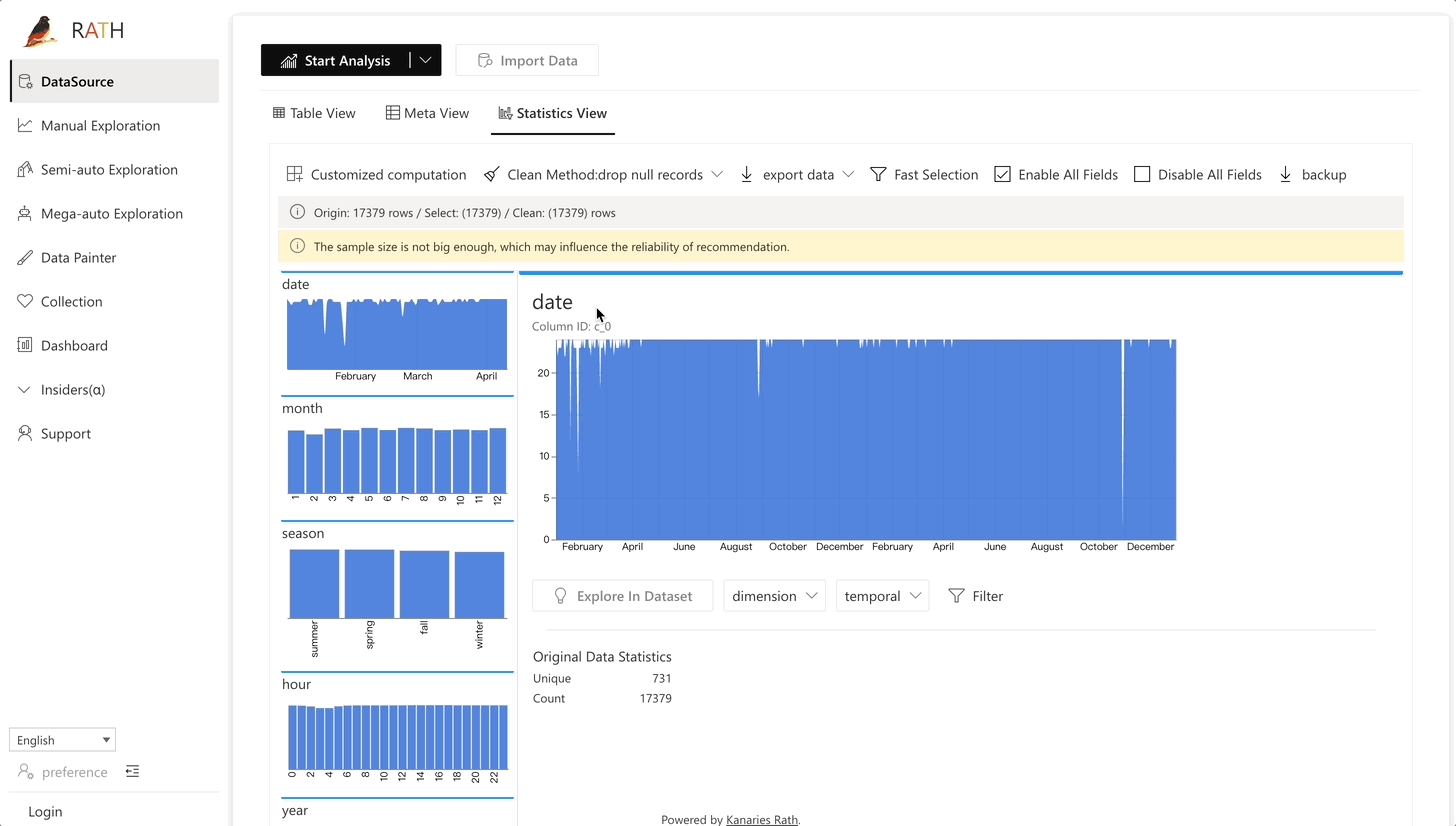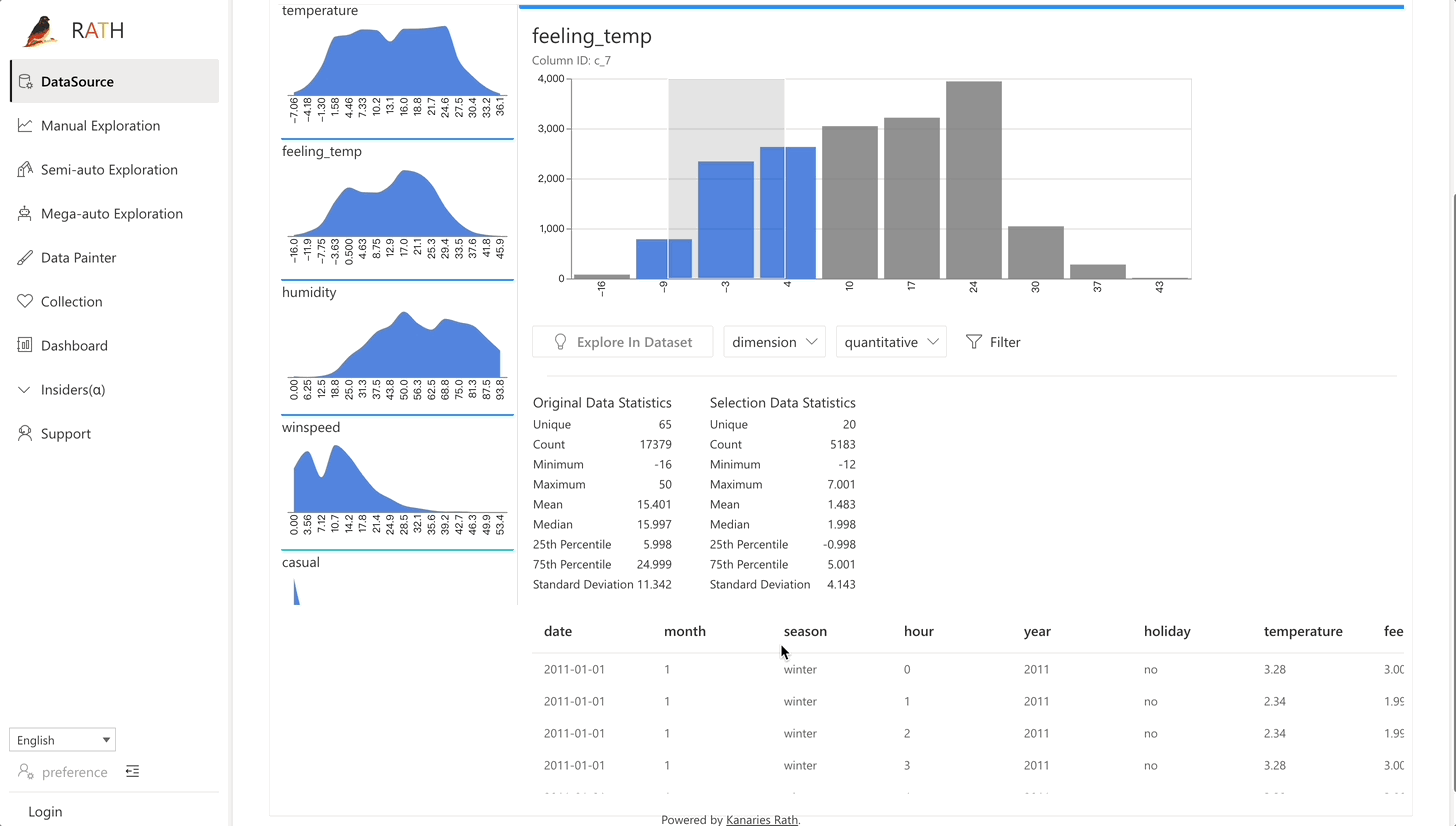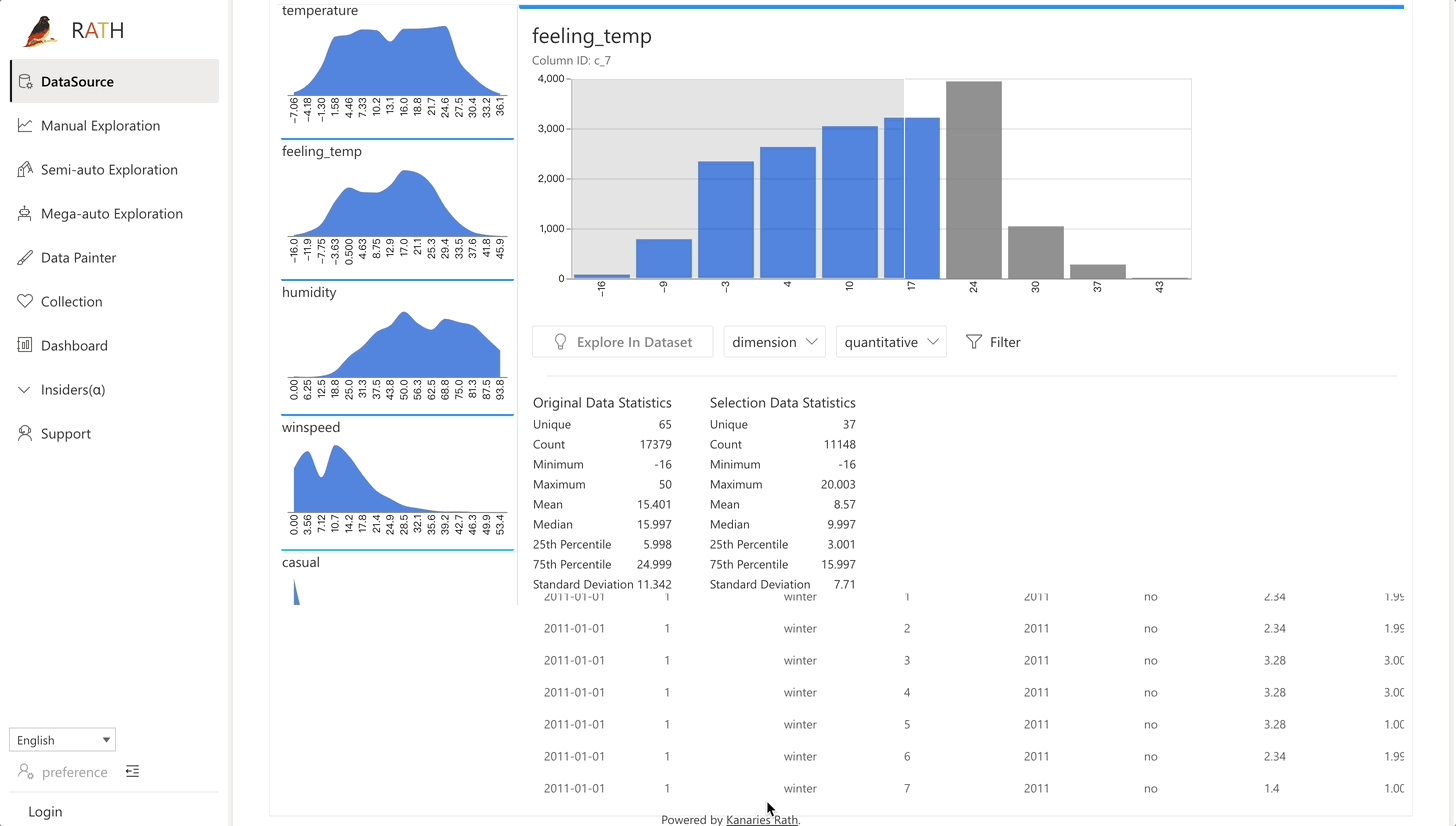 |
| データ探索コパイロット (opens in a new tab) | 自動データ探索と手動探索を組み合わせます。 RATH はデータ サイエンスの副操縦士として働き、あなたの興味を学習し、拡張分析エンジンを使用して関連する推奨事項を生成します。 | 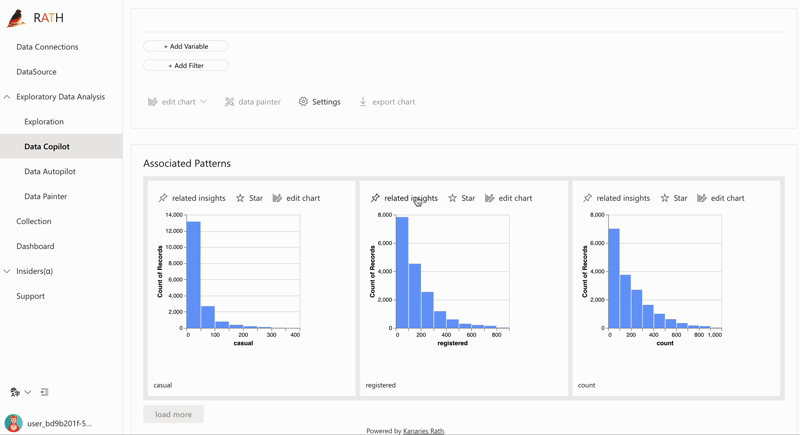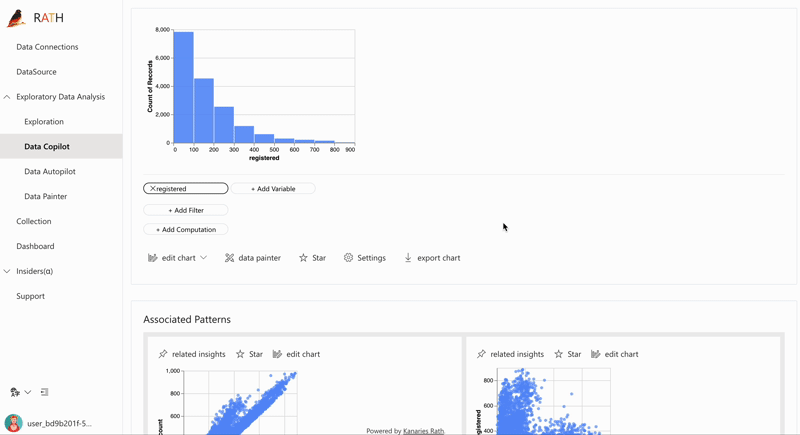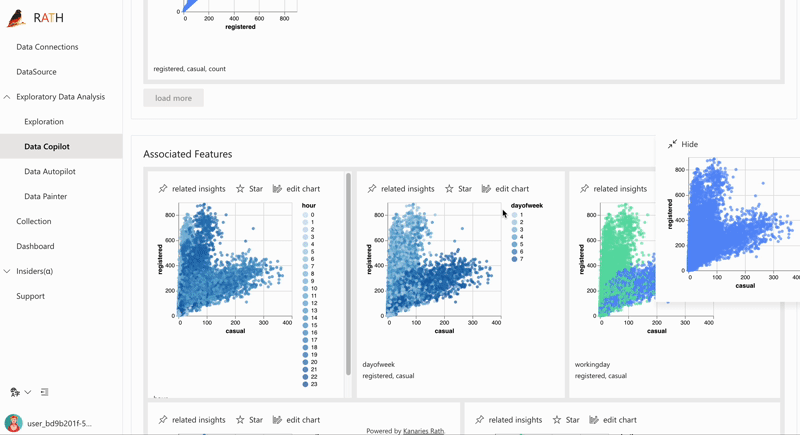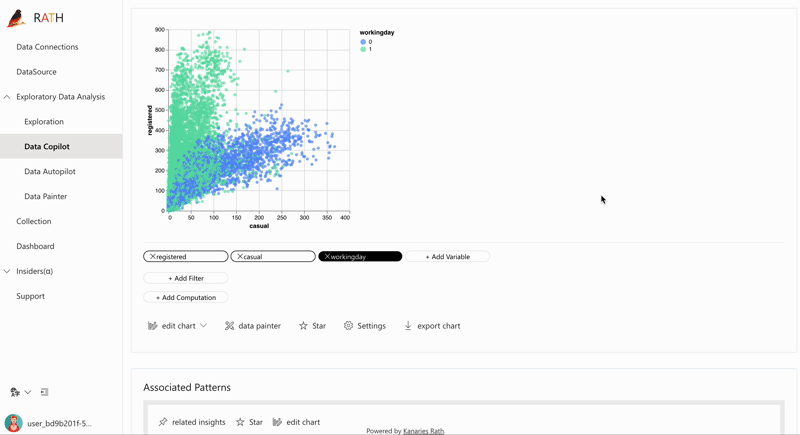 |
| Data Painter (opens in a new tab) | さらなる分析機能を使用して、データを直接色付けすることで探索的データ分析を行うためのインタラクティブで直感的かつ強力なツールです。 | 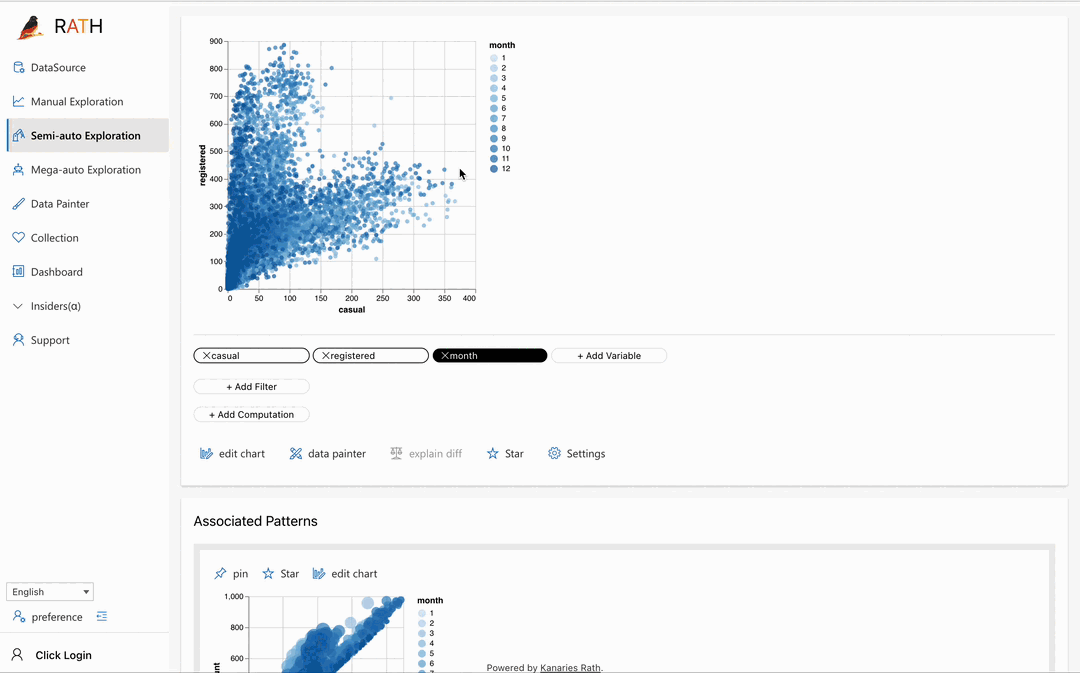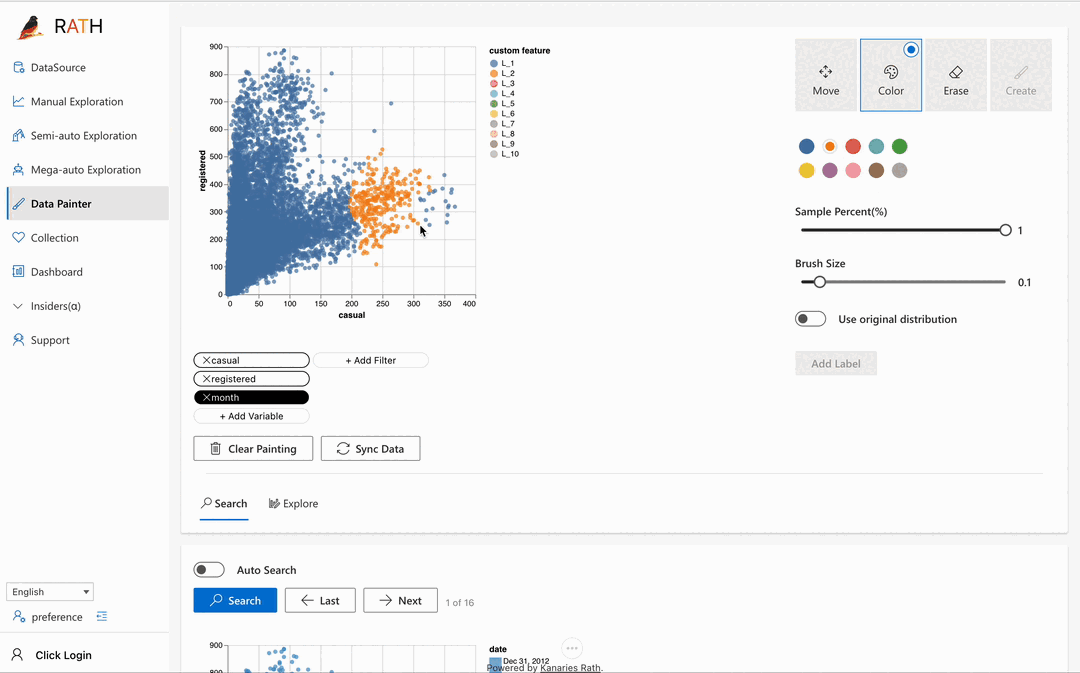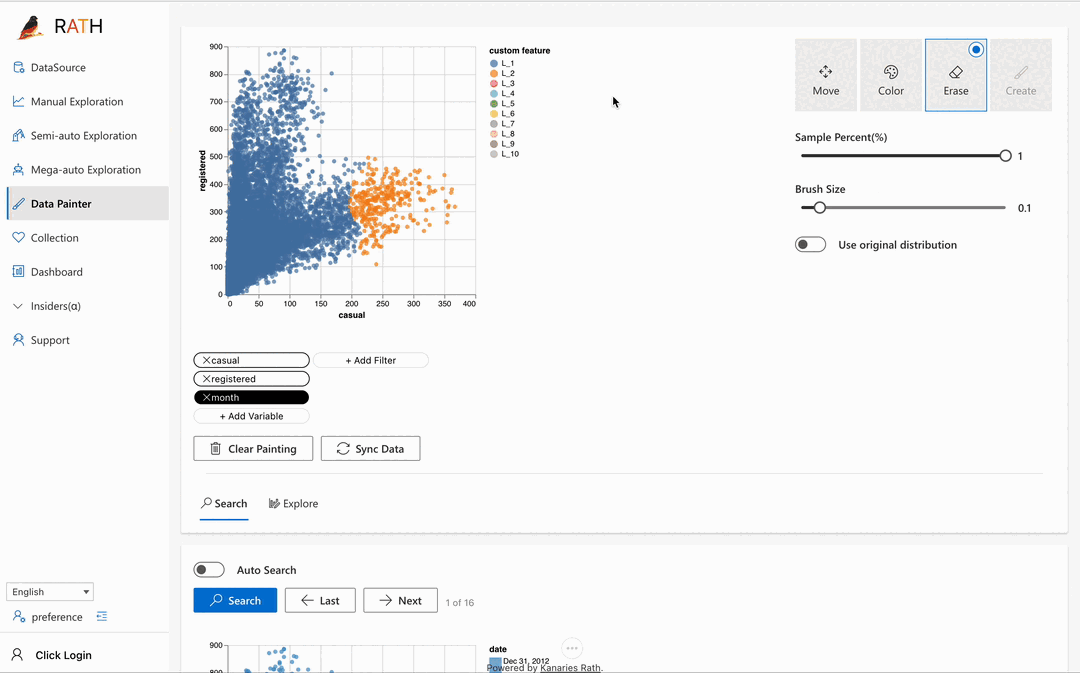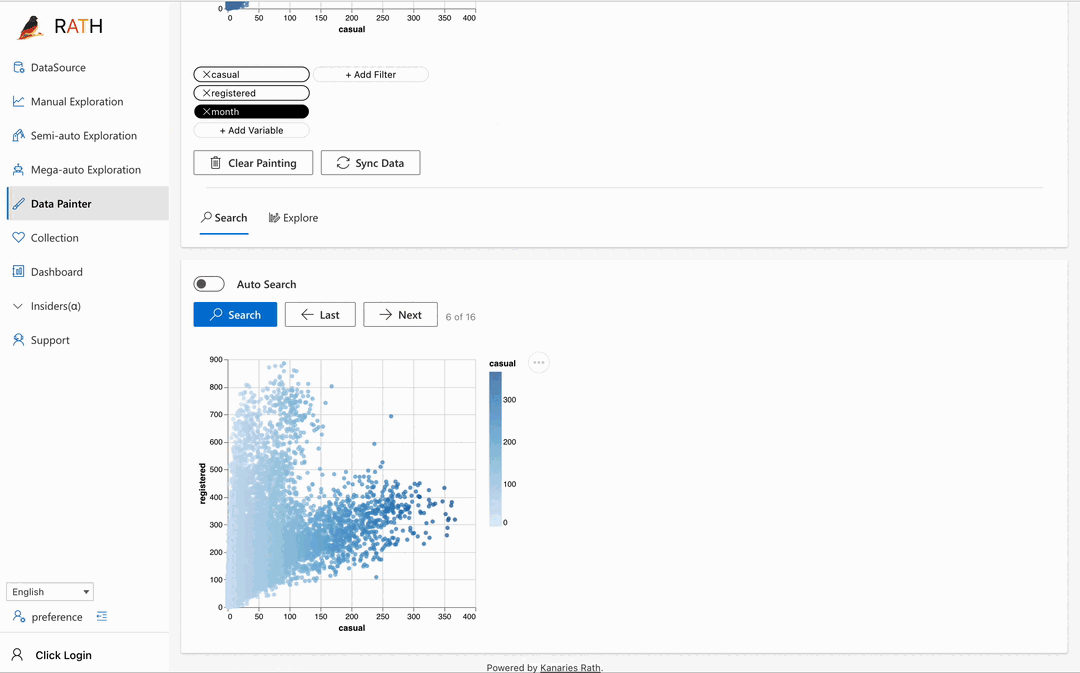 |
| ダッシュボード | 美しいインタラクティブなデータ ダッシュボードを構築します (ダッシュボードに提案を提供できる自動ダッシュボード デザイナーを含む)。 | 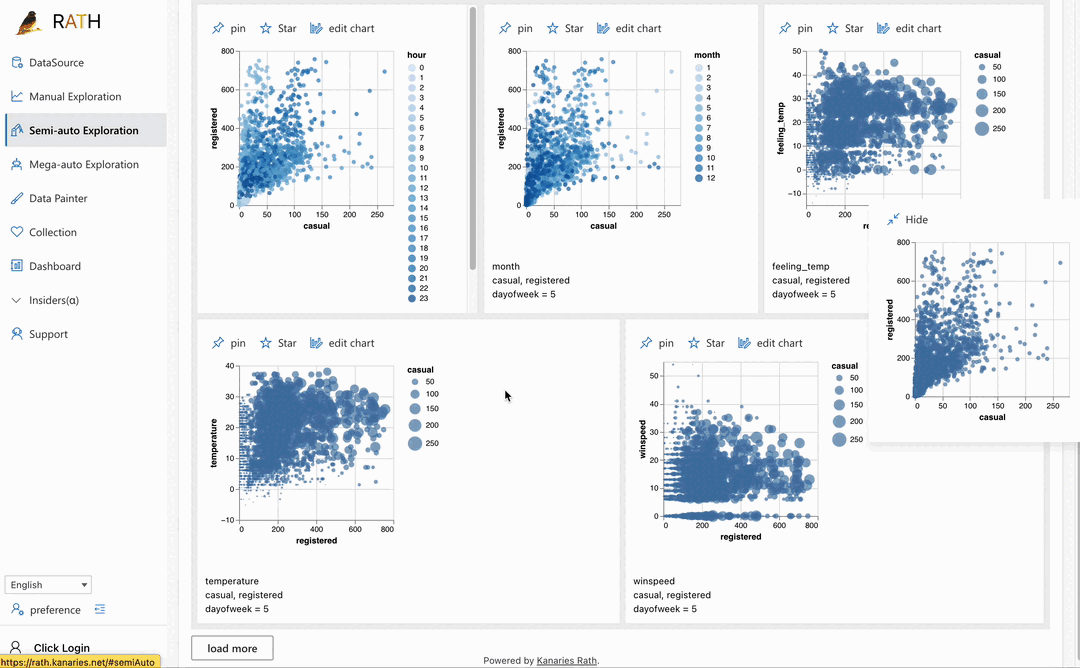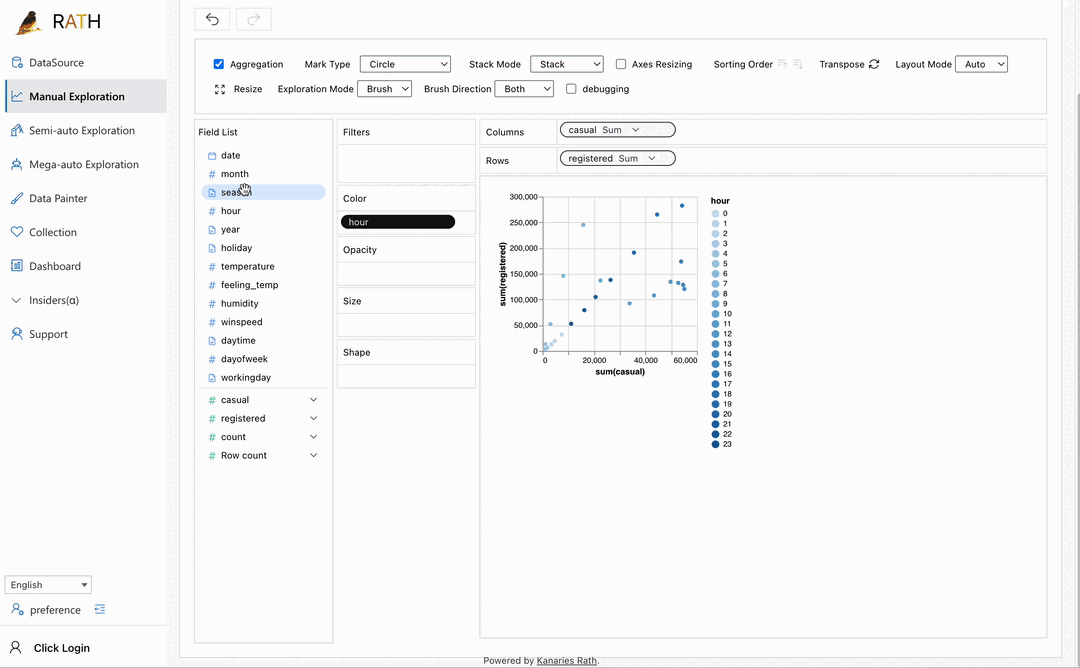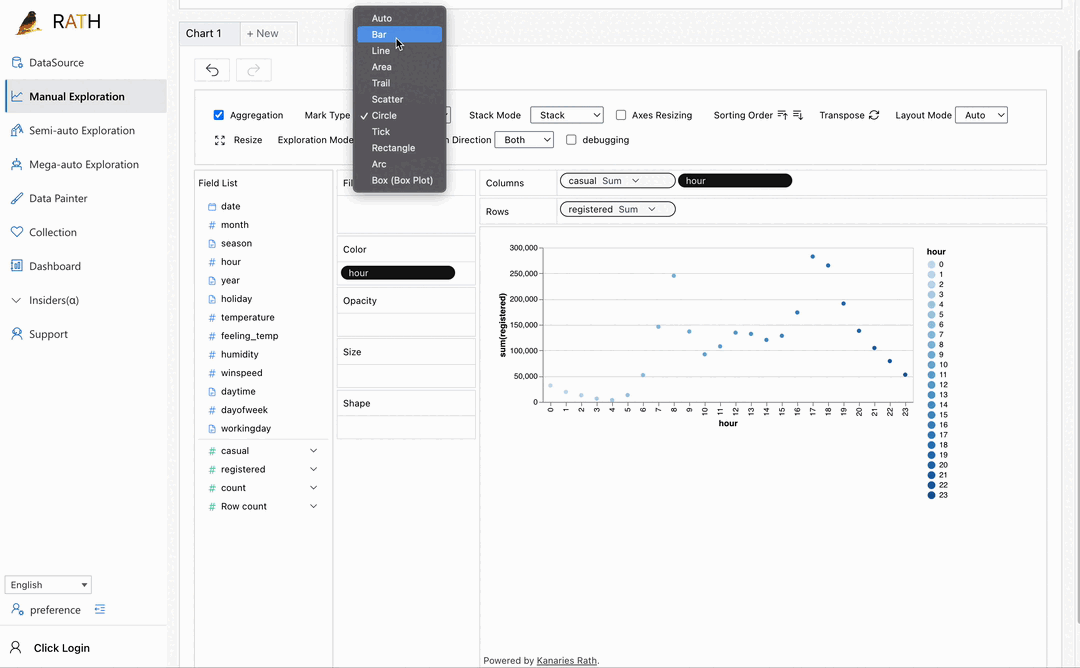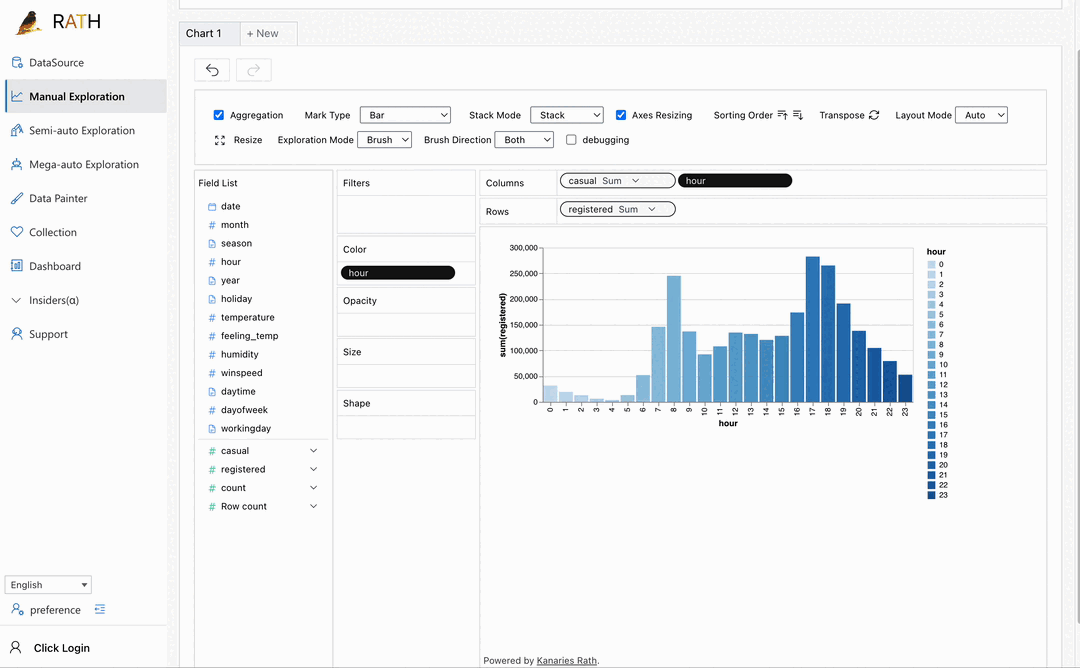 |
| 因果分析 (opens in a new tab) | 複雑な関係分析の因果関係の発見と説明を提供します。 | 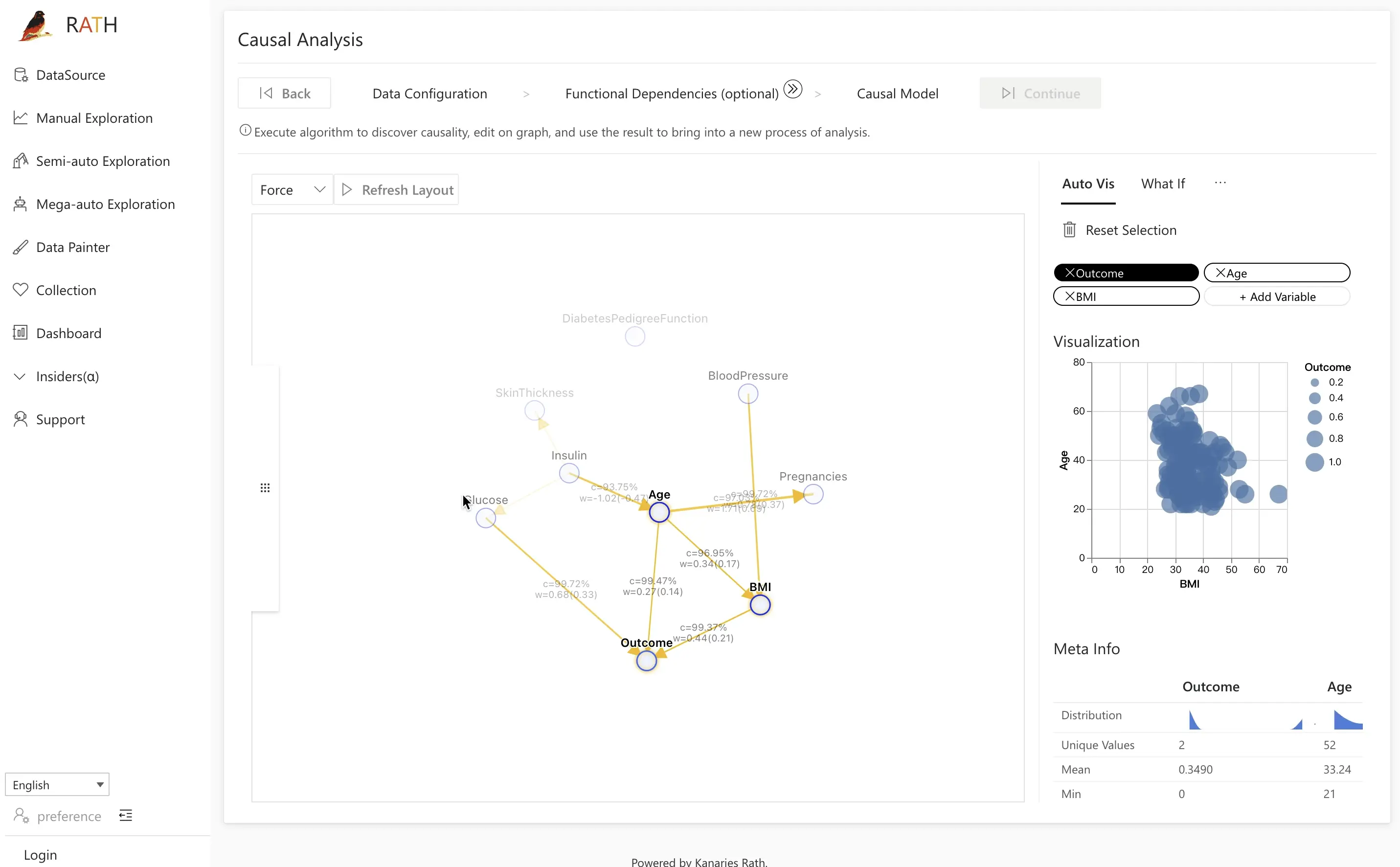 |
結論
結論として、ChatGPT は効率的な SQL クエリを生成するための強力なツールです。 データの集約、フィルタリング、および最適化のための複雑なクエリをすばやく生成できるため、エラーのリスクが軽減され、ユーザーの時間が節約されます。
効率的な SQL クエリを生成する ChatGPT の機能に加えて、探索的データ分析 (EDA) ワークフローを自動化し、自動化されたデータ探索、視覚化、および半自動探索を提供してデータ分析をより効率的にするオープンソース ツールである RATH もあります。 そして効果的。