Vicuna-13B: Una Alternativa de Chatbot de Código Abierto que Impresiona a GPT-4

El mundo de los chatbots ha tenido avances significativos en los últimos años gracias al desarrollo de los modelos de lenguaje grande (LLM) como ChatGPT de OpenAI. Sin embargo, los detalles de la arquitectura y el entrenamiento de ChatGPT siguen siendo elusivos, lo que dificulta que investigadores puedan construir sobre sus éxitos. Aquí es donde entra en juego Vicuna. Una alternativa de chatbot de código abierto a ChatGPT que cuenta con un conjunto de datos sólido y una infraestructura escalable. En este artículo, profundizaremos en las capacidades de Vicuna, cómo se desarrolló y su potencial para futuras investigaciones.
¿Qué es Vicuna o Vicuna-13B?
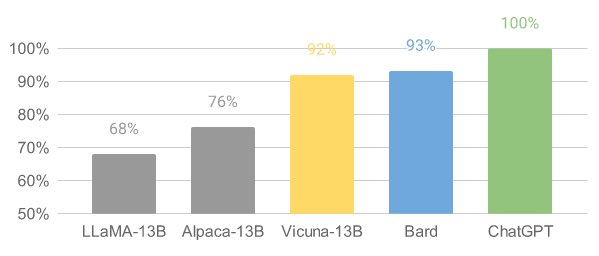
Vicuna (opens in a new tab) es un modelo de chatbot de código abierto llamado Vicuna-13B, creado por un equipo de investigadores de las universidades UC Berkeley, CMU, Stanford y UC San Diego. Se construyó mediante el ajuste fino del modelo LLaMA en conversaciones compartidas por los usuarios de ShareGPT y las evaluaciones preliminares muestran que logra más del 90% de la calidad de ChatGPT. Cabe destacar que el costo de entrenar a Vicuna-13B es de aproximadamente $300.
¿Cómo funciona Vicuna?
Vicuna ha demostrado un rendimiento impresionante en evaluaciones preliminares. Al ajustar finamente Vicuna con 70,000 conversaciones compartidas por los usuarios de ChatGPT, el modelo se vuelve capaz de generar respuestas detalladas y bien estructuradas. Su calidad es comparable a la de ChatGPT y supera otros modelos como LLaMA y Stanford Alpaca en más del 90% de los casos.
Desarrollo de Vicuna: Infraestructura de Entrenamiento y Servicio
El equipo de Vicuna recolectó alrededor de 70,000 conversaciones de ShareGPT.com y mejoró los scripts de entrenamiento proporcionados por Alpaca. Utilizaron PyTorch FSDP en 8 GPUs A100 para entrenar e implementaron un sistema de servicio con distribución liviana. El equipo también realizó una evaluación preliminar de la calidad del modelo creando un conjunto de 80 preguntas diversas y utilizando GPT-4 para juzgar las salidas del modelo.
Para entrenar a Vicuna, el equipo ajustó finamente el modelo base de LLaMA mediante el uso de las conversaciones compartidas por los usuarios. Aseguraron la calidad de los datos convirtiendo HTML a markdown y filtrando muestras inapropiadas o de baja calidad. También realizaron varias mejoras en la receta de entrenamiento, como optimizaciones de memoria, manejo de conversaciones de varias rondas y reducción de costos mediante instancias "spot".
El sistema de servicio construido para Vicuna es capaz de servir a múltiples modelos con trabajadores distribuidos. Admite conectores flexibles para trabajadores GPU tanto en clusters en sitio como en la nube. Al utilizar un controlador tolerante a fallos y una característica administrada de "spot" en SkyPilot, el sistema de servicio puede funcionar bien con instancias más económicas de múltiples nubes, lo que reduce los costos de servicio.
El equipo de Vicuna ha liberado el código de entrenamiento, servicio y evaluación en GitHub (opens in a new tab).
Evaluación de Chatbots con GPT-4
La evaluación de chatbots es una tarea difícil, pero el equipo de Vicuna propone un marco de evaluación basado en GPT-4 para automatizar la evaluación del rendimiento de los chatbots. Diseñaron ocho categorías de preguntas para probar varios aspectos del rendimiento de chatbots y descubrieron que GPT-4 puede producir puntuaciones relativamente consistentes y explicaciones detalladas de esas puntuaciones. Sin embargo, este marco de evaluación propuesto aún no es un enfoque riguroso, ya que los modelos de lenguaje grande como GPT-4 son propensos a la alucinación. Desarrollar un sistema de evaluación riguroso y estandarizado para chatbots sigue siendo una pregunta abierta que requiere más investigación.
Limitaciones y Futuras Investigaciones
Vicuna, como otros modelos de lenguaje grande, tiene limitaciones en tareas que involucran razonamiento o matemáticas. También puede tener dificultades para identificarse con precisión o garantizar la precisión factual de sus salidas. Además, no se ha optimizado suficientemente para la seguridad, la mitigación de la toxicidad o el sesgo.
No obstante, Vicuna sirve como un punto de partida abierto para futuras investigaciones para abordar estas limitaciones, junto con otros últimos avances en el campo de la inteligencia artificial, como Auto-GPT y LongChain.
Preguntas frecuentes
-
¿Cómo puedo obtener y usar los pesos del modelo Vicuna 13-b? Para usar el modelo Vicuna 13-b, necesitas descargar el modelo original LLaMa 13B y aplicar los pesos delta proporcionados por el equipo de Vicuna. Los pesos delta se pueden encontrar en https://huggingface.co/lmsys/vicuna-13b-delta-v0 (opens in a new tab).
-
¿Cómo aplico los pesos delta al modelo LLaMa 13B? Puedes aplicar los pesos delta siguiendo el comando en el repositorio de FastChat: python3 -m fastchat.model.apply_delta --base /path/to/llama-13b --target /output/path/to/vicuna-13b --delta lmsys/vicuna-13b-delta-v0. Este comando descargará y aplicará automáticamente los pesos delta al modelo base.
-
¿Puedo convertir el modelo Vicuna 13-b al formato llama.cpp/gpt4all? Sí, el modelo Vicuna 13-b se puede cuantificar al formato llama.cpp/gpt4all. El modelo solo ajusta ligeramente los pesos existentes, sin cambiar la estructura.
-
¿Existen problemas de licencia al usar Vicuna 13-b? El equipo de Vicuna realiza los pesos como pesos delta para cumplir con la licencia del modelo LLaMa. Sin embargo, el uso del modelo para fines comerciales aún puede ser una mala idea debido a posibles complicaciones legales.