¿Puede ChatGPT reemplazar a los analistas de datos? Genere consultas SQL complejas sin esfuerzo con ChatGPT

Introducción
SQL (Structured Query Language) es un lenguaje de programación ampliamente utilizado para gestionar y manipular datos en bases de datos relacionales. Las empresas y organizaciones necesitan almacenar, recuperar y analizar datos. Sin embargo, escribir consultas SQL puede ser una tarea que consume mucho tiempo y propensa a errores para los humanos, especialmente para consultas complejas o bases de datos grandes.
En este artículo, exploraremos las capacidades de ChatGPT, un modelo de lenguaje grande desarrollado por OpenAI, en la generación de consultas SQL eficientes. Mostraremos cómo ChatGPT puede generar rápidamente consultas complejas, filtrar datos con alta precisión y recordar, y optimizar consultas existentes.
Generar una base de datos de muestra
Para aclarar las cosas, tenemos la siguiente base de datos de muestra como ejemplo:
Tabla 1: libros
Esta tabla contendrá información sobre todos los libros en la librería, incluyendo sus títulos, autores, editoriales y ISBN.
CREATE TABLE books (
book_id INT PRIMARY KEY,
title VARCHAR(255),
author VARCHAR(255),
publisher VARCHAR(255),
isbn VARCHAR(13)
);Tabla 2: clientes
Esta tabla almacenará información sobre los clientes que se han registrado en la librería, incluyendo sus nombres, direcciones de correo electrónico y números de teléfono.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255),
phone VARCHAR(20)
);Tabla 3: órdenes
Esta tabla almacenará información sobre todas las órdenes realizadas por los clientes, incluyendo el cliente que realizó la orden, el(s) libro(s) ordenado(s), la fecha de la orden y el estado de la orden.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
book_id INT,
order_date DATE,
status VARCHAR(20),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id),
FOREIGN KEY (book_id) REFERENCES books(book_id)
);Tabla 4: inventario
Esta tabla realizará un seguimiento de los niveles de inventario actuales de cada libro en la tienda.
CREATE TABLE inventory (
book_id INT PRIMARY KEY,
quantity INT,
FOREIGN KEY (book_id) REFERENCES books(book_id)
);Estas son solo las tablas básicas que necesitaría para comenzar con una base de datos de una librería. Dependiendo de sus necesidades específicas, es posible que desee agregar tablas o columnas adicionales a estas tablas.
Solicitud de ChatGPT para Agregación de Datos
Una de las tareas más comunes en el trabajo con bases de datos es la agregación de datos. Esto se refiere a resumir datos en función de ciertas condiciones. Por ejemplo, calcular las ventas totales de una categoría de productos específica o el salario promedio de los empleados en un determinado departamento. Las consultas de agregación pueden ser complejas de escribir y pueden llevar mucho tiempo para los humanos.
Sin embargo, ChatGPT puede generar estas consultas de manera rápida y precisa. Puede entender la estructura de los datos y el resultado deseado, y generar una consulta eficiente que pueda recuperar la información requerida con un esfuerzo mínimo. Esto reduce el riesgo de errores y ahorra tiempo al usuario.
Aquí hay un ejemplo de una consulta de agregación de datos generada por ChatGPT con la siguiente solicitud:
"Encuentra los 5 libros más vendidos en el último trimestre, junto con sus autores y el total de ingresos por ventas."
Para realizar esta agregación, deberá unir las tablas de libros, órdenes e inventario, agrupar los resultados por libro y autor, filtrar por las órdenes del último trimestre y calcular el total de ingresos por ventas para cada libro. Por último, deberá ordenar los resultados por ingresos y limitar la salida a los 5 libros principales.
ChatGPT genera el siguiente código SQL para lograr esto:
SELECT books.title, books.author, SUM(inventory.quantity * orders.price) AS revenue
FROM books
JOIN inventory ON books.book_id = inventory.book_id
JOIN orders ON inventory.book_id = orders.book_id
WHERE orders.order_date >= DATEADD(QUARTER, -1, GETDATE())
GROUP BY books.title, books.author
ORDER BY revenue DESC
LIMIT 5;Filtrado de datos
Otra tarea importante en el trabajo con bases de datos es el filtrado de datos. Esto se refiere a extraer datos específicos de una base de datos en función de ciertos criterios. Por ejemplo, extraer todas las transacciones realizadas por clientes en una ubicación determinada o todos los empleados que han estado en la empresa durante más de cinco años. Las consultas de filtrado también pueden ser complejas de escribir y pueden llevar mucho tiempo para los humanos.
ChatGPT puede generar estas consultas con alta precisión y recordar. Puede entender la estructura de los datos y el resultado deseado, y generar una consulta que pueda recuperar los datos más relevantes. Esto resulta en datos más precisos para el análisis y la toma de decisiones. Aquí hay un ejemplo de una consulta de filtrado de datos generada utilizando esta solicitud de ChatGPT:
"Encuentra todos los libros publicados por 'Penguin Random House' y actualmente en stock, ordenados por nombre de autor en orden ascendente."
Para realizar este filtrado, deberá unir las tablas de libros e inventario, filtrar por los libros publicados por 'Penguin Random House' y seleccionar solo aquellos libros que se encuentren actualmente en stock. Por último, deberá ordenar los resultados por nombre de autor en orden ascendente.
ChatGPT genera el siguiente código SQL para lograr este requisito:
SELECT books.title, books.author, books.publisher, inventory.quantity
FROM books
JOIN inventory ON books.book_id = inventory.book_id
DONDE books.publisher = 'Penguin Random House' Y inventory.quantity > 0
ORDENAR POR books.author ASC;Optimización de consultas
Además de generar nuevas consultas SQL, ChatGPT también puede ayudar a optimizar consultas existentes. Al analizar la estructura y rendimiento de una consulta, ChatGPT puede sugerir mejoras que hagan que la consulta se ejecute más rápido y de manera más eficiente. Por ejemplo, ChatGPT puede sugerir el uso de índices o la reescritura de la consulta para aprovechar las capacidades de la base de datos.
La optimización de consultas puede ser una tarea difícil para los humanos, especialmente para bases de datos grandes y complejas. ChatGPT puede simplificar esta tarea y ayudar a mejorar el rendimiento de la base de datos. Aquí tienes un ejemplo de optimización de consulta generada mediante el uso de esta indicación de ChatGPT:
"Encuentra los 10 clientes que más han gastado en libros en el último año, junto con su gasto total y su gasto promedio por pedido."
Para optimizar esta consulta, tendrás que minimizar la cantidad de operaciones que la base de datos necesita realizar para obtener los resultados. Aquí tienes algunas técnicas de optimización que podrías considerar:
-
Utilizar índices: Agrega índices a las columnas relevantes de las tablas de clientes y pedidos para acelerar las operaciones de unión y filtrado.
-
Agregar antes de unir: En lugar de unir directamente las tablas de clientes y pedidos y luego agregar los resultados, puedes agregar primero la tabla de pedidos por cliente y luego unir la tabla resultante con la tabla de clientes.
-
Utilizar subconsultas: En lugar de unir directamente las tablas de clientes y pedidos, puedes usar subconsultas para filtrar la tabla de pedidos por rango de fechas y calcular el gasto total y el gasto promedio por pedido para cada cliente.
Aquí tienes un ejemplo de consulta SQL que implementa estas optimizaciones generadas por ChatGPT:
SELECCIONAR clientes.nombre,
gasto_total,
gasto_total / cantidad_pedidos AS gasto_promedio_por_pedido
DE (
SELECCIONAR id_cliente,
SUM(precio * cantidad) AS gasto_total,
COUNT(*) AS cantidad_pedidos
DE pedidos
DONDE fecha_pedido >= DATEADD(AÑO, -1, GETDATE())
AGRUPAR POR id_cliente
) COMO totales_pedidos
UNIR clientes ON totales_pedidos.id_cliente = clientes.id_cliente
ORDENAR POR gasto_total DESC
LIMITAR 10;Otra opción de análisis de datos automatizado: RATH
Además de las capacidades de ChatGPT para generar consultas SQL eficientes, también existe RATH (opens in a new tab), una alternativa de código abierto a las herramientas de análisis y visualización de datos como Tableau. RATH lleva el análisis de datos al siguiente nivel automatizando el flujo de trabajo del Análisis Exploratorio de Datos (EDA) con un motor de análisis aumentado.
RATH admite una amplia gama de fuentes de datos (opens in a new tab). Aquí tienes algunas de las principales soluciones de base de datos a las que puedes conectarte con RATH: MySQL, ClickHouse, Amazon Athena, Amazon Redshift, Apache Spark SQL, Apache Doris, Apache Hive, Apache Impala, Apache Kylin, Oracle y PostgreSQL.
RATH (opens in a new tab) es de código abierto. Visita el repositorio de RATH en GitHub y experimenta con la herramienta de Auto-EDA (opens in a new tab) de próxima generación. ¡También puedes probar la demostración en línea de RATH como tu Patio de Juegos para el Análisis de Datos!

Las características destacadas de RATH incluyen:
| Función | Descripción | Vista previa |
|---|---|---|
| AutoEda (opens in a new tab) | Motor de análisis aumentado para descubrir patrones, información y relaciones causales. Una forma completamente automatizada de explorar tu conjunto de datos y visualizarlo con un clic. | 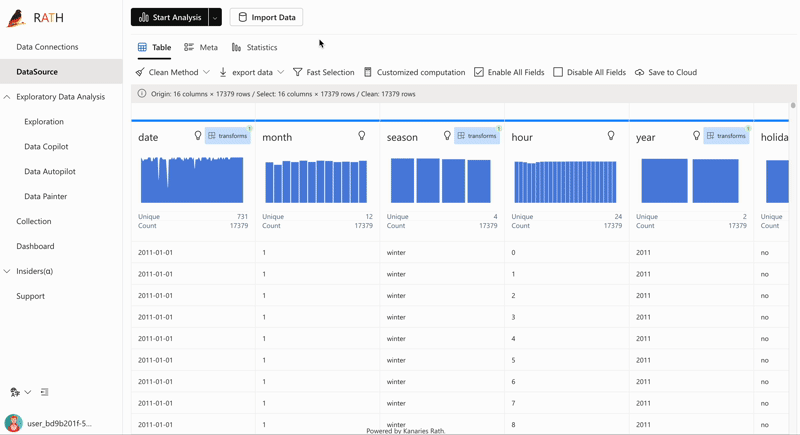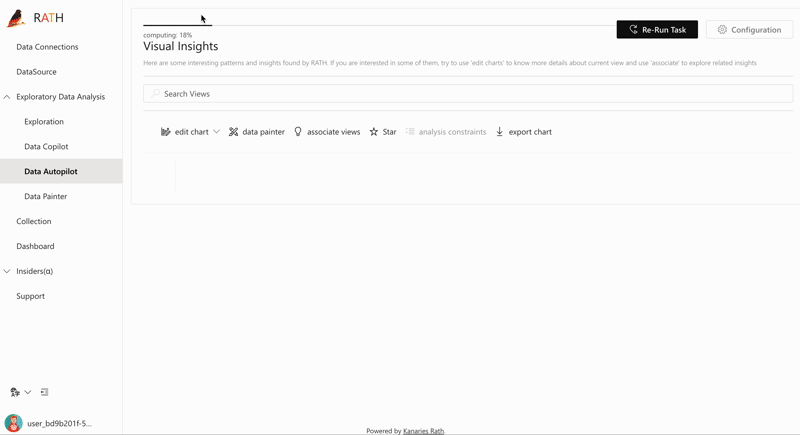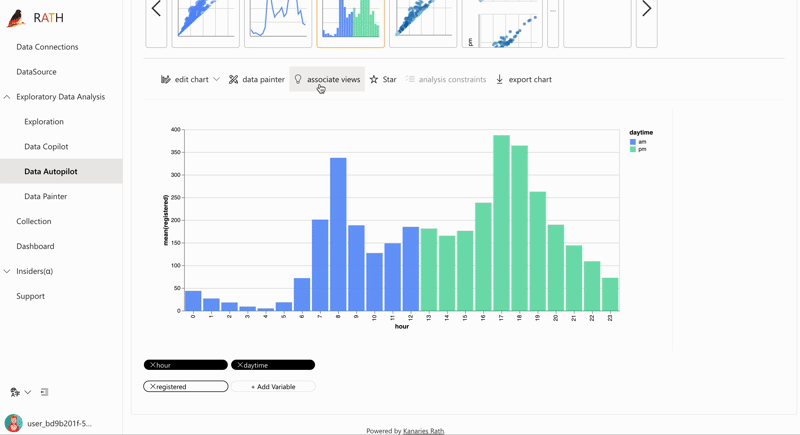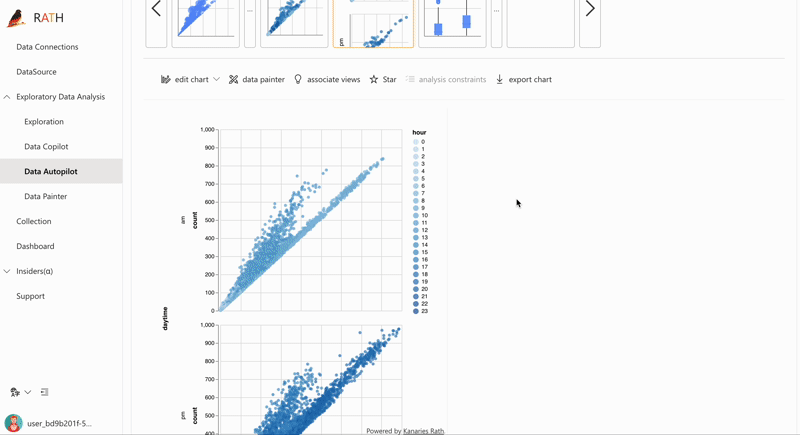 |
| Visualización de datos (opens in a new tab) | Crea visualización de datos multidimensionales basada en el puntaje de efectividad. | 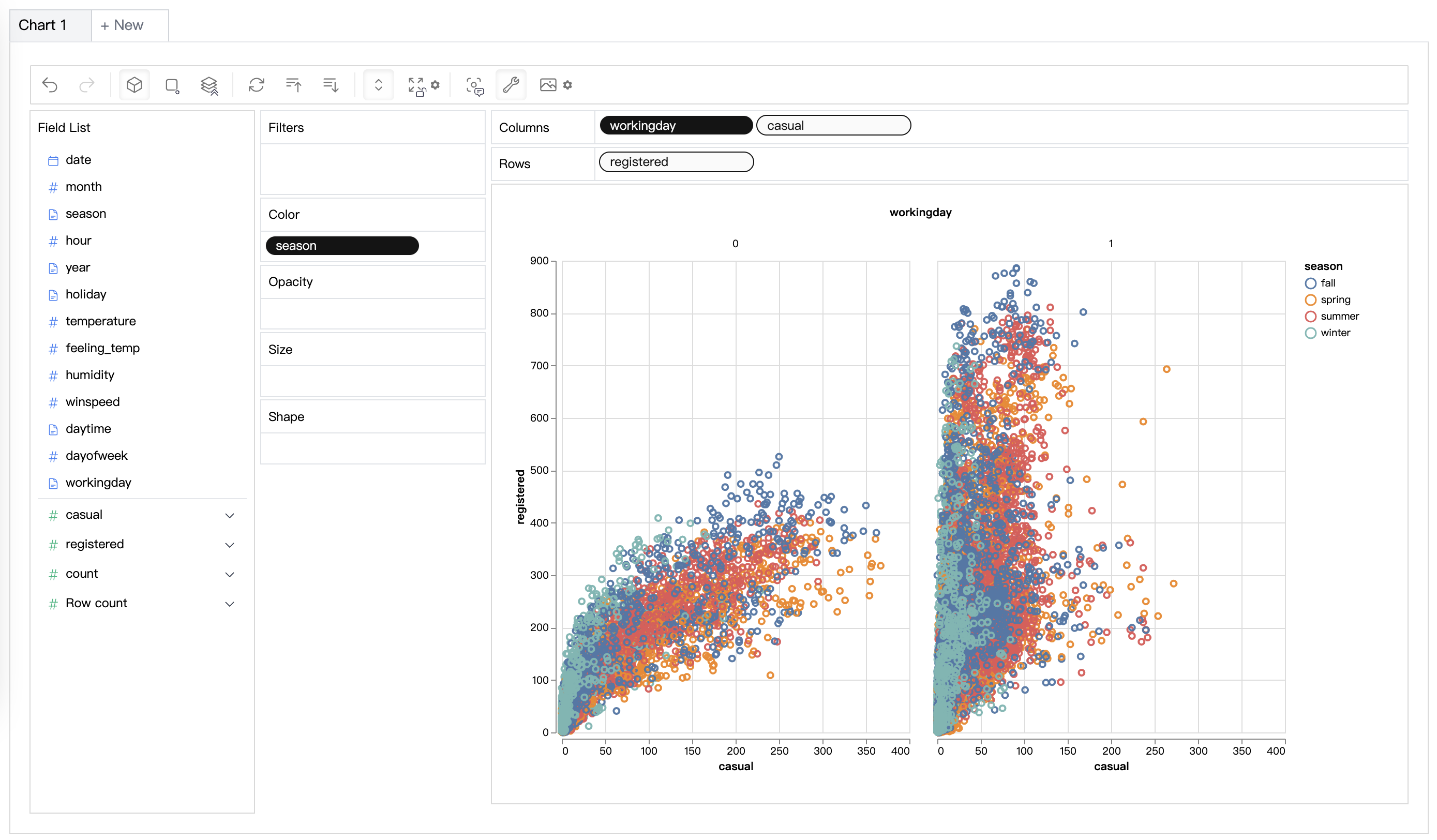 |
| Manipulador de datos (opens in a new tab) | Manipulador de datos automatizado para generar un resumen de los datos y realizar transformación de datos. | 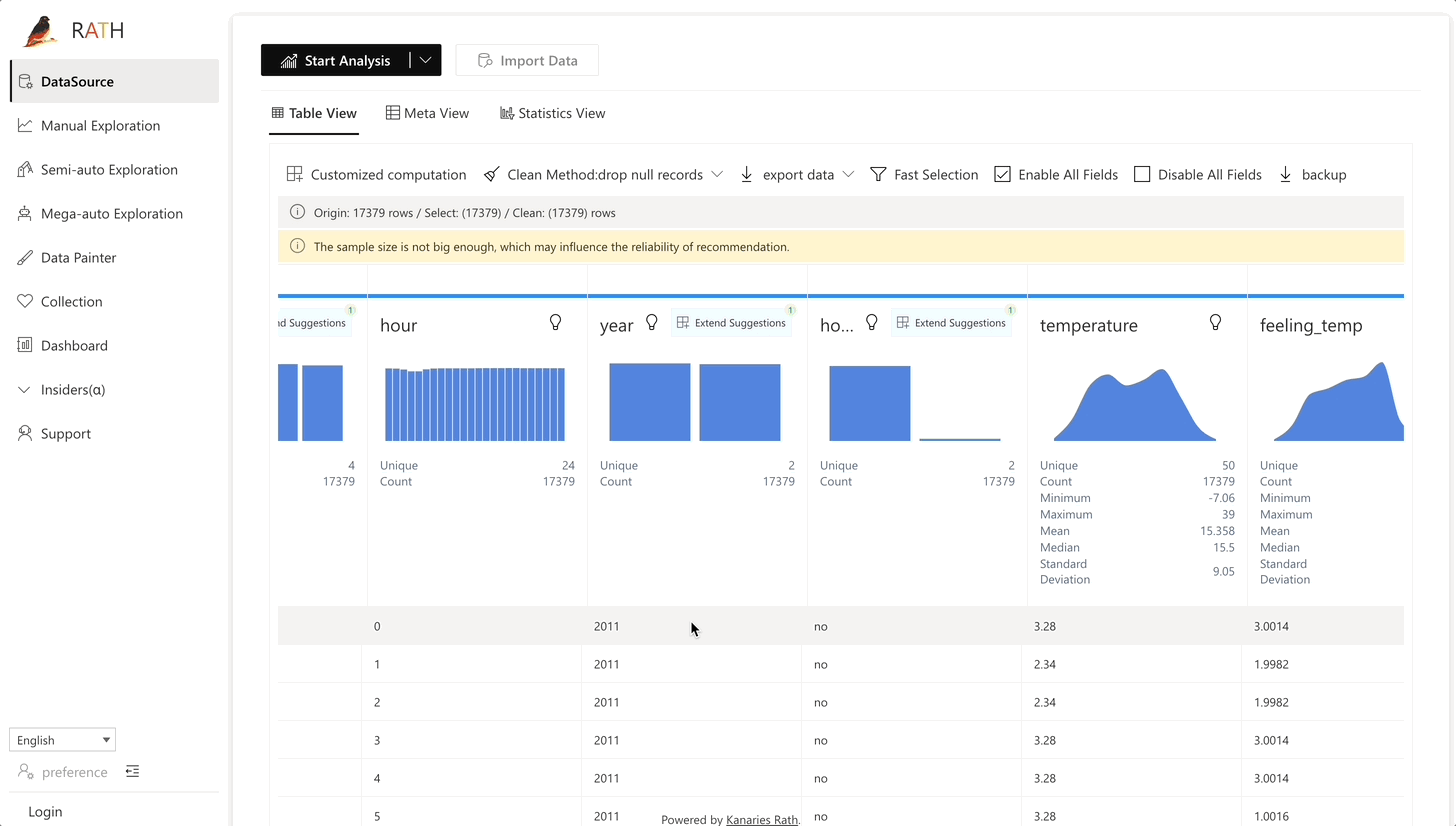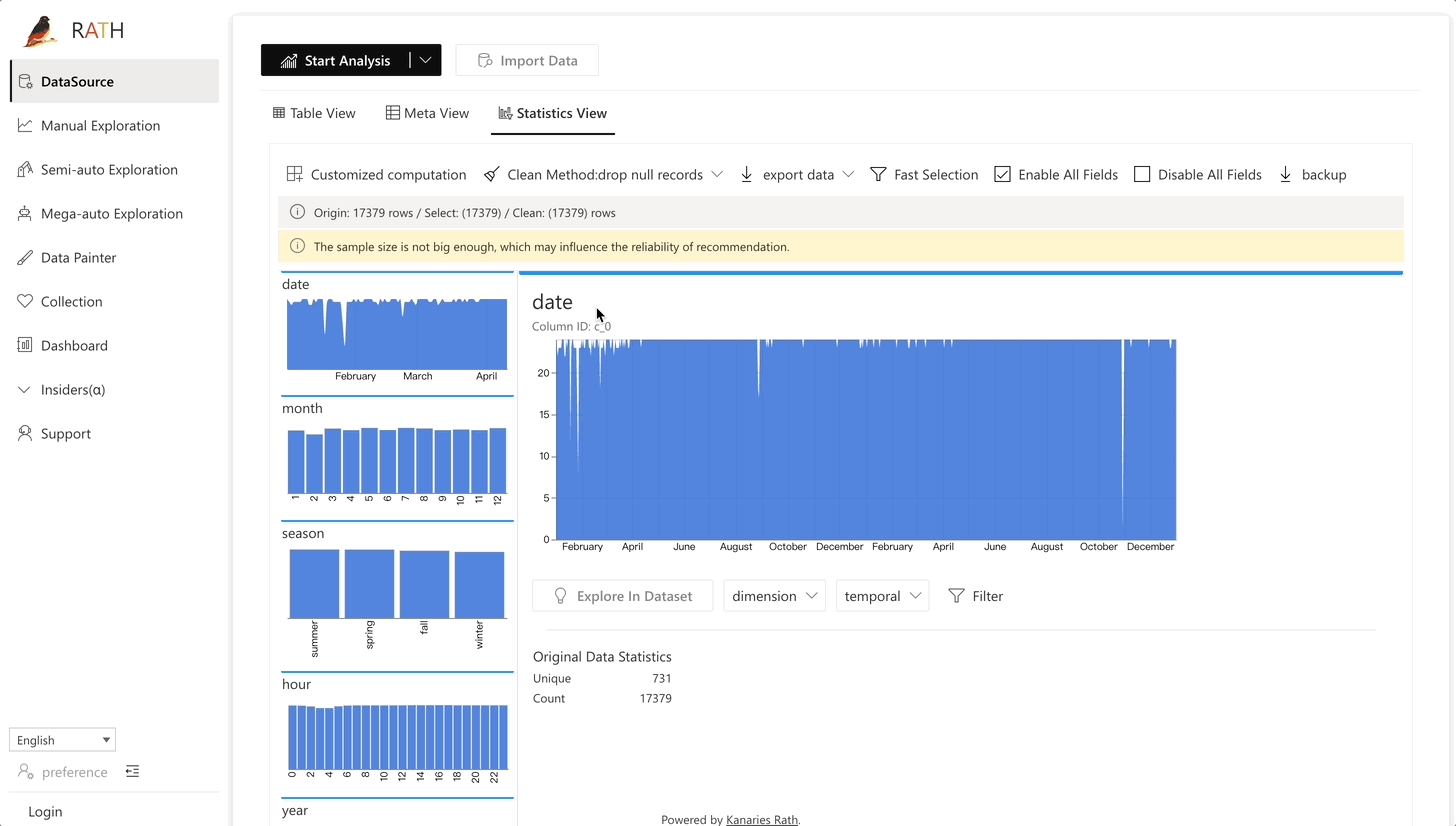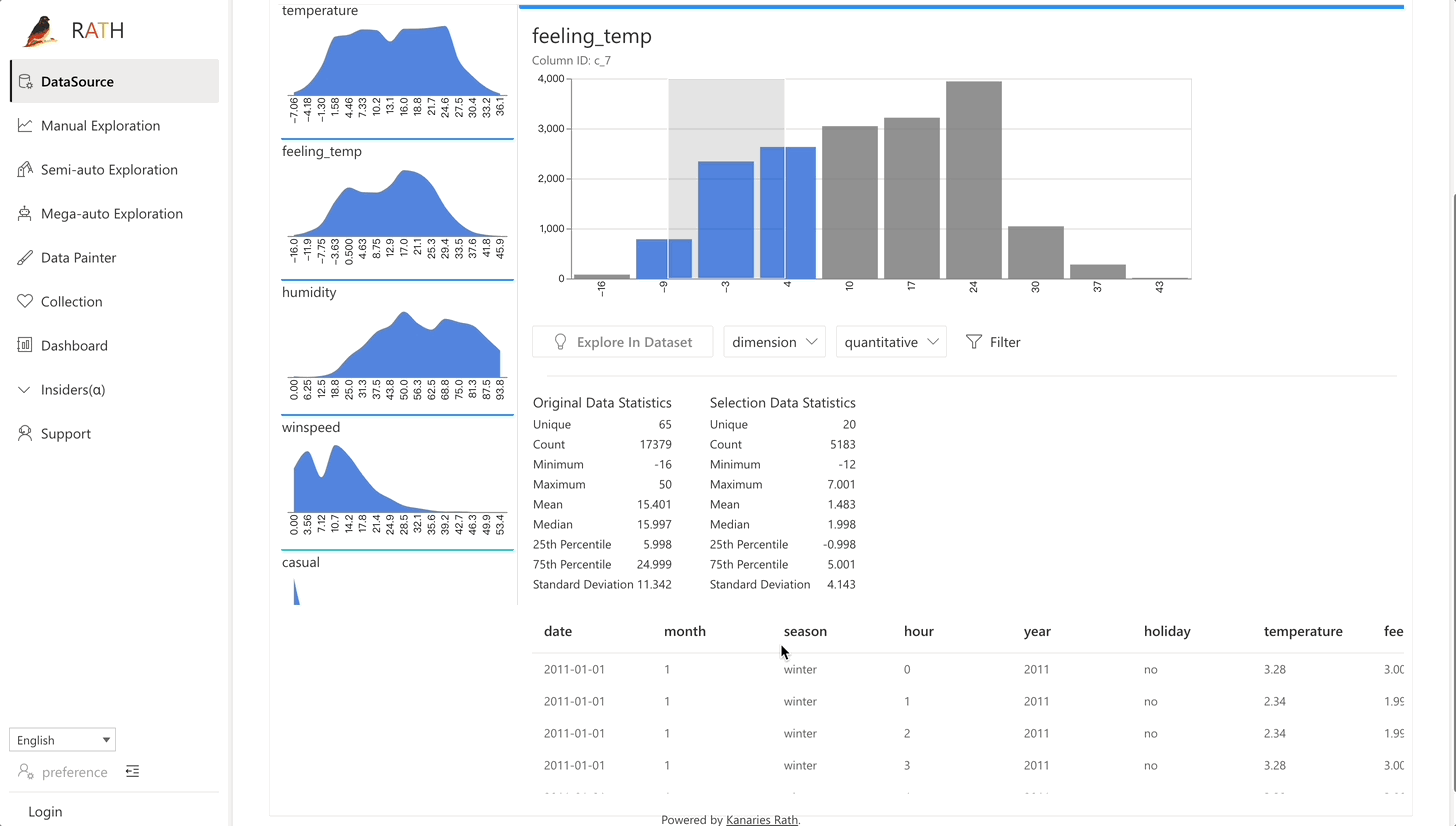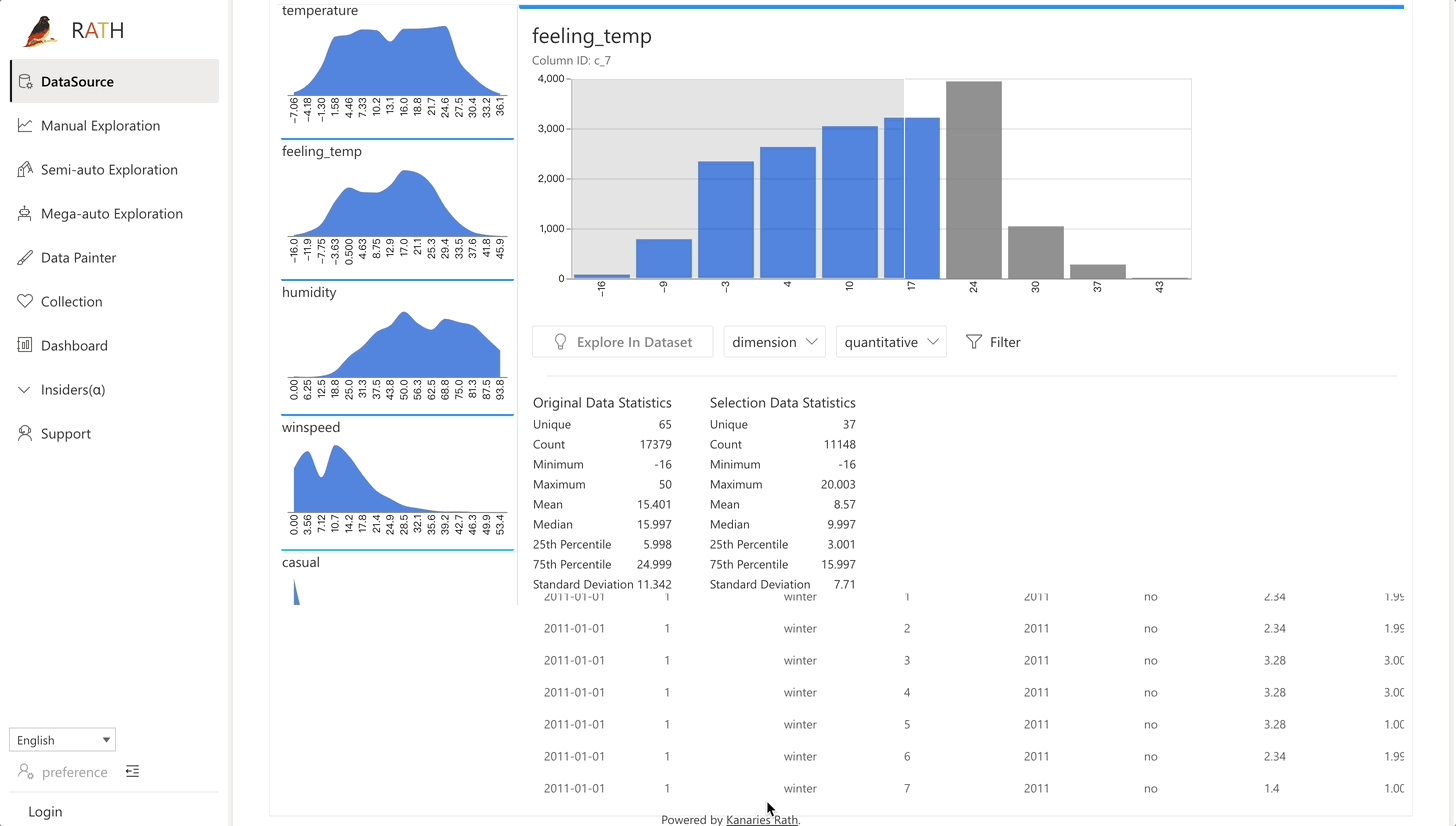 |
| Copiloto de exploración de datos (opens in a new tab) | Combina la exploración automatizada de datos y la exploración manual. RATH funcionará como tu copiloto en ciencia de datos, aprenderá tus intereses y utilizará el motor de análisis aumentado para generar recomendaciones relevantes para ti. |  |
| Data Painter (opens in a new tab) | Una herramienta interactiva, intuitiva y potente para el análisis exploratorio de datos mediante la asignación de colores a los datos, con características analíticas adicionales. | 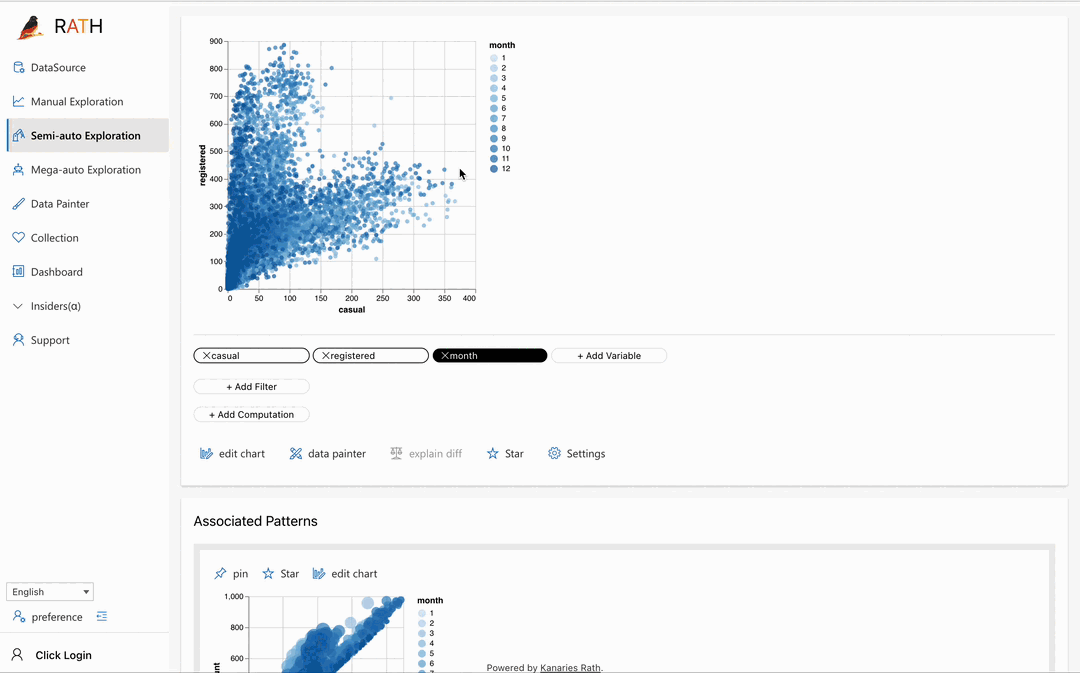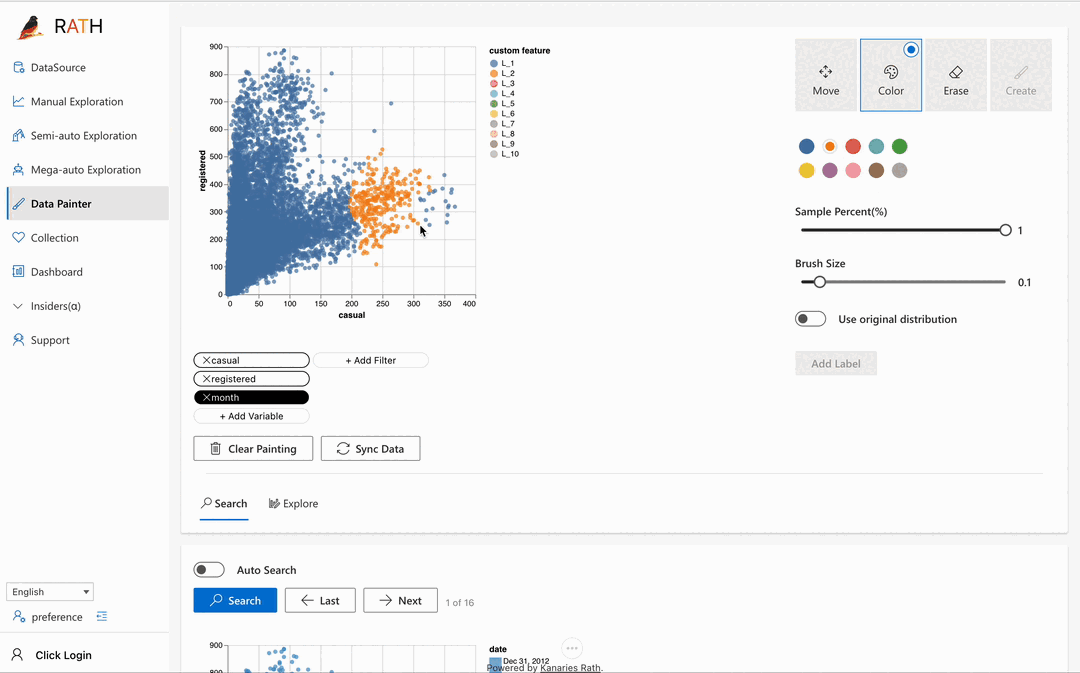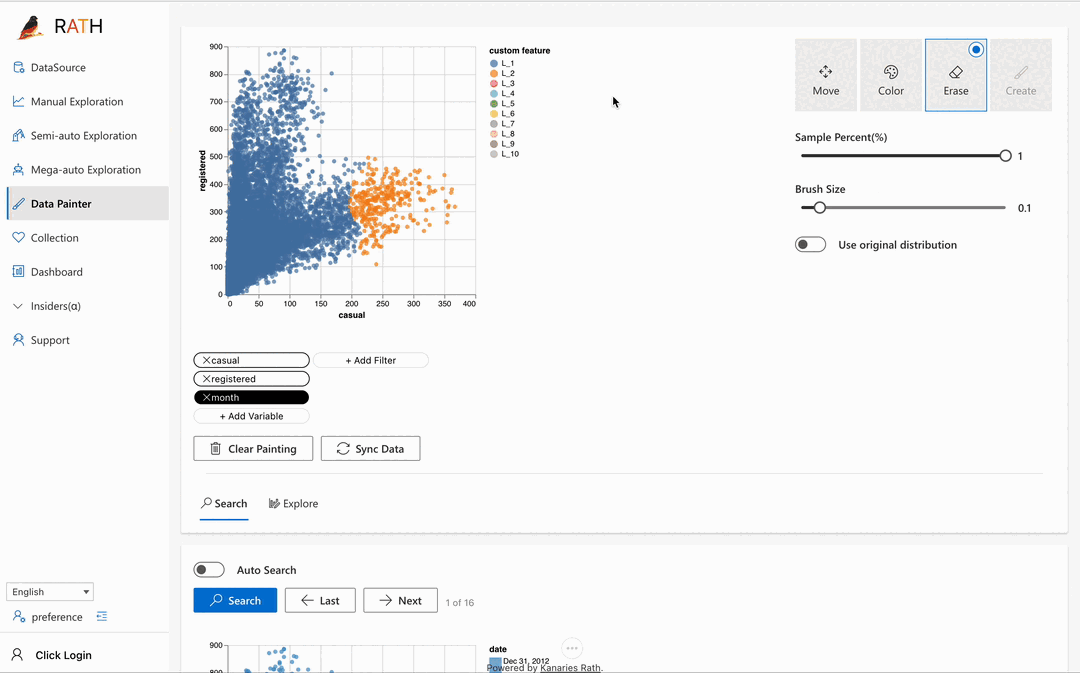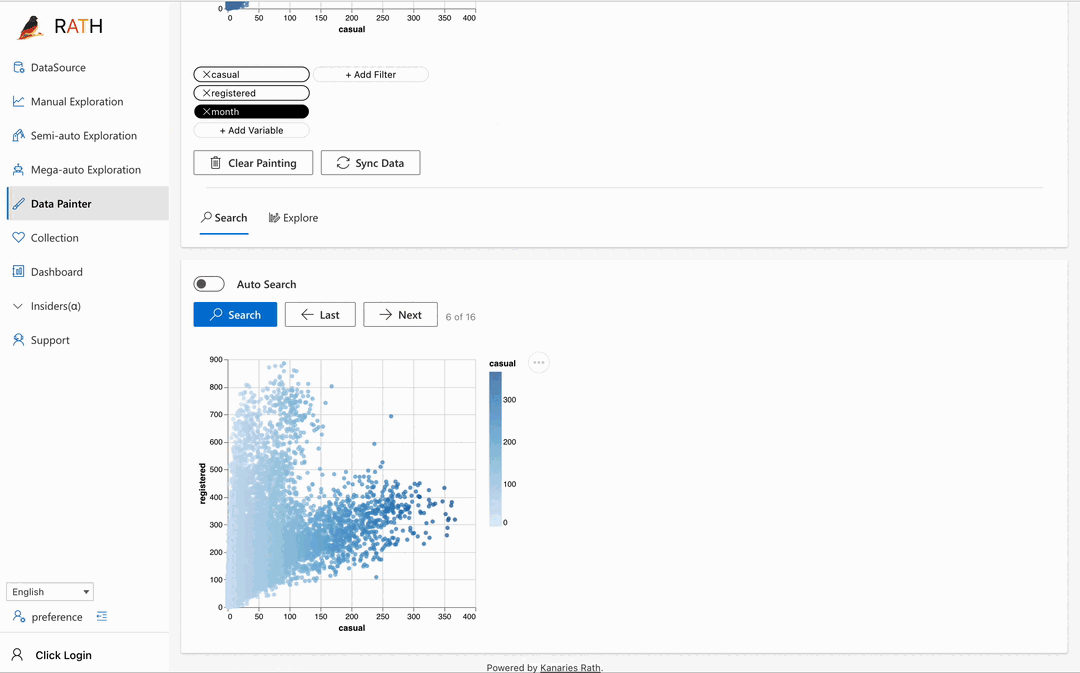 |
| Panel de control | Crea un hermoso panel de control interactivo de datos (incluido un diseñador de panel de control automatizado que puede proporcionar sugerencias para tu panel de control). | 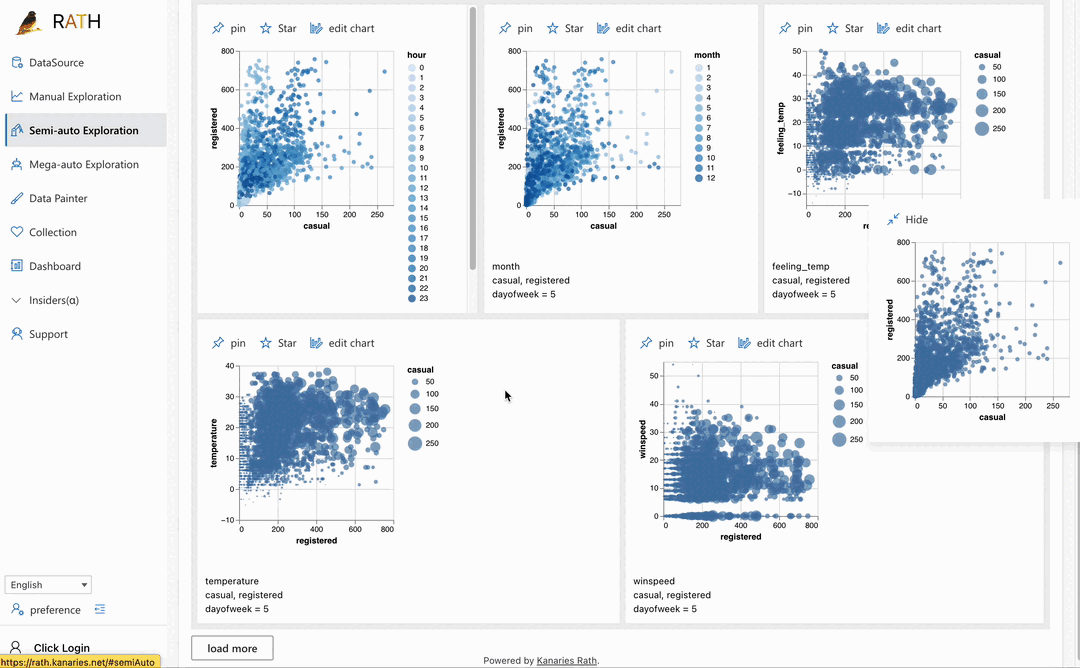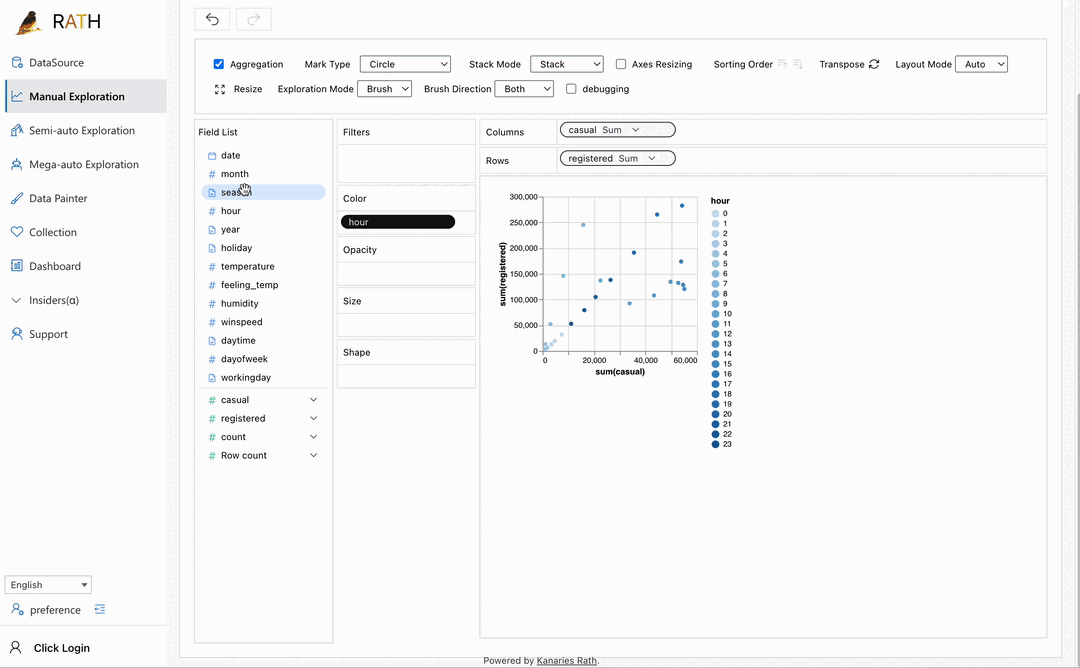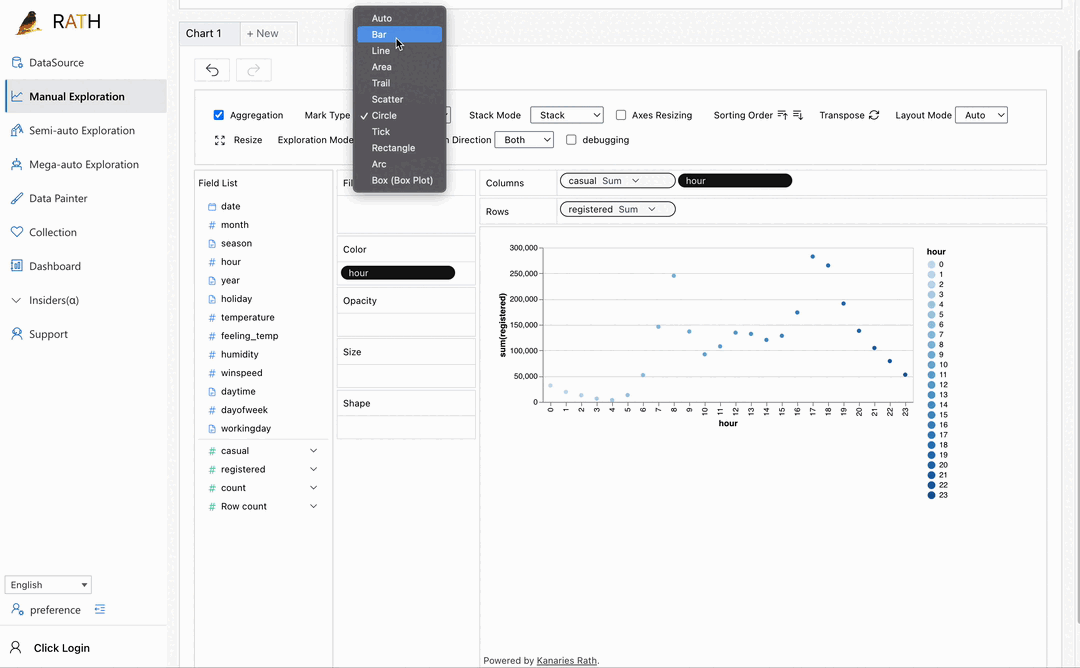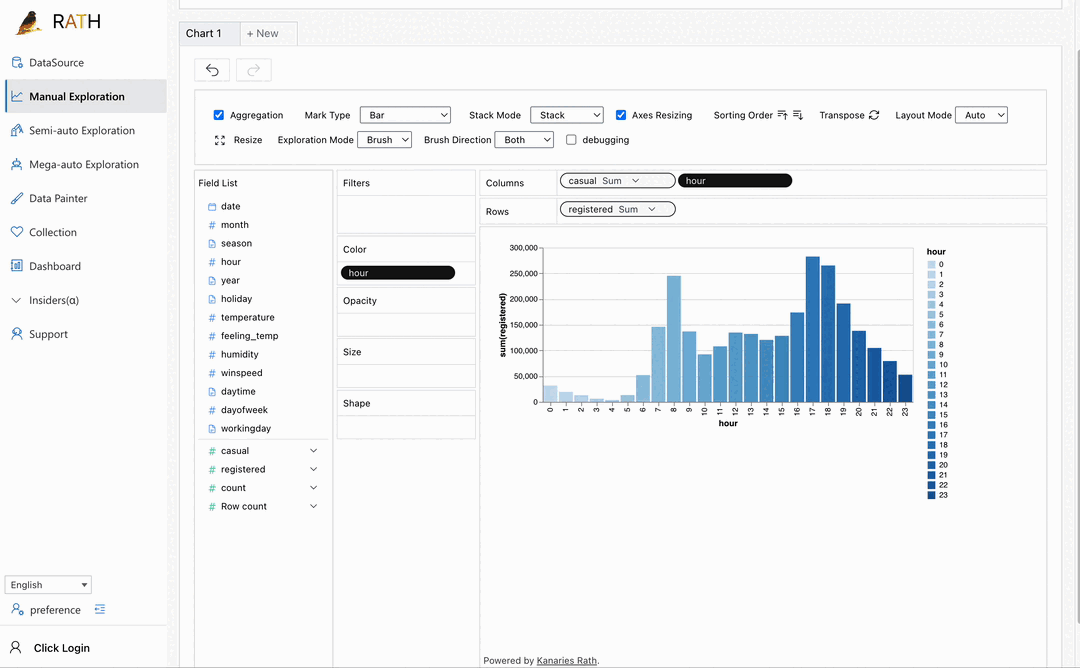 |
| Análisis causal (opens in a new tab) | Proporciona descubrimiento y explicaciones de relaciones causales complejas. | 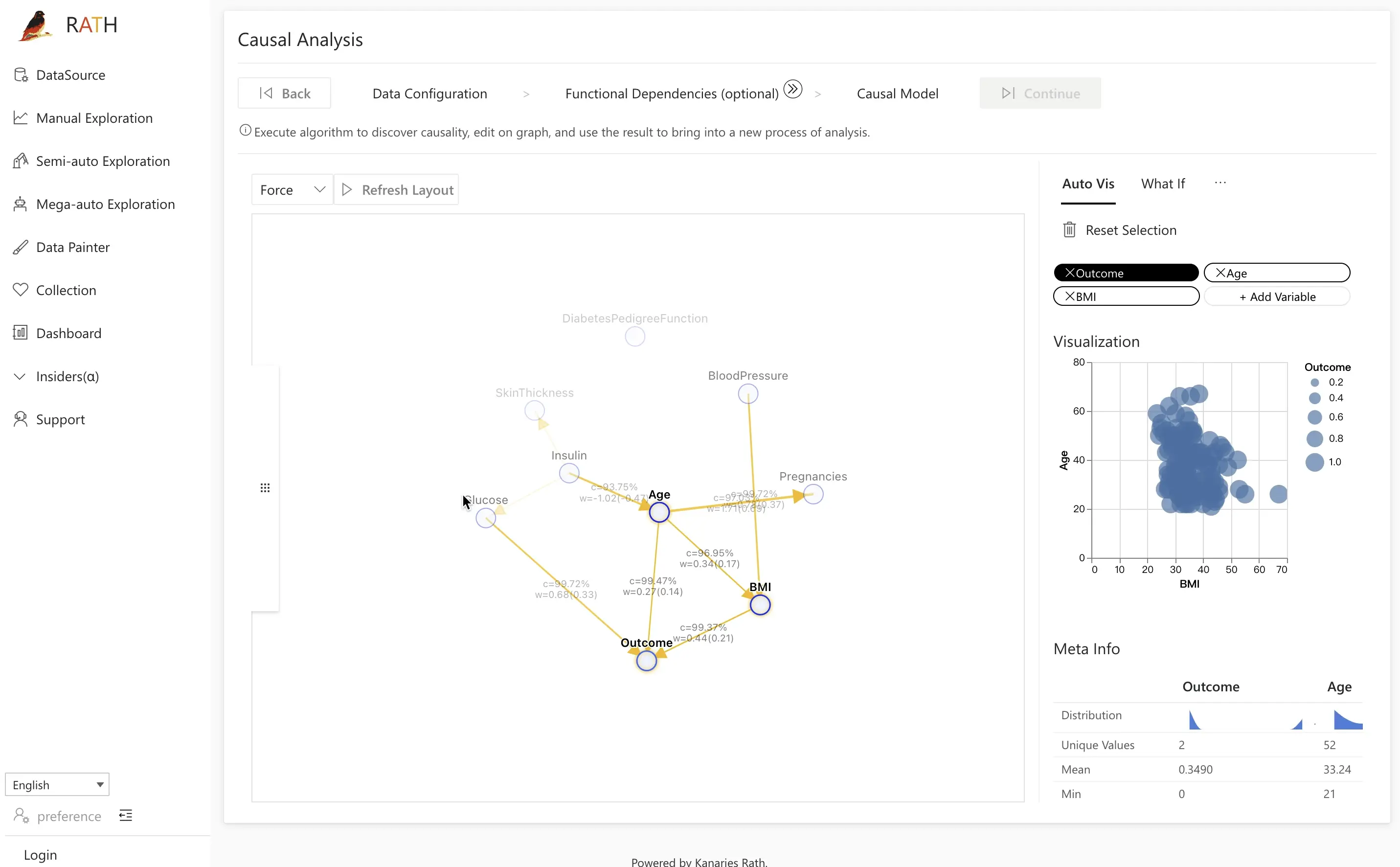 |
Conclusión
En conclusión, ChatGPT es una herramienta poderosa para generar consultas SQL eficientes. Puede generar rápidamente consultas complejas para la agregación, filtrado y optimización de datos, reduciendo el riesgo de errores y ahorrando tiempo al usuario.
Además de las capacidades de ChatGPT para generar consultas SQL eficientes, también existe RATH, una herramienta de código abierto que automatiza el flujo de trabajo del Análisis Exploratorio de Datos (EDA) y proporciona exploración automática de datos, visualización y exploración semiautomática, para hacer que el análisis de datos sea más eficiente y efectivo.