Eine Einführung in PyGWalker: Steigern Sie Ihre Streamlit-Visualisierungen
PyGWalker (opens in a new tab) ist eine außergewöhnliche Python-Bibliothek, die Python DataFrames in eine intuitive, tableau-ähnliche Benutzeroberfläche verwandelt und die Datenvisualisierung zum Kinderspiel macht.
Traditionell in Jupyter verwendet, um Data Scientists bei der Analyse ihrer Datensätze zu unterstützen, zeigt die Vielseitigkeit von PyGWalker ihr Potenzial, wenn sie mit Streamlit kombiniert wird. Streamlits Charme liegt in seiner Fähigkeit, Datenanwendungen mühelos zu erstellen, ohne Fachkenntnisse in Front- oder Backend-Technologien zu erfordern. Ganz einfach gesagt, können Sie Dashboards erstellen und teilen, ohne großen Aufwand.
Die Integration von PyGWalker (opens in a new tab) mit Streamlit ermöglicht es Ihnen, Ihre eigene "Web Tableau" zu erstellen. Dadurch können Dashboards geteilt werden und Benutzer können frei mit der intuitiven Drag & Drop-Benutzeroberfläche von PyGWalker (opens in a new tab) erkunden. In den neuesten Updates wurde außerdem eine "Chat-to-Charts"-Funktion eingeführt, die durch Hinzufügen eines API-Schlüssels aktiviert wird.
Was PyGWalker (opens in a new tab) auszeichnet, ist sein cloud-natives Design. Mit seiner Fähigkeit, eine Vielzahl von Cloud-Datenbanken, OLAP oder DW zu verbinden, garantiert es ein leistungsstarkes Erlebnis und übertrifft viele kostenintensive traditionelle BI-Tools.
Bereit für die Erstellung eines Cloud-basierten PyGWalker (opens in a new tab) mit Streamlit? Tauchen wir ein.
Einrichten der Abhängigkeiten:
pip install pygwalker
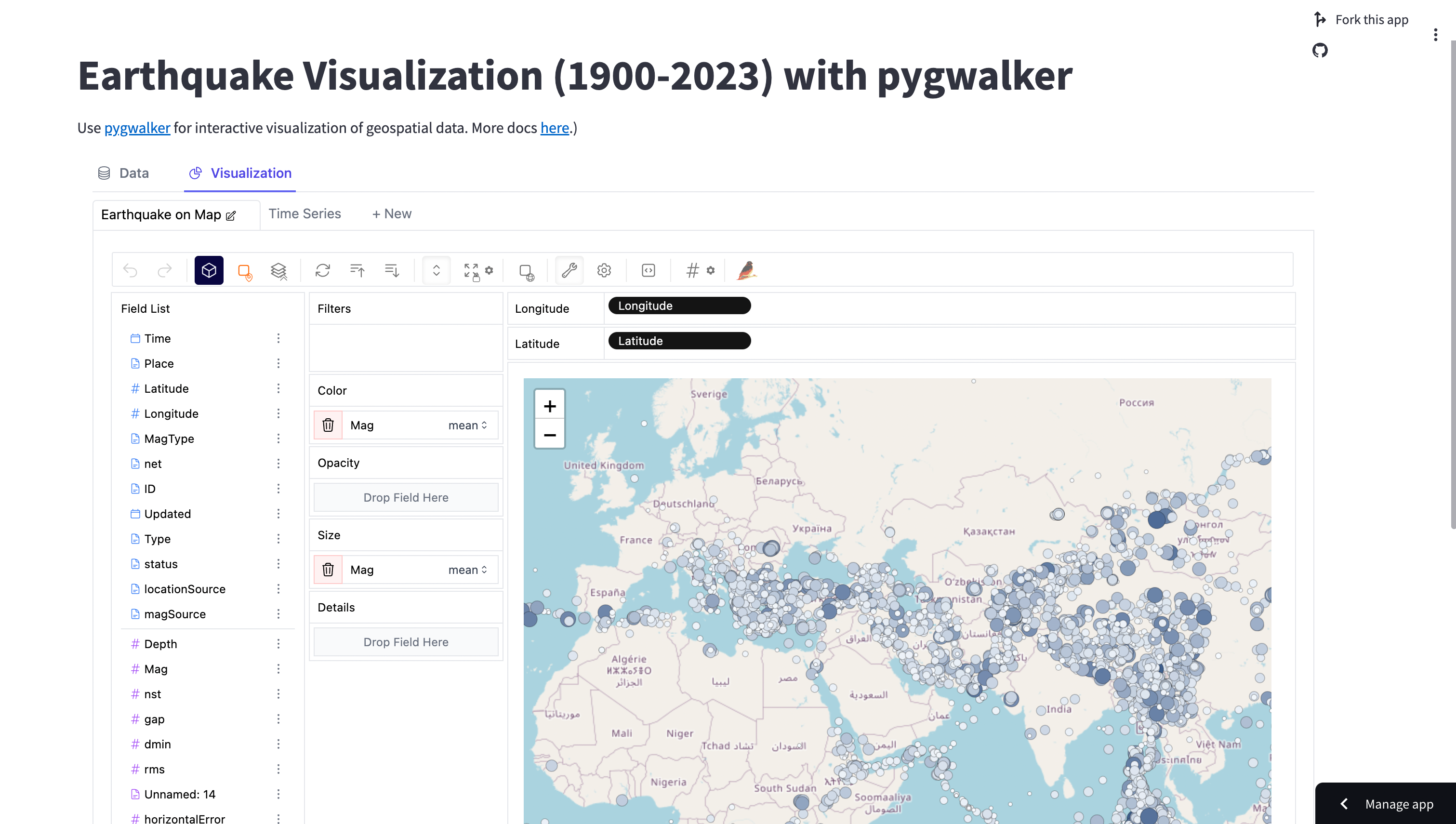
pip install streamlitFür dieses Tutorial verwenden wir einen Erdbeben-Datensatz, der aus einer CSV-Datei geladen werden kann.
def get_df() -> pd.DataFrame:
df = pd.read_csv("./Significant Earthquake_Dataset_1900_2023.csv")
df["Time"] = pd.to_datetime(df["Time"]).dt.strftime('%Y-%m-%d %H:%M:%S')
return dfSobald der Datensatz geladen ist, übergeben Sie ihn an PyGWalker (opens in a new tab):
from pygwalker.api.streamlit import get_streamlit_htm
html = get_streamlit_html(df, use_kernel_calc=True, spec="./spec/geo_vis.json", debug=False)Rendern Sie nun einfach HTML von PyGWalker (opens in a new tab) mit Streamlit:
import streamlit.components.v1 as components
components.html(get_pyg_html(df), width=1300, height=1000, scrolling=True)Bringen Sie Ihre App zum Laufen:
Turbocharge Ihre Abfragen mit PyGWalker's neuem Engine
Seit Version 0.3 hat PyGWalker den DuckDB-basierten Berechnungs-Engine integriert, der schnellere Datenabfragen ermöglicht, auch bei umfangreichen Datensätzen.
Um dies zu aktivieren, fügen Sie einfach den Parameter use_kernel_calc hinzu:
pyg.walk(df, use_kernel_calc=True)Während dies nahtlos in Umgebungen wie Jupyter funktioniert, setzt Streamlit bestimmte Datenübertragungsgrenzen zwischen Frontend und Backend. Dank des Entwicklungsteams von Kanaries (opens in a new tab) gibt es jedoch eine einfache Lösung:
from pygwalker.api.streamlit import init_streamlit_comm
init_streamlit_comm()Fazit
Die Kombination von PyGWalker mit Streamlit ebnet den Weg für die Erstellung dynamischer interaktiver Datenvisualisierungs-Apps online mit minimalem Code. Tauchen Sie ein und transformieren Sie Ihre Datenexplorationen noch heute!