Python で Pandas DataFrame をマージ、結合、連結する方法

pandas での マージ、結合、DataFrame の連結は、複数のデータセットを 1 つに結合できるようにする重要な手法です。 これらの手法は、データのクリーニング、変換、および分析に不可欠です。 マージ、結合、および連結 はしばしば同じ意味で使用されますが、データを結合するさまざまな方法を指します。 この投稿では、これら 3 つの重要な手法について詳しく説明し、Python でそれらを使用する方法の例を示します。
Pandas でのデータフレームのマージ
マージ は、1 つ以上の共通キーに基づいて行をリンクすることにより、2 つ以上の DataFrame を 1 つの DataFrame に結合するプロセスです。 共通キーは、マージされる DataFrame で一致する値を持つ 1 つ以上の列にすることができます。
さまざまな種類のマージ
pandas には、内側、外側、左、右の 4 種類のマージがあります。
- Inner Merge: 両方の DataFrame で値が一致する行のみを返します。
- Outer Merge: 両方の DataFrame からすべての行を返し、一致しない場合は不足値を NaN で埋めます。
- Left Merge: 左の DataFrame からすべての行を返し、右の DataFrame から一致する行を返します。 一致しない場合は、欠損値を NaN で埋めます。
- Right Merge: 右側の DataFrame からすべての行を返し、左側の DataFrame から一致する行を返します。 一致しない場合は、欠損値を NaN で埋めます。
さまざまな種類のマージを実行する方法の例
Pandas を使用してさまざまな種類のマージを実行する方法の例をいくつか見てみましょう。
例 1: 内部マージ
import pandas as pd
# Creating two DataFrames
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# 内部マージ
merged_inner = pd.merge(df1, df2, on='key')
print(merged_inner)出力:
key value_x value_y
0 B 2 5
1 D 4 6例 2: 外部マージ
import pandas as pd
# 2 つの DataFrame の作成
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'],
'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'],
'value': [5, 6, 7, 8]})
# 外部マージ
merged_outer = pd.merge(df1, df2, on='key', how='outer')
print(merged_outer)出力:
key value_x value_y
0 A 1.0 NaN
1 B 2.0 5.0
2 C 3.0 NaN
3 D 4.0 6.0
4 E NaN 7.0
5 F NaN 8.0例 3: 左マージ 左マージは、左の DataFrame からすべての行を返し、右の DataFrame から一致した行を返します。 右側の DataFrame に一致しない左側の DataFrame の行は、右側の DataFrame の列に NaN 値を持ちます。
import pandas as pd
# 2 つの DataFrame を作成します
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E'], 'value': [5, 6, 7]})
# 左マージを実行
left_merged_df = pd.merge(df1, df2, on='key', how='left')
# マージされた DataFrame を出力します
print(left_merged_df)出力:
key value_x value_y
0 A 1 NaN
1 B 2 5.0
2 C 3 NaN
3 D 4 6.0例 4: 右マージ 右側のマージは、右側の DataFrame からすべての行を返し、左側の DataFrame から一致した行を返します。 左側の DataFrame に一致しない右側の DataFrame の行は、左側の DataFrame の列に NaN 値を持ちます。
import pandas as pd
# Create two DataFrames
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E'], 'value': [5, 6, 7]})
# 右側のマージを実行
right_merged_df = pd.merge(df1, df2, on='key', how='right')
# マージされた DataFrame を出力します
print(right_merged_df)出力:
key value_x value_y
0 B 2.0 5
1 D NaN 6
2 E NaN 7pandas で DataFrame を結合する
結合 は、インデックスまたは列の値に基づいて 2 つの DataFrame を 1 つに結合する方法です。
pandas には、内側、外側、左、右の 4 種類の結合があります。
- Inner Join: 両方の DataFrame で一致するインデックスまたは列の値を持つ行のみを返します。
- Outer Join: 両方の DataFrame からすべての行を返し、一致しない場合は不足値を NaN で埋めます。
- Left Join: 左側の DataFrame からすべての行を返し、右側の DataFrame から一致する行を返します。 一致しない場合は、欠損値を NaN で埋めます。
- Right Join: 右側の DataFrame からすべての行を返し、左側の DataFrame から一致する行を返します。 一致しない場合は、欠損値を NaN で埋めます。
pandas での DataFrame の連結
連結 は、2 つ以上の DataFrame を垂直または水平に結合するプロセスです。 パンダでは、これは concat() 関数を使用して実現できます。 concat() 関数を使用すると、2 つ以上の DataFrame を垂直または水平に積み重ねることで、1 つの DataFrame に結合できます。
pandas を使用して 2 つ以上の DataFrame を連結する方法の例
2 つ以上の DataFrame を垂直方向に連結するには、次のコードを使用できます。
import pandas as pd
# Create two sample DataFrames
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
'B': ['B4', 'B5', 'B6', 'B7'],
'C': ['C4', 'C5', 'C6', 'C7'],
'D': ['D4', 'D5', 'D6', 'D7']})
# DataFrame を垂直方向に連結する
result = pd.concat([df1, df2])
print(result)出力:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
0 A4 B4 C4 D4
1 A5 B5 C5 D5
2 A6 B6 C6 D6
3 A7 B7 C7 D72 つ以上の DataFrame を水平方向に連結するには、次のコードを使用できます。
import pandas as pd
# 2 つのサンプル DataFrame を作成します
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
df2 = pd.DataFrame({'E': ['E0', 'E1', 'E2', 'E3'],
'F': ['F0', 'F1', 'F2', 'F3'],
'G': ['G0', 'G1', 'G2', 'G3'],
'H': ['H0', 'H1', 'H2', 'H3']})
# DataFrame を水平方向に連結する
result = pd.concat([df1, df2], axis=1)
print(result)出力:
A B C D E F G H
0 A0 B0 C0 D0 E0 F0 G0 H0
1 A1 B1 C1 D1 E1 F1 G1 H1
2 A2 B2 C2 D2 E2 F2 G2 H2Panda データフレームの連結ビューを作成する
Python 内で連結ビューを作成するには、PyGWalker (opens in a new tab) というオープン ソースのデータ分析とデータ視覚化パッケージを利用できます。
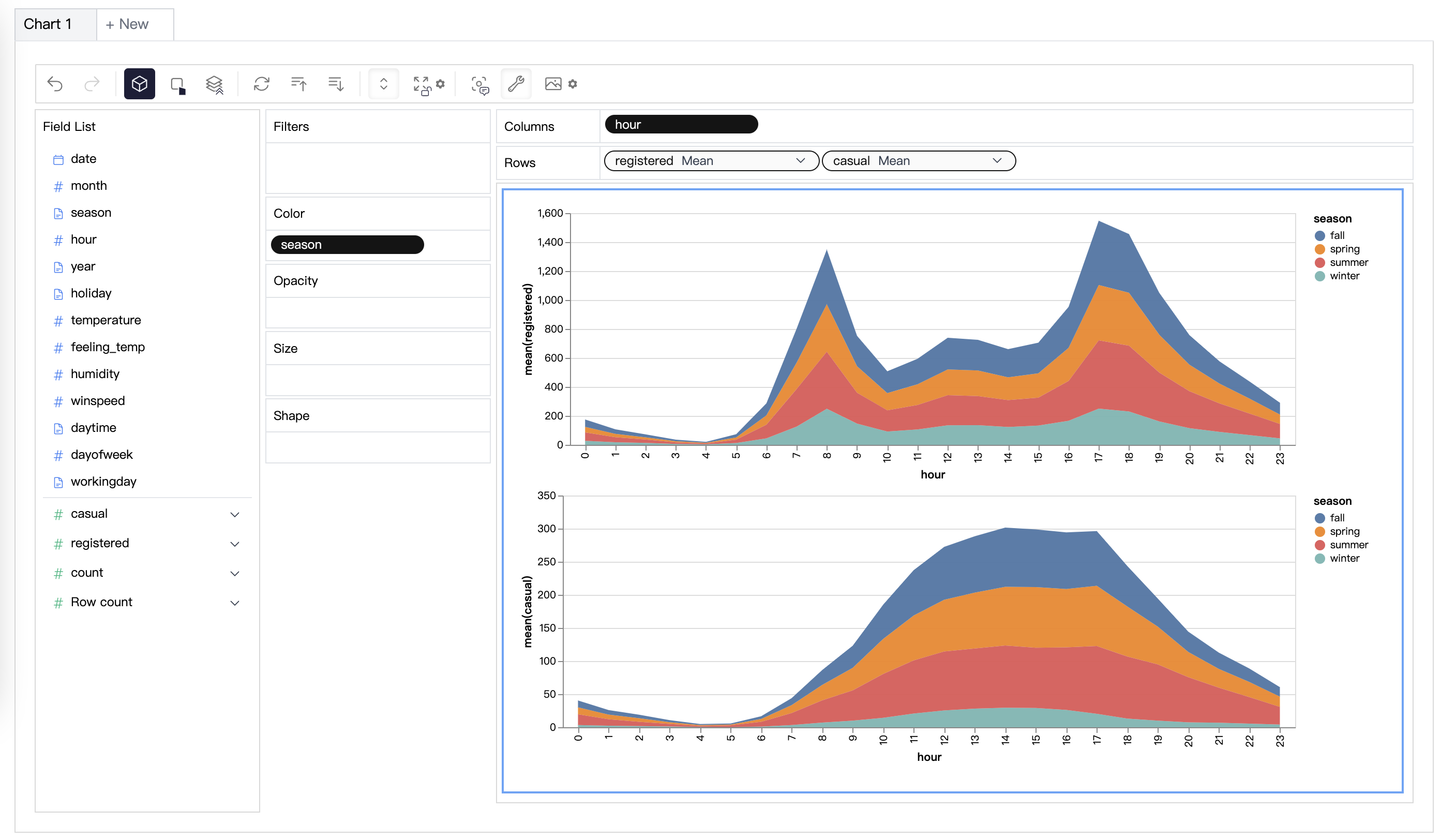
PyGWalker は、Jupyter Notebook のデータ分析とデータ視覚化のワークフローを簡素化できます。 Python を使用してデータを分析する代わりに、軽量で使いやすいインターフェイスを導入することで。 手順は簡単です:
開始するには、pygwalker と pandas を Jupyter Notebook にインポートします。
import pandas as pd
import pygwalker as pyg既存のワークフローを変更せずに pygwalker を使用できます。 たとえば、次の方法でロードされたデータフレームで Graphic Walker を呼び出すことができます。
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)ユーザーフレンドリーな UI で Pandas データフレームを視覚化できるようになりました。
変数をドラッグ アンド ドロップするだけで、連結ビューを簡単に作成できます。
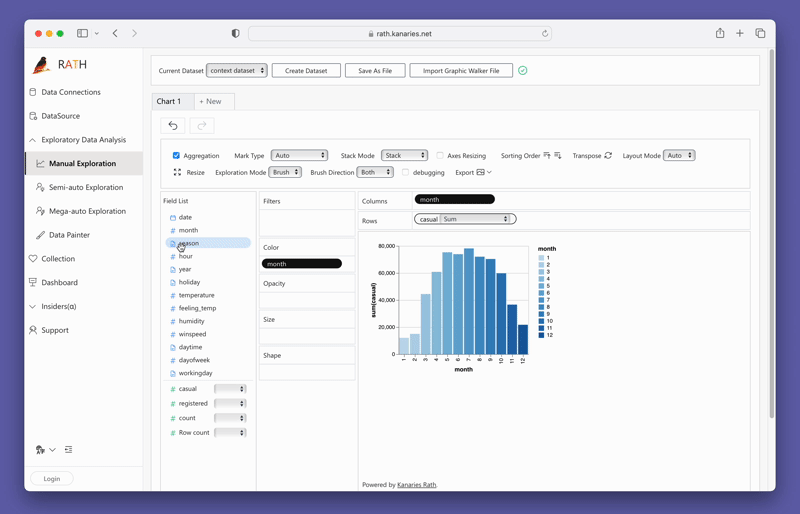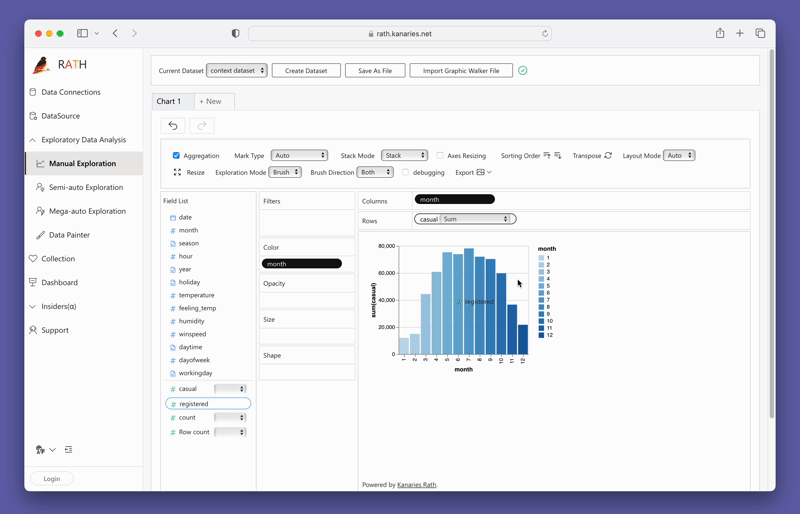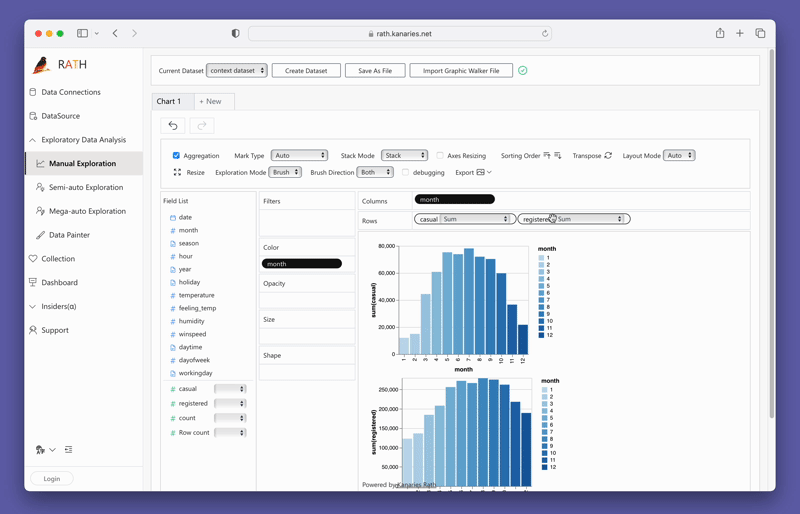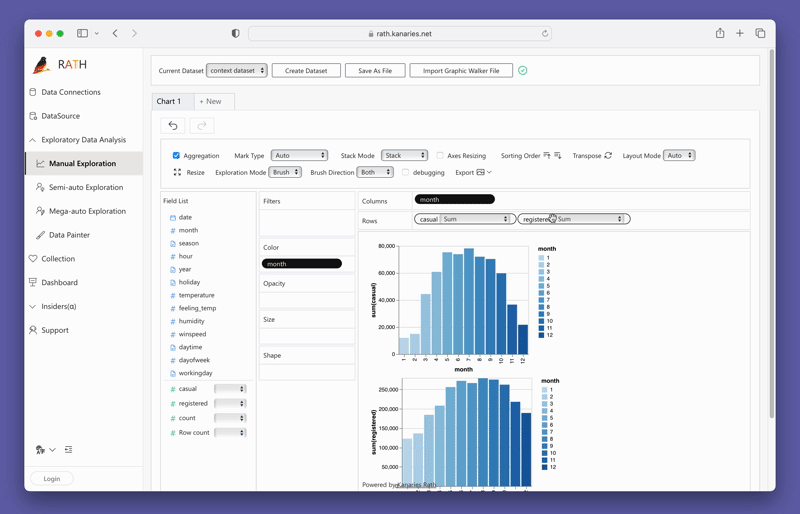
PyGWalker を今すぐテストするには、Google Colab (opens in a new tab)、Binder (opens in a new tab) または Kaggle (opens in a new tab)。
PyGWalker はオープン ソースです。 PyGWalker GitHub ページ (opens in a new tab) をチェックアウトし、データ サイエンスに向けた記事 (opens in a new tab) です。
より高度な AI を活用した自動データ分析ツール RATH (opens in a new tab) を忘れずにチェックしてください。 RATH もオープンソースであり、GitHub のソース コード (opens in a new tab) をホストしています。
よくある質問
それを使用して 2 つの DataFrame を結合するにはどうすればよいですか?
PySpark は、Python、Java、Scala、または R でデータ処理アプリケーションを作成できるオープンソースのビッグ データ処理フレームワークです。PySpark を使用して 2 つの DataFrame を結合するには、join() メソッドを使用できます。 オブジェクトとオプションの結合式。 how パラメータを使用して、結合のタイプを指定できます。
# PySpark ライブラリをインポートして SparkSession を作成
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("JoinExample").getOrCreate()
# 2 つの DataFrame を作成
df1 = spark.createDataFrame([(1, 'A'), (2, 'B'), (3, 'C')], ['id', 'letter'])
df2 = spark.createDataFrame([(1, 'X'), (2, 'Y'), (3, 'Z')], ['id', 'symbol'])
# PySpark を使用して 2 つの DataFrame を結合します
joined_df = df1.join(df2, 'id', 'inner')
# 結果の DataFrame を表示
joined_df.show()R を使用して 2 つの DataFrame をマージするにはどうすればよいですか?
R を使用して 2 つの DataFrame をマージするには、merge() 関数を使用できます。この関数は、2 つのデータ フレームと、データのマージ方法を指定するオプションの引数セットを取ります。
# 2 つのデータ フレームを作成
df1 <- data.frame(id = c(1, 2, 3), letter = c("A", "B", "C"))
df2 <- data.frame(id = c(1, 2, 4), symbol = c("X", "Y", "Z"))
# R を使用して 2 つのデータ フレームをマージする
merged_df <- merge(df1, df2, by = "id", all = TRUE)
# 結果のデータフレームを表示
print(merged_df)pandas に 2 つ以上の DataFrame を追加するにはどうすればよいですか?
pandas に 2 つ以上の DataFrame を追加するには、concat() 関数を使用できます。この関数は、DataFrame のリストと、DataFrame を連結する軸を指定するオプションの axis パラメータを取ります。
# パンダ ライブラリをインポート
import pandas as pd
# 2 つの DataFrame を作成
df1 = pd.DataFrame({'id': [1, 2, 3], 'letter': ['A', 'B', 'C']})
df2 = pd.DataFrame({'id': [4, 5, 6], 'letter': ['D', 'E', 'F']})
# pandas を使用して 2 つの DataFrame を追加します
appended_df = pd.concat([df1, df2], ignore_index=True)
# 結果の DataFrame を表示
print(appended_df)
pandas を使用して、共通の列に基づいて 2 つの DataFrame を結合するにはどうすればよいですか?
pandas を使用して共通の列に基づいて 2 つの DataFrame を結合するには、merge() 関数を使用できます。この関数は、2 つの DataFrame と、データのマージ方法を指定するオプションの引数セットを取ります。 on パラメータを使用して、結合する列を指定できます。
# 2 つの DataFrame を作成
df1 = pd.DataFrame({'id': [1, 2, 3], 'letter': ['A', 'B', 'C']})
df2 = pd.DataFrame({'id': [1, 2, 4], 'symbol': ['X', 'Y', 'Z']})
# pandas を使用して 2 つの DataFrame を結合します
joined_df = pd.merge(df1, df2, on='id', how='inner')
# 結果の DataFrame を表示
print(joined_df)結論
結論として、DataFrame のマージ、結合、および連結は、データ分析において不可欠な操作です。 pandas、PySpark、R などの強力なツールを使用すると、これらの操作を簡単かつ効率的に実行できます。 大規模なデータセットでも小規模なデータセットでも、これらのツールはデータを操作するための柔軟で直感的な方法を提供します。