Vicuna-13B: Eine Open-Source-Alternative zu ChatGPT, die GPT-4 beeindruckt

Die Welt der Chatbots hat in den letzten Jahren bedeutende Fortschritte gemacht mit der Entwicklung großer Sprachmodelle (LLMs) wie OpenAI's ChatGPT. Die Details der Architektur und des Trainings von ChatGPT bleiben jedoch verborgen, was es Forschern schwer macht, auf seinen Erfolgen aufzubauen. Hier kommt Vicuna ins Spiel – eine Open-Source-Chatbot-Alternative zu ChatGPT, die auf einem robusten Datensatz und einer skalierbaren Infrastruktur basiert. In diesem Artikel werden wir uns ausführlich mit den Fähigkeiten von Vicuna, seiner Entwicklung und seinem Potenzial für zukünftige Forschung beschäftigen.
Was ist Vicuna oder Vicuna-13B?
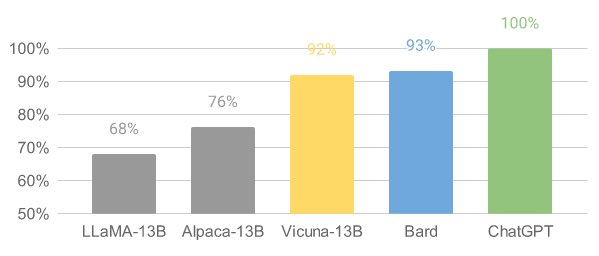
Vicuna (opens in a new tab) ist ein Open-Source-Chatbot-Modell namens Vicuna-13B, das von einem Team von Forschern der UC Berkeley, CMU, Stanford und der UC San Diego entwickelt wurde. Es wurde durch Feinabstimmung des LLaMA-Modells anhand von nutzergespeicherten Unterhaltungen von ShareGPT erstellt, und vorläufige Bewertungen zeigen, dass es mehr als 90 % der Qualität von ChatGPT erreicht. Beachtenswert ist, dass die Kosten für das Training von Vicuna-13B etwa 300 US-Dollar betragen.
Wie gut ist die Leistung von Vicuna?
Vicuna hat eine beeindruckende Leistung in vorläufigen Bewertungen gezeigt. Durch Feinabstimmung von Vicuna mit 70.000 nutzergespeicherten ChatGPT-Unterhaltungen ist das Modell in der Lage, detaillierte und gut strukturierte Antworten zu generieren. Die Qualität steht auf demselben Niveau wie ChatGPT und übertrifft in über 90 % der Fälle andere Modelle wie LLaMA und Stanford Alpaca.
Die Entwicklung von Vicuna: Schulungs- und Bereitstellungsinfrastruktur
Das Vicuna-Team hat rund 70.000 Unterhaltungen von ShareGPT.com gesammelt und die von Alpaca bereitgestellten Schulungsskripte verbessert. Für das Training verwendeten sie PyTorch FSDP auf 8 A100-GPUs und implementierten ein leichtgewichtiges verteiltes Bereitstellungssystem. Das Team führte auch eine vorläufige Bewertung der Modellqualität durch, indem es einen Satz von 80 verschiedenen Fragen erstellte und GPT-4 zur Bewertung der Modellausgaben verwendete.
Für das Training von Vicuna wurde das LLaMA-Basismodell durch Feinabstimmung mit nutzergespeicherten Unterhaltungen verbessert. Die Datenqualität wurde durch die Konvertierung von HTML zurück in Markdown und Filterung unpassender oder minderwertiger Beispiele sichergestellt. Es wurden auch verschiedene Verbesserungen am Schulungsrezept vorgenommen, wie z.B. Speicheroptimierungen, Umgang mit mehrstufigen Unterhaltungen und Kostensenkung durch Spot-Instanzen.
Das für Vicuna entwickelte Bereitstellungssystem ist in der Lage, mehrere Modelle mit verteilten Workern bereitzustellen. Es unterstützt flexible Plug-Ins für GPU-Worker sowohl von vor Ort befindlichen Clustern als auch aus der Cloud. Durch Verwendung eines ausfallsicheren Controllers und der verwalteten Spot-Funktion in SkyPilot kann das Bereitstellungssystem gut mit kostengünstigeren Spot-Instanzen aus verschiedenen Clouds arbeiten und so die Bereitstellungskosten reduzieren.
Das Vicuna-Team hat den Schulungs-, Bereitstellungs- und Evaluierungscode auf GitHub (opens in a new tab) veröffentlicht.
Bewertung von Chatbots mit GPT-4
Die Bewertung von Chatbots ist eine herausfordernde Aufgabe, aber das Vicuna-Team schlägt ein Evaluierungsframework auf Basis von GPT-4 vor, um die Bewertung der Leistung von Chatbots zu automatisieren. Sie haben acht Fragekategorien entwickelt, um verschiedene Aspekte der Leistung von Chatbots zu testen, und festgestellt, dass GPT-4 relativ konsistente Bewertungen und detaillierte Erklärungen zu diesen Bewertungen liefern kann. Dieses vorgeschlagene Evaluierungsframework ist jedoch noch kein rigoroser Ansatz, da große Sprachmodelle wie GPT-4 anfällig für Halluzinationen sind. Die Entwicklung eines umfassenden, standardisierten Evaluierungssystems für Chatbots bleibt eine offene Frage, die weitere Forschung erfordert.
Einschränkungen und zukünftige Forschung
Vicuna, wie andere große Sprachmodelle, hat Einschränkungen bei Aufgaben, die logisches Denken oder Mathematik erfordern. Es kann auch Schwierigkeiten haben, sich selbst genau zu identifizieren oder die faktische Genauigkeit seiner Ausgaben sicherzustellen. Darüber hinaus wurde es nicht ausreichend optimiert, um Sicherheitsaspekte, Toxizität oder Vorurteile zu berücksichtigen. Dennoch dient Vicuna als offener Ausgangspunkt für zukünftige Forschungsvorhaben, um diese Einschränkungen anzugehen, zusammen mit anderen neuesten Durchbrüchen im Bereich der KI wie Auto-GPT und LongChain.
FAQ
-
Wie kann ich die Gewichte des Vicuna 13-B-Modells erhalten und verwenden? Um das Vicuna 13-B-Modell zu verwenden, müssen Sie das Original-Modell LLaMa 13B herunterladen und die vom Vicuna-Team bereitgestellten Delta-Gewichte anwenden. Die Delta-Gewichte finden Sie unter https://huggingface.co/lmsys/vicuna-13b-delta-v0 (opens in a new tab).
-
Wie wende ich die Delta-Gewichte auf das LLaMa 13B-Modell an? Sie können die Delta-Gewichte anwenden, indem Sie dem Befehl im FastChat-Repository folgen: python3 -m fastchat.model.apply_delta --base /pfad/zum/llama-13b --target /ausgabepfad/zum/vicuna-13b --delta lmsys/vicuna-13b-delta-v0. Dieser Befehl lädt automatisch die Delta-Gewichte herunter und wendet sie auf das Basismodell an.
-
Kann ich das Vicuna 13-B-Modell in das llama.cpp/gpt4all-Format konvertieren? Ja, das Vicuna 13-B-Modell kann in das llama.cpp/gpt4all-Format quantisiert werden. Das Modell ändert nur geringfügig die vorhandenen Gewichte, ohne die Struktur zu verändern.
-
Gibt es Lizenzprobleme bei der Verwendung von Vicuna 13-B? Das Vicuna-Team veröffentlicht die Gewichte als Delta-Gewichte, um mit der LLaMa-Modelllizenz konform zu sein. Die Verwendung des Modells für kommerzielle Zwecke kann jedoch aufgrund möglicher rechtlicher Komplikationen problematisch sein.