PyGWalkerの紹介:Streamlitの可視化にスーパーチャージ
PyGWalker (opens in a new tab)は優れたPythonライブラリであり、Pythonのデータフレームを直感的で「tableau」のようなインターフェースに変換し、データの可視化を簡単にします。
通常はデータサイエンティストがデータセットに深入りするのを手助けするためにJupyterで使用されますが、PyGWalker (opens in a new tab)はStreamlitと組み合わせることでその優れた機能が発揮されます。Streamlitの魅力は、フロントエンドやバックエンドの技術に精通する必要なく、煩わしさなしにデータアプリケーションを簡単に構築し共有することができるという点にあります。
PyGWalker (opens in a new tab)をStreamlitと統合することで、独自の「ウェブのtableau」を作成することができます。これにより、ダッシュボードを共有し、ユーザーがPyGWalker (opens in a new tab)の直感的なドラッグアンドドロップUIで自由に探索することができます。最近のアップデートでは、「チャットからグラフ」の機能も追加されており、APIキーを追加するだけで利用することができます。
PyGWalker (opens in a new tab)の特徴はクラウドネイティブの設計です。クラウドデータベース、OLAP、またはDWに接続する能力を持つため、多くの高価な伝統的なBIツールを凌駕する高性能な体験ができます。
クラウドベースのPyGWalkerをStreamlitで作成しましょう。
依存関係の設定:
pip install pygwalker
pip install streamlitこのチュートリアルでは、地震のデータセットを使用します。これはCSVファイルからロードすることができます。
def get_df() -> pd.DataFrame:
df = pd.read_csv("./Significant Earthquake_Dataset_1900_2023.csv")
df["Time"] = pd.to_datetime(df["Time"]).dt.strftime('%Y-%m-%d %H:%M:%S')
return df読み込んだら、データセットをPyGWalkerに渡します。
from pygwalker.api.streamlit import get_streamlit_htm
html = get_streamlit_html(df, use_kernel_calc=True, spec="./spec/geo_vis.json", debug=False)そして、単純にPyGWalkerのHTMLをStreamlitでレンダリングします。
import streamlit.components.v1 as components
components.html(get_pyg_html(df), width=1300, height=1000, scrolling=True)アプリを起動して動作させましょう。
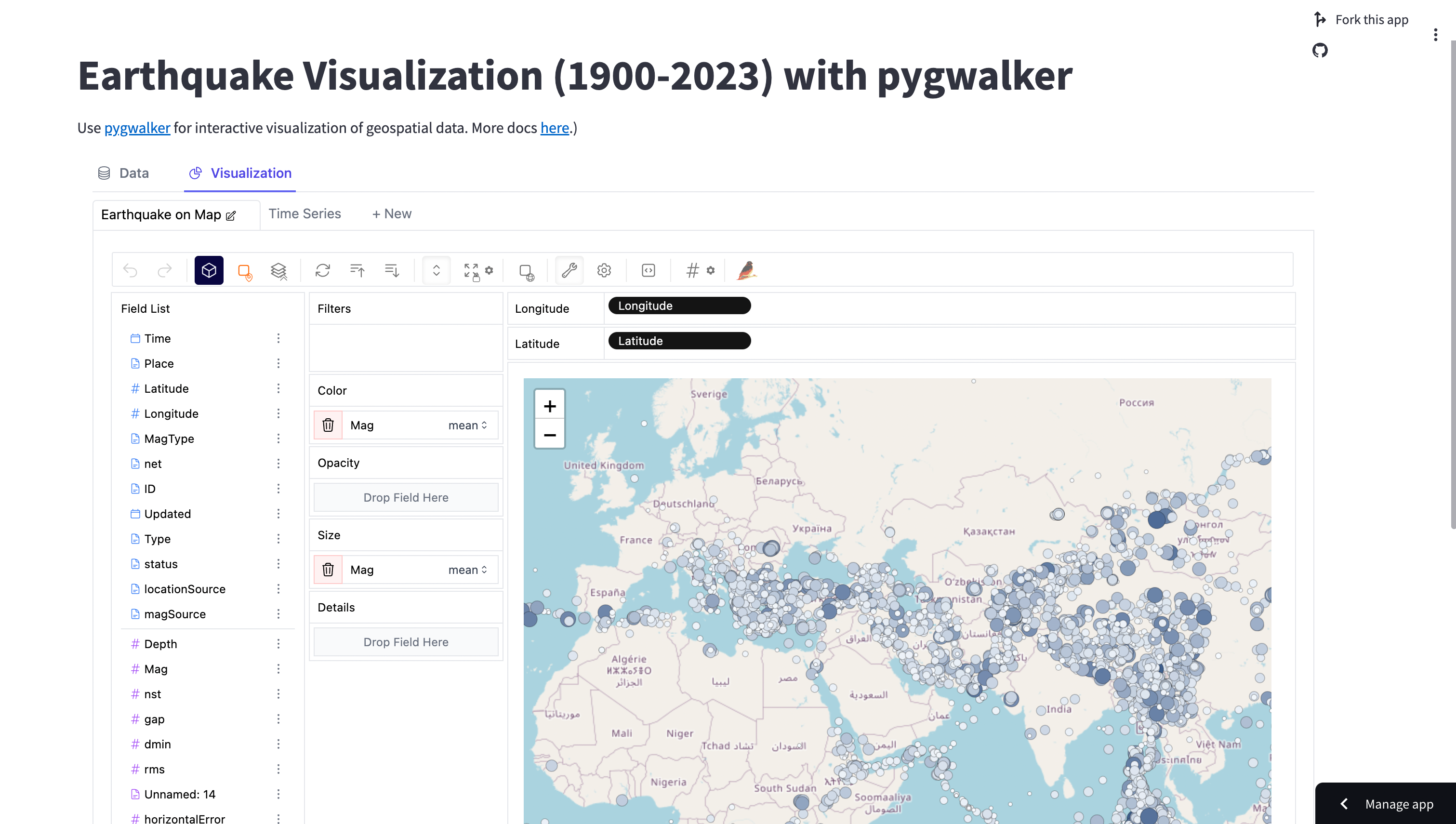
PyGWalkerの新しいエンジンでクエリを高速化
v0.3以降、PyGWalkerはDuckDBベースの計算エンジンを統合し、大規模なデータセットでも迅速なデータクエリを実現しています。
これを有効にするには、use_kernel_calcパラメータを追加するだけです。
pyg.walk(df, use_kernel_calc=True)これはJupyterなどの環境ではシームレスに機能しますが、Streamlitではフロントエンドとバックエンド間のデータ転送制限があります。ただし、Kanaries (opens in a new tab)の開発チームのおかげで、簡単な解決策があります。
from pygwalker.api.streamlit import init_streamlit_comm
init_streamlit_comm()まとめ
PyGWalkerをStreamlitと組み合わせることで、最小限のコードで動的なオンラインインタラクティブデータ可視化アプリを作成することができます。さあ、データの探索を始めて変身させましょう!