Python에서 Pandas DataFrame을 병합, 결합 및 연결하는 방법

팬더에서병합, 결합, 데이터프레임 연결은 여러 데이터세트를 하나로 결합할 수 있는 중요한 기술입니다.이러한 기술은 데이터를 정리, 변환 및 분석하는 데 필수적입니다.병합, 결합 및 연결은 종종 같은 의미로 사용되지만 데이터를 결합하는 다양한 방법을 나타냅니다.이 게시물에서는 이 세 가지 중요한 기술에 대해 자세히 설명하고 Python에서 사용하는 방법의 예를 제공합니다.
Pandas의 데이터프레임 병합
병합은 하나 이상의 공통 키를 기반으로 행을 연결하여 둘 이상의 DataFrame을 단일 DataFrame으로 결합하는 프로세스입니다.공통 키는 병합되는 DataFrame에서 일치하는 값을 가진 하나 이상의 열일 수 있습니다.
다양한 유형의 병합
판다에는 내부, 외부, 왼쪽 및 오른쪽의 네 가지 유형의 병합이 있습니다.
- 내부 병합: 두 DataFrame에서 값이 일치하는 행만 반환합니다.
- Outer Merge: 두 DataFrame의 모든 행을 반환하고 일치하는 항목이 없는 경우 누락된 값을 NaN으로 채웁니다.
- 왼쪽 병합: 왼쪽 DataFrame의 모든 행과 오른쪽 DataFrame에서 일치하는 행을 반환합니다.일치하는 값이 없는 경우 누락된 값을 NaN으로 채웁니다.
- 오른쪽 병합: 오른쪽 DataFrame의 모든 행과 왼쪽 DataFrame에서 일치하는 행을 반환합니다.일치하는 값이 없는 경우 누락된 값을 NaN으로 채웁니다.
다양한 유형의 병합을 수행하는 방법의 예
Pandas를 사용하여 다양한 유형의 병합을 수행하는 방법에 대한 몇 가지 예를 살펴보겠습니다.
예 1: 내부 병합
코드_블록_플레이스홀더_0
출력:
코드_블록_플레이스홀더_1
예 2: 아우터 머지 코드_블록_플레이스홀더_2 출력: 코드_블록_플레이스홀더_3
예 3: 왼쪽 병합 왼쪽 병합은 왼쪽 DataFrame의 모든 행과 오른쪽 DataFrame에서 일치하는 행을 반환합니다.왼쪽 DataFrame에서 오른쪽 DataFrame에 일치하는 행이 없는 행은 오른쪽 DataFrame의 열에 NaN 값을 갖게 됩니다.
코드_블록_플레이스홀더_4
출력:
코드_블록_플레이스홀더_5
예 4: 오른쪽 병합 오른쪽 병합은 오른쪽 DataFrame의 모든 행과 왼쪽 DataFrame에서 일치하는 행을 반환합니다.오른쪽 DataFrame에서 왼쪽 DataFrame에 일치하는 행이 없는 행은 왼쪽 DataFrame의 열에 NaN 값을 갖게 됩니다.
코드_블록_플레이스홀더_6
출력:
코드_블록_플레이스홀더_7
팬더에서 데이터프레임 합치기
조인은 인덱스 또는 열 값을 기반으로 두 DataFrame을 하나로 결합하는 방법입니다.
판다에는 내부, 외부, 왼쪽 및 오른쪽의 네 가지 유형의 조인이 있습니다.
- 내부 조인: 두 DataFrame에서 인덱스 또는 열 값이 일치하는 행만 반환합니다.
- Outer Join: 두 DataFrame의 모든 행을 반환하고 일치하는 항목이 없는 경우 누락된 값을 NaN으로 채웁니다.
- 왼쪽 조인: 왼쪽 DataFrame의 모든 행과 오른쪽 DataFrame에서 일치하는 행을 반환합니다.일치하는 값이 없는 경우 누락된 값을 NaN으로 채웁니다.
- 오른쪽 조인: 오른쪽 DataFrame의 모든 행과 왼쪽 DataFrame에서 일치하는 행을 반환합니다.일치하는 값이 없는 경우 누락된 값을 NaN으로 채웁니다.
팬더에서 데이터프레임 연결하기
연결은 두 개 이상의 DataFrame을 수직 또는 수평으로 결합하는 프로세스입니다.판다에서는 concat () 함수를 사용하여 이 작업을 수행할 수 있습니다.concat () 함수를 사용하면 둘 이상의 DataFrame을 세로 또는 가로로 쌓아 단일 DataFrame으로 결합할 수 있습니다.
팬더를 사용하여 두 개 이상의 DataFrame을 연결하는 방법의 예
두 개 이상의 DataFrame을 세로로 연결하려면 다음 코드를 사용할 수 있습니다.
코드_블록_플레이스홀더_8
출력:
코드_블록_플레이스홀더_9
두 개 이상의 DataFrame을 가로로 연결하려면 다음 코드를 사용할 수 있습니다.
코드_블록_플레이스홀더_10
출력:
코드_블록_플레이스홀더_11
Panda 데이터프레임용 컨택트 뷰 생성
파이썬에서 Concat 뷰를 생성하기 위한 오픈 소스 데이터 분석 및 데이터 시각화 패키지가 있습니다: Pygwalker (opens in a new tab).
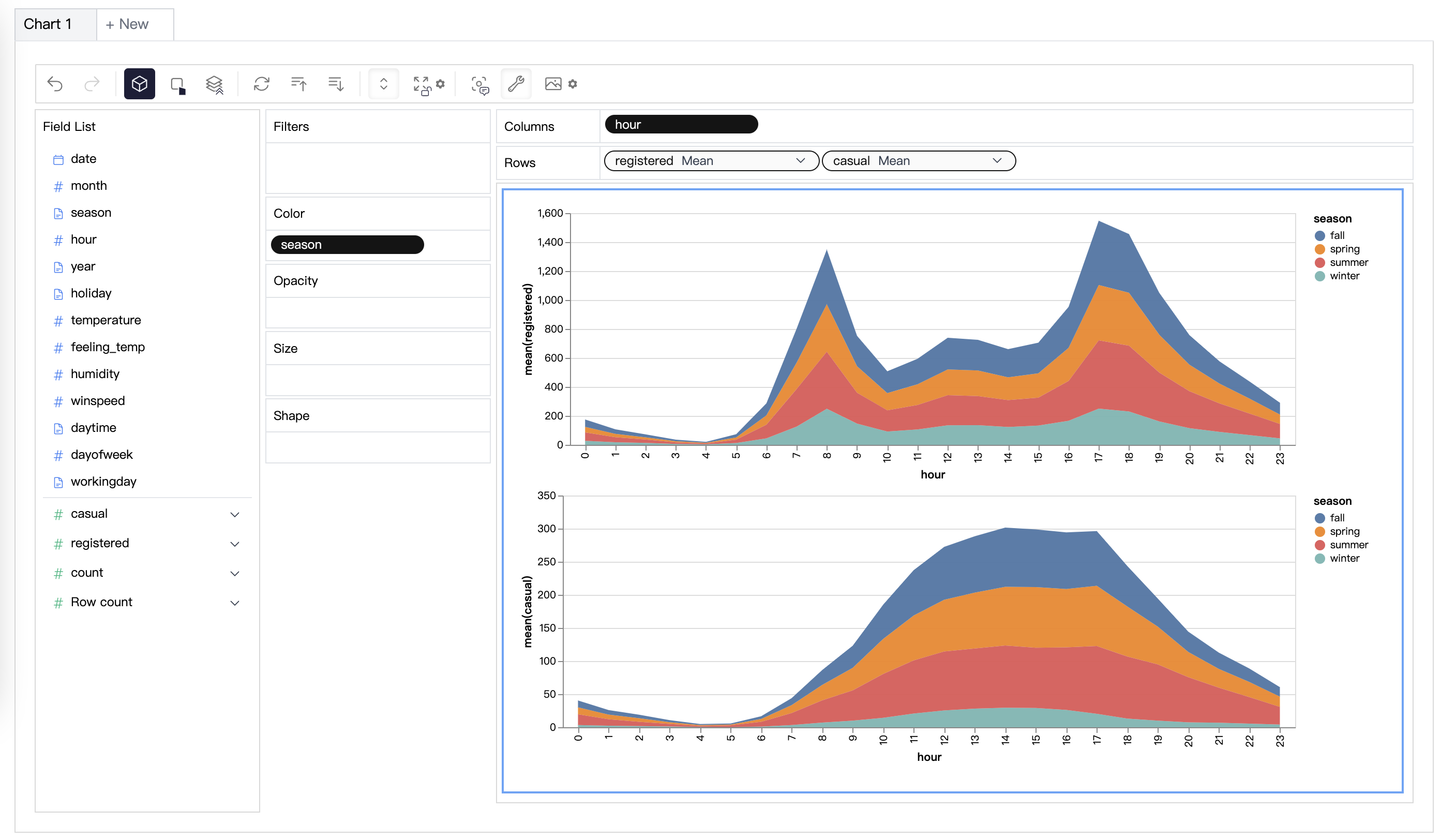
PygWalker는 주피터 노트북 데이터 분석 및 데이터 시각화 워크플로를 단순화할 수 있습니다.Python을 사용하여 데이터를 분석하는 대신 가볍고 사용하기 쉬운 인터페이스를 제공합니다.단계는 간단합니다.
피그워커와 판다를 Jupyter 노트북으로 가져와서 시작하세요. 코드_블록_플레이스홀더_12 기존 워크플로를 변경하지 않고 pygwalker를 사용할 수 있습니다.예를 들어 다음과 같이 로드된 데이터프레임을 사용하여 그래픽 워커를 호출할 수 있습니다. 코드_블록_플레이스홀더_13 이제 사용자 친화적인 UI로 Pandas 데이터프레임을 시각화할 수 있습니다!
변수를 드래그 앤 드롭하여 간단히 Concat View를 만들 수 있습니다.
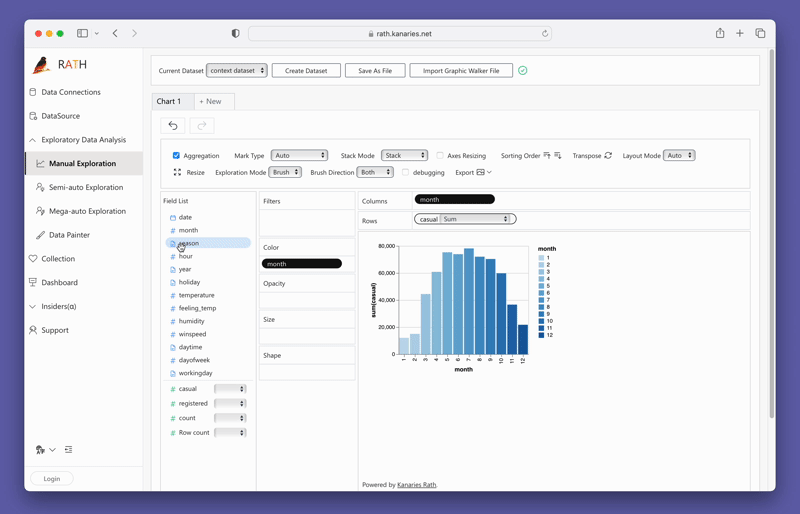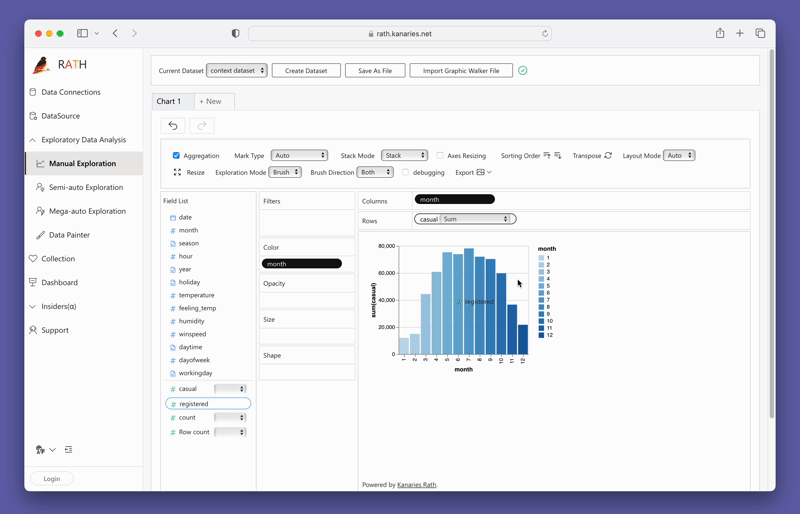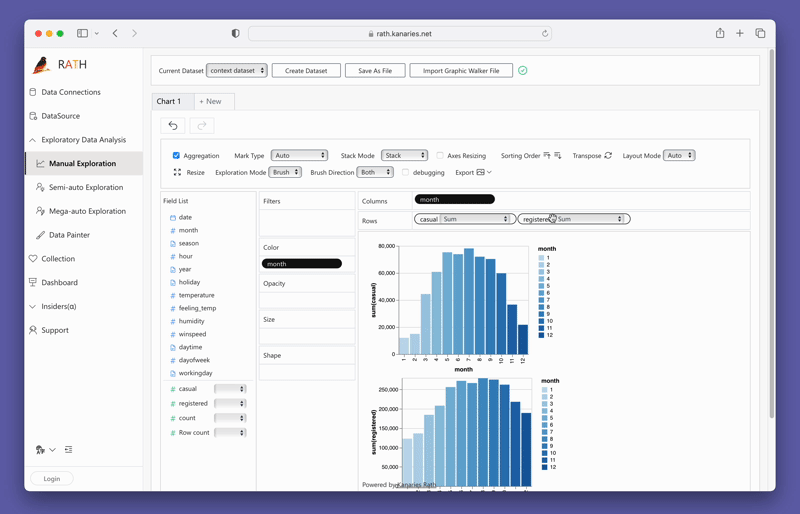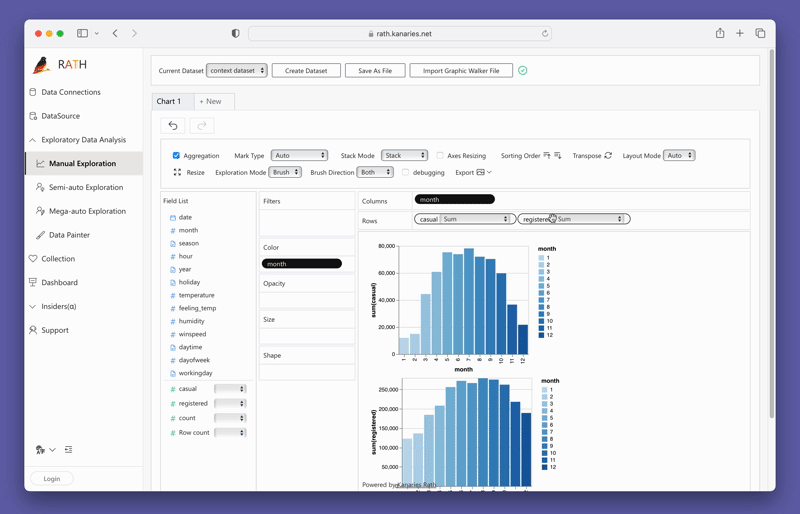
PygWalker를 지금 테스트하려면 구글 콜랩 (opens in a new tab), 바인더 (opens in a new tab) 또는 Kaggle (opens in a new tab) 에서 PygWalker를 실행할 수 있습니다.
피그워커는 오픈 소스입니다.PygWalker GitHub 페이지 (opens in a new tab) 에서 확인하고 해당 문서의 데이터 과학을 향하여 (opens in a new tab) 를 읽을 수 있습니다.
더 발전된 AI 기반 자동 데이터 분석 도구인 RATH (opens in a new tab) 를 확인하는 것도 잊지 마세요.RATH는 또한 오픈 소스이며 GitHub의 소스 코드 (opens in a new tab) 를 호스팅합니다.
자주 묻는 질문
이를 사용하여 두 개의 DataFrame을 결합하려면 어떻게 해야 하나요?
PySpark는 Python, Java, Scala 또는 R로 데이터 처리 애플리케이션을 작성할 수 있는 오픈 소스 빅데이터 처리 프레임워크입니다. PySpark를 사용하여 두 개의 DataFrame을 결합하려면 두 개의 DataFrame 객체와 하나의 선택적 조인 표현식을 취하는 join () 메서드를 사용할 수 있습니다.how 매개 변수를 사용하여 조인 유형을 지정할 수 있습니다.
코드_블록_플레이스홀더_14
R을 사용하여 두 개의 DataFrame을 병합하려면 어떻게 해야 하나요?
R을 사용하여 두 개의 DataFrame을 병합하려면 두 개의 데이터 프레임과 데이터 병합 방법을 지정하는 선택적 인수 세트를 사용하는 merge () 함수를 사용할 수 있습니다.
코드_블록_플레이스홀더_15
팬더에 두 개 이상의 DataFrame을 추가하려면 어떻게 해야 하나요?
팬더에 둘 이상의 DataFrame을 추가하려면 DataFrames 목록과 DataFrames를 연결해야 하는 축을 지정하는 선택적 축 매개 변수를 가져오는 concat () 함수를 사용할 수 있습니다.
코드_블록_플레이스홀더_16
팬더를 사용하여 공통 열을 기반으로 두 개의 DataFrame을 결합하려면 어떻게 해야 하나요?
판다를 사용하여 공통 열을 기반으로 두 개의 DataFrame을 결합하려면 두 개의 DataFrame과 데이터 병합 방법을 지정하는 선택적 인수 세트를 사용하는 merge () 함수를 사용할 수 있습니다.on 매개 변수를 사용하여 결합할 열을 지정할 수 있습니다.
코드_블록_플레이스홀더_17
결론
결론적으로 DataFrame의 병합, 결합 및 연결은 데이터 분석에서 필수적인 작업입니다.Pandas, PySpark 및 R과 같은 강력한 도구를 사용하면 이러한 작업을 쉽고 효율적으로 수행할 수 있습니다.데이터 집합이 크든 작든 관계없이 이러한 도구는 데이터를 조작할 수 있는 유연하고 직관적인 방법을 제공합니다.