Vicuna-13B: Uma alternativa de código aberto ao ChatGPT que impressiona o GPT-4

O mundo dos chatbots viu avanços significativos nos últimos anos com o desenvolvimento de modelos de linguagem grande (LLMs) como o ChatGPT da OpenAI. No entanto, os detalhes da arquitetura e treinamento do ChatGPT permanecem elusivos, tornando difícil para os pesquisadores construir sobre seus sucessos. É aqui que entra o Vicuna, uma alternativa de código aberto ao ChatGPT, apoiada por um robusto conjunto de dados e infraestrutura escalável. Neste artigo, mergulharemos nas capacidades do Vicuna, como ele foi desenvolvido e seu potencial para pesquisas futuras.
O que é Vicuna ou Vicuna-13B?
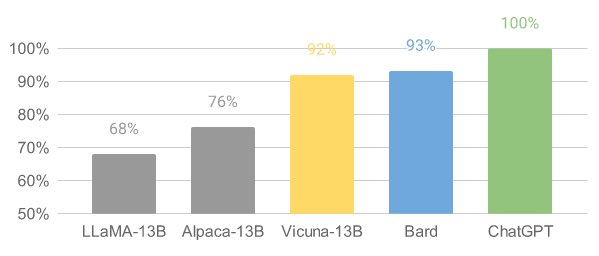
Vicuna (opens in a new tab) é um modelo de chatbot de código aberto chamado Vicuna-13B, criado por uma equipe de pesquisadores da UC Berkeley, CMU, Stanford e UC San Diego. Ele é construído por ajuste fino do modelo LLaMA em conversas compartilhadas por usuários do ShareGPT e avaliações preliminares mostram que ele alcança mais de 90% da qualidade do ChatGPT. Notavelmente, o custo de treinamento do Vicuna-13B é de aproximadamente $300.
Como o Vicuna se Desempenha?
O Vicuna demonstrou um desempenho impressionante em avaliações preliminares. Ao ajustá-lo com 70.000 conversas do ChatGPT compartilhadas pelos usuários, o modelo se torna capaz de gerar respostas detalhadas e bem estruturadas. Sua qualidade é equiparável a do ChatGPT e supera outros modelos como LLaMA e Stanford Alpaca em mais de 90% dos casos.
Desenvolvimento do Vicuna: Infraestrutura de Treinamento e Serviço
A equipe do Vicuna coletou cerca de 70.000 conversas do ShareGPT.com e aprimorou os scripts de treinamento fornecidos pelo Alpaca. Eles usaram PyTorch FSDP em 8 GPUs A100 para treinamento e implementaram um sistema de serviço distribuído leve. A equipe também realizou uma avaliação preliminar da qualidade do modelo criando um conjunto de 80 perguntas diversas e utilizando o GPT-4 para julgar as saídas do modelo.
Para treinar o Vicuna, a equipe ajustou o modelo base do LLaMA usando conversas compartilhadas pelos usuários. Eles garantiram a qualidade dos dados convertendo o HTML de volta para markdown e filtrando amostras inapropriadas ou de baixa qualidade. Eles também fizeram várias melhorias à receita de treinamento, como otimizações de memória, lidando com conversas de várias rodadas e reduzindo o custo por meio de instâncias do tipo spot.
O sistema de serviço construído para o Vicuna é capaz de servir vários modelos com trabalhadores distribuídos. Ele suporta plug-ins flexíveis para trabalhadores GPU tanto de clusters no local quanto da nuvem. Ao usar um controlador tolerante a falhas e a funcionalidade de instâncias spot gerenciadas do SkyPilot, o sistema de serviço pode funcionar bem com instâncias mais baratas de várias nuvens, reduzindo os custos de serviço.
A equipe do Vicuna lançou o código de treinamento, serviço e avaliação no GitHub (opens in a new tab).
Avaliando Chatbots com o GPT-4
A avaliação de chatbots é uma tarefa desafiadora, mas a equipe do Vicuna propõe uma estrutura de avaliação baseada no GPT-4 para automatizar a avaliação de desempenho de chatbots. Eles elaboraram oito categorias de perguntas para testar vários aspectos do desempenho do chatbot e descobriram que o GPT-4 pode produzir pontuações relativamente consistentes e explicações detalhadas dessas pontuações. No entanto, essa estrutura de avaliação proposta ainda não é uma abordagem rigorosa, já que modelos de linguagem grandes como o GPT-4 são propensos a alucinação. O desenvolvimento de um sistema de avaliação abrangente e padronizado para chatbots continua sendo uma questão em aberto que requer mais pesquisas.
Limitações e Pesquisas Futuras
O Vicuna, como outros modelos de linguagem grandes, tem limitações em tarefas que envolvem raciocínio ou matemática. Ele também pode ter dificuldades em se identificar com precisão ou garantir a precisão factual de suas saídas. Além disso, não foi suficientemente otimizado para segurança, toxicidade ou mitigação de viés.
No entanto, o Vicuna serve como ponto de partida aberto para pesquisas futuras para abordar essas limitações, juntamente com outros avanços mais recentes no campo da IA, como o Auto-GPT e LongChain.
FAQ
-
Como posso obter e usar os pesos do modelo do Vicuna 13-b? Para usar o modelo Vicuna 13-b, você precisa baixar o modelo original do LLaMa 13B e aplicar os pesos delta fornecidos pela equipe do Vicuna. Os pesos delta podem ser encontrados em https://huggingface.co/lmsys/vicuna-13b-delta-v0 (opens in a new tab).
-
Como aplicar os pesos delta ao modelo LLaMa 13B? Você pode aplicar os pesos delta seguindo o comando no repositório FastChat: python3 -m fastchat.model.apply_delta --base /path/to/llama-13b --target /output/path/to/vicuna-13b --delta lmsys/vicuna-13b-delta-v0. Este comando irá baixar e aplicar automaticamente os pesos delta ao modelo base.
-
Posso converter o modelo Vicuna 13-b para o formato llama.cpp/gpt4all? Sim, o modelo Vicuna 13-b pode ser quantizado para o formato llama.cpp/gpt4all. O modelo apenas ajusta os pesos existentes ligeiramente, sem alterar a estrutura.
-
Existem problemas de licenciamento ao usar o Vicuna 13-b? A equipe do Vicuna lança os pesos como pesos delta para cumprir a licença do modelo LLaMa. No entanto, usar o modelo para fins comerciais ainda pode ser uma má ideia devido a possíveis complicações legais.