Una introducción a PyGWalker: Potencia tus visualizaciones de Streamlit
PyGWalker (opens in a new tab) es una librera excepcional de Python que transforma los dataframes de Python en una interfaz intuitiva tipo tableau, haciendo que la visualización de datos sea muy sencilla.
Tradicionalmente utilizado en Jupyter para ayudar a los científicos de datos a sumergirse en sus conjuntos de datos, la versatilidad de PyGWalker brilla cuando se combina con Streamlit. El encanto de Streamlit reside en su capacidad de construir aplicaciones de datos sin esfuerzo sin necesidad de conocimientos en tecnologías frontend o backend. En pocas palabras, puedes crear y compartir paneles de control sin complicaciones.
La integración de PyGWalker (opens in a new tab) con Streamlit te permite establecer tu propio "tableau web". Esto permite compartir paneles de control y permite a los usuarios explorar libremente con la intuitiva interfaz de arrastrar y soltar de PyGWalker (opens in a new tab). Las actualizaciones recientes también han introducido una función de "chat-a-gráficos", que se activa simplemente añadiendo una clave de API.
Lo que distingue a PyGWalker (opens in a new tab) es su diseño nativo en la nube. Con su capacidad para conectarse a una multitud de bases de datos en la nube, OLAP o DW, garantiza una experiencia de alto rendimiento, superando muchas costosas herramientas tradicionales de inteligencia empresarial.
¿Listo para crear un PyGWalker (opens in a new tab) basado en la nube con Streamlit? Vamos a sumergirnos.
Configuración de Dependencias:
pip install pygwalker
pip install streamlitPara este tutorial, utilizaremos un conjunto de datos de terremotos, que se puede cargar desde un archivo CSV.
def obtener_df() -> pd.DataFrame:
df = pd.read_csv("./Significant Earthquake_Dataset_1900_2023.csv")
df["Time"] = pd.to_datetime(df["Time"]).dt.strftime('%Y-%m-%d %H:%M:%S')
return dfUna vez cargado, alimenta el conjunto de datos a PyGWalker:
from pygwalker.api.streamlit import obtener_html_streamlit
html = obtener_html_streamlit(df, usar_calculo_kernel=True, especif="./espec/geo_vis.json", depuración=False)Ahora, simplemente renderiza el HTML de PyGWalker usando Streamlit:
import streamlit.components.v1 as componentes
componentes.html(obtener_html_pyg(df), ancho=1300, altura=1000, desplazamiento=True)Pon en funcionamiento tu aplicación:
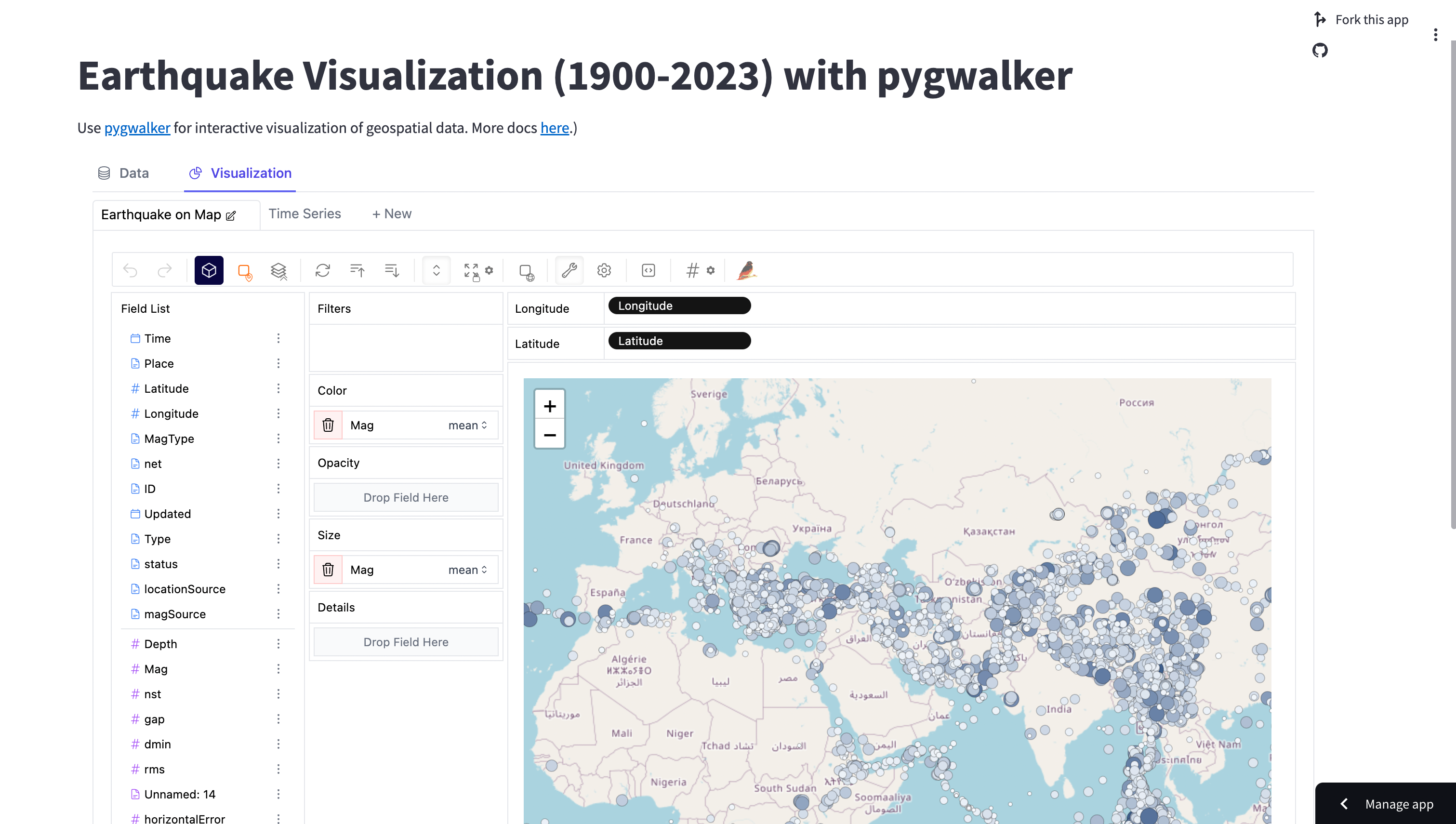
Potencia tus consultas con el nuevo motor de PyGWalker
Desde la versión 0.3, PyGWalker ha incorporado el motor de cálculo basado en DuckDB, asegurando consultas de datos más rápidas, incluso con conjuntos de datos extensos.
Para activar esto, simplemente añade el parámetro usar_calculo_kernel:
pyg.caminar(df, usar_calculo_kernel=True)Si bien esto funciona sin problemas en entornos como Jupyter, Streamlit impone ciertos límites de transferencia de datos entre el frontend y el backend. Sin embargo, gracias al equipo de desarrollo de Kanaries (opens in a new tab), hay una solución sencilla:
from pygwalker.api.streamlit import iniciar_comunicacion_streamlit
iniciar_comunicacion_streamlit()Conclusión
Combinar PyGWalker con Streamlit abre el camino para crear aplicaciones de visualización de datos interactivas en línea dinámicas con un código mínimo. ¡Sumérgete y transforma tus exploraciones de datos hoy mismo!