Pandas에서 피벗 테이블을 손쉽게 만드는 방법

피벗 테이블이란 무엇인가요?
피벗 테이블은 데이터 분석에 사용되는 데이터 요약 도구입니다.데이터를 행에서 열로 또는 그 반대로 변환하고 데이터에 대한 계산을 수행할 수 있습니다.피벗 테이블은 대규모 데이터세트를 요약하고 분석하는 데 유용하므로 패턴과 추세를 쉽게 식별할 수 있습니다.
데이터 분석에서 피벗 테이블을 사용할 때의 이점
피벗 테이블은 데이터 분석에서 다음과 같은 많은 이점을 제공합니다.
- 유연성: 피벗 테이블을 쉽게 조정하여 다양한 데이터 차원을 분석할 수 있습니다.사용자는 행, 열 및 필터를 추가, 제거 또는 재구성하여 데이터에 대한 다양한 통찰력을 얻을 수 있습니다.
- 효율성: 피벗 테이블은 대량의 데이터를 빠르게 요약할 수 있으므로 데이터를 더 쉽게 분석하고 데이터에서 통찰력을 얻을 수 있습니다.
- 집계: 피벗 테이블은 합계, 개수, 평균 등을 포함하여 데이터에 대한 복잡한 계산을 수행할 수 있습니다.
- 시각화: 피벗 테이블은 데이터를 시각적으로 매력적인 방식으로 표시하여 통찰력을 더 쉽게 해석하고 다른 사람에게 전달할 수 있습니다.
Pandas에서 피벗 테이블 만들기
피벗 테이블을 만들기 위한 기본 구문
Pandas에서 피벗 테이블을 만들려면 pivot () 메서드를 사용할 수 있습니다.피벗 테이블을 만드는 기본 구문은 다음과 같습니다. 코드_블록_플레이스홀더_0
팬더스에서 pivot_table () 메서드 사용하기
팬더에서 피벗 테이블을 만드는 또 다른 방법은 pivot_table () 메서드를 사용하는 것입니다.이 방법을 사용하면 유연성이 향상되고 더 복잡한 계산을 수행할 수 있습니다.pivot_table () 메서드를 사용하기 위한 기본 구문은 다음과 같습니다. 코드_블록_플레이스홀더_1
Pandas의 피벗 테이블 예제
1.멀티 레벨 피벗 테이블
다중 레벨 피벗 테이블은 둘 이상의 행 또는 열 레이블이 있는 피벗 테이블입니다.이렇게 하면 여러 가지 방법으로 데이터를 그룹화하고 요약할 수 있습니다.다음은 Pandas에서 다단계 피벗 테이블을 만드는 예입니다. 코드_블록_플레이스홀더_2
2.집계 없는 피벗 테이블
때로는 집계를 수행하지 않고 피벗 테이블을 만들고 싶을 수 있습니다.이는 고유 값 테이블을 만들거나 데이터 분포를 확인하는 데 유용합니다.다음은 집계 없이 피벗 테이블을 만드는 예입니다. 코드_블록_플레이스홀더_3
3.여러 열이 있는 피벗 테이블
여러 열로 구성된 피벗 테이블을 만들 수도 있습니다.이렇게 하면 여러 데이터 열에 대해 계산을 수행할 수 있습니다.다음은 여러 열로 구성된 피벗 테이블을 만드는 예입니다. 코드_블록_플레이스홀더_4
4.피벗 테이블을 Excel로 내보내기
Pandas에서 피벗 테이블을 만든 후에는 추가 분석 또는 다른 사람들과 공유하기 위해 Excel로 내보낼 수 있습니다.팬더를 사용하면 to_excel () 메서드를 사용하여 피벗 테이블을 Excel로 쉽게 내보낼 수 있습니다.
to_excel () 메서드는 데이터프레임을 엑셀 파일로 내보냅니다.기본적으로 메서드는 Excel 파일의 첫 번째 시트에 DataFrame을 기록하지만 sheet_name 매개 변수를 사용하여 시트 이름을 지정할 수 있습니다.float_format, 헤더 및 인덱스와 같은 추가 매개 변수를 전달하여 Excel 파일의 형식을 사용자 지정할 수도 있습니다.
피벗 테이블을 엑셀로 내보내려면, pivot_table () 메서드에서 반환된 DataFrame에서 to_excel () 메서드를 호출하면 됩니다.다음은 예시입니다.
코드_블록_플레이스홀더_5
이 예시에서는 판매 데이터가 포함된 CSV 파일을 DataFrame으로 읽습니다.그런 다음 pivot_table () 메서드를 사용하여 인덱스를 'Region', 열을 'Product', 값을 'Sales'로 설정하고 집계 함수를 'sum'으로 설정하여 피벗 테이블을 만듭니다.마지막으로 피벗 테이블을 'sales_pivot_table.xlsx'라는 이름의 엑셀 파일로 내보냅니다.
기본적으로 to_excel () 메서드는 데이터 값과 함께 행 및 열 레이블을 Excel 파일에 씁니다.행 또는 열 레이블을 제외하려면 인덱스 또는 열 매개 변수를 각각 False로 설정할 수 있습니다.
코드_블록_플레이스홀더_6
또한 float_format, 헤더 및 인덱스와 같은 다른 매개 변수를 사용하여 Excel 파일의 형식을 사용자 지정할 수 있습니다.예를 들어 float_format 매개 변수를 사용하여 데이터 값에 표시할 소수점 자릿수를 지정할 수 있습니다.
코드_블록_플레이스홀더_7
PygWalker를 사용하여 파이썬 팬더에서 피벗 테이블을 시각화하세요
Python Pandas 내에서 데이터를 시각화하고 싶다면 Pygwalker (opens in a new tab) 라는 오픈 소스 데이터 분석 및 데이터 시각화 패키지를 이용해 보세요.PygWalker는 주피터 노트북 데이터 분석 및 데이터 시각화 워크플로를 단순화할 수 있습니다.Python을 사용하여 데이터를 분석하는 대신 가볍고 사용하기 쉬운 인터페이스를 제공합니다.
피그워커는 오픈 소스입니다.PygWalker GitHub 페이지 (opens in a new tab) 에서 확인하고 해당 문서의 데이터 과학을 향하여 (opens in a new tab) 를 읽을 수 있습니다.
PygWalker를 지금 테스트하려면 구글 콜랩 (opens in a new tab), 바인더 (opens in a new tab) 또는 Kaggle (opens in a new tab) 에서 PygWalker를 실행할 수 있습니다.
PygWalker를 시작하려면 피그워커와 판다를 Jupyter 노트북으로 가져오세요. 코드_블록_플레이스홀더_8 기존 워크플로를 변경하지 않고 pygwalker를 사용할 수 있습니다.예를 들어 다음과 같이 로드된 데이터프레임을 사용하여 그래픽 워커를 호출할 수 있습니다. 코드_블록_플레이스홀더_9 이제 Pandas 데이터프레임을 내보내고 사용자 친화적인 UI로 테이블을 시각화할 수 있습니다!
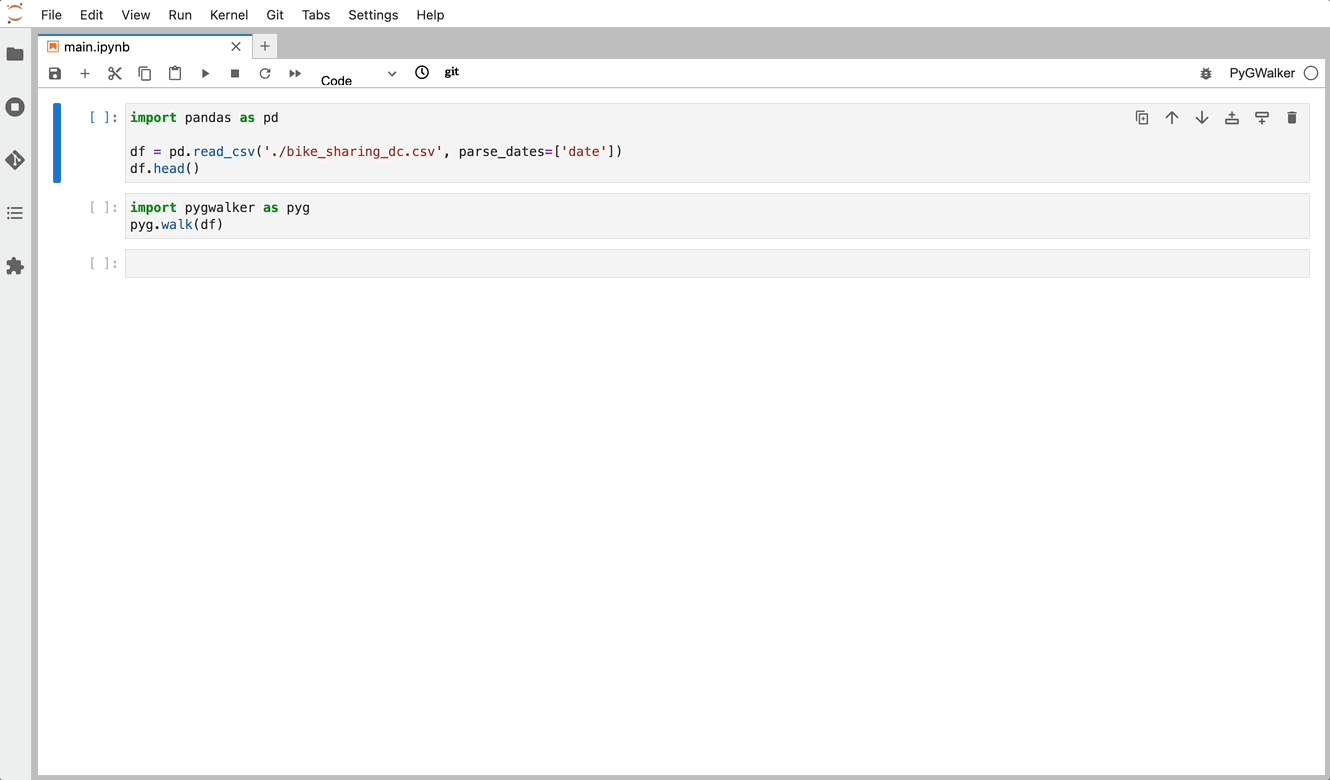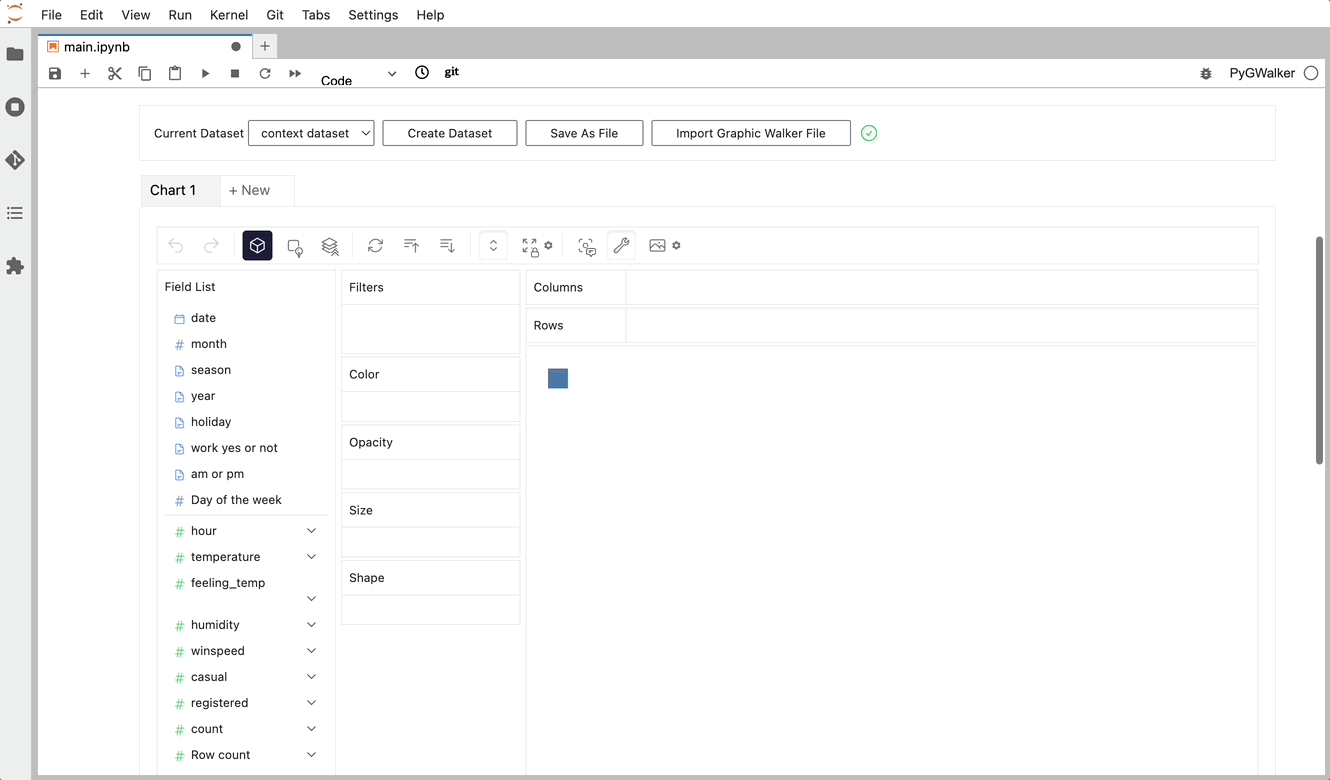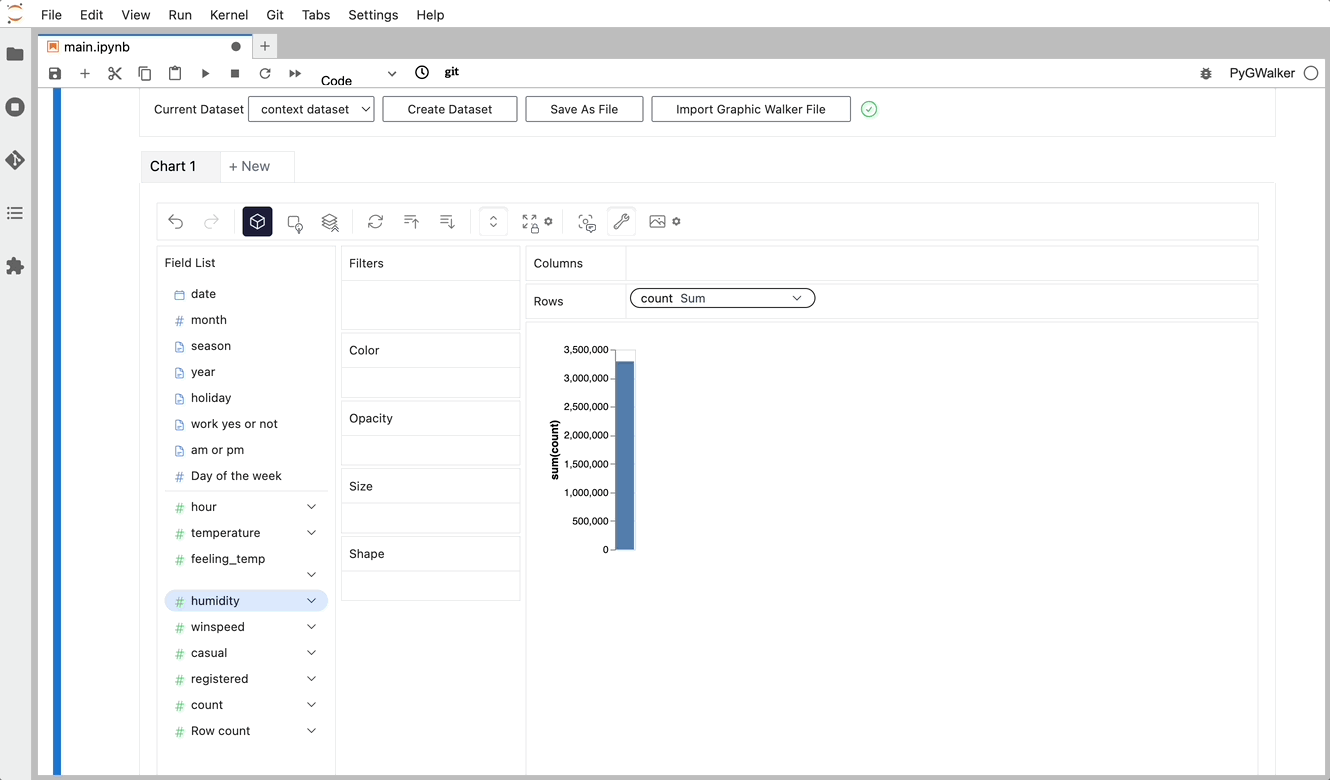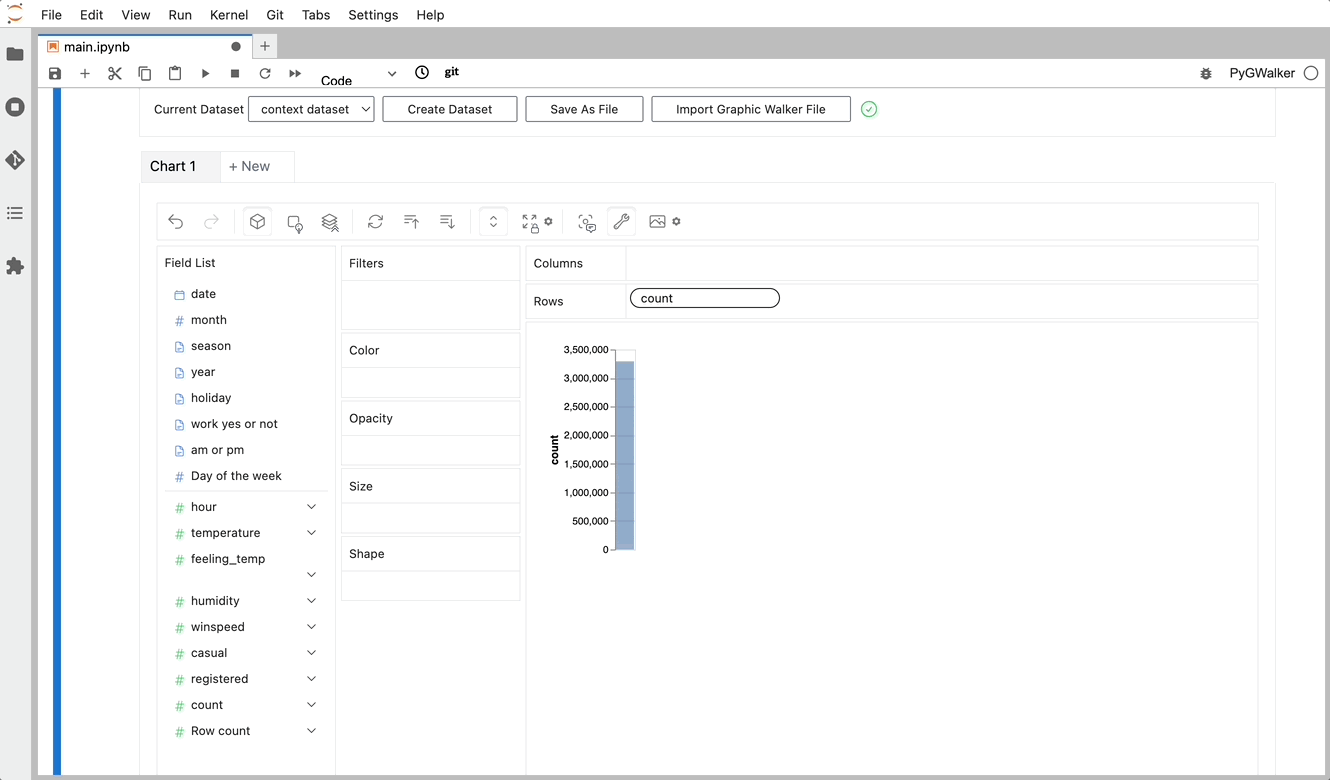
단순히 데이터를 시각화하는 것 외에도 시각화를 클릭하기만 하면 자동으로 생성된 통찰력을 얻어 데이터 탐색에 PygWalker를 사용할 수도 있습니다.
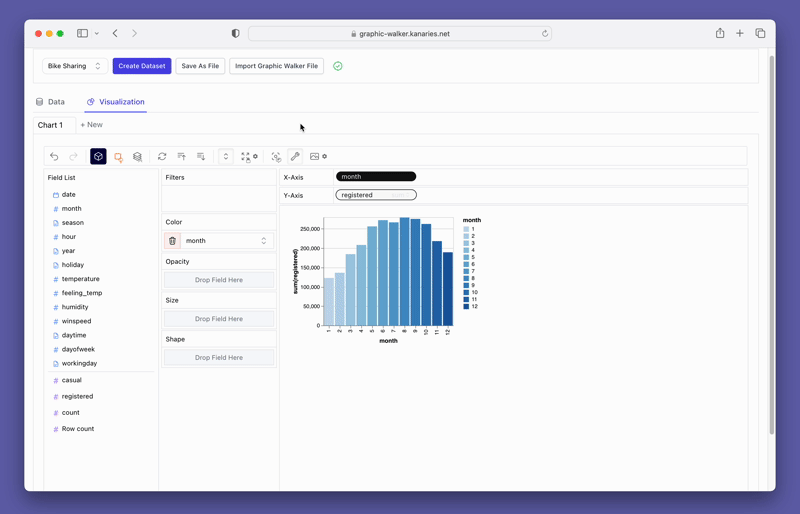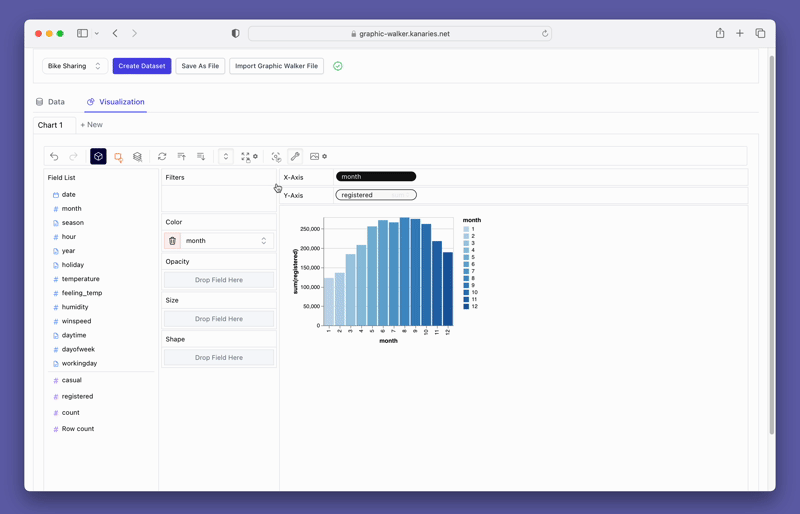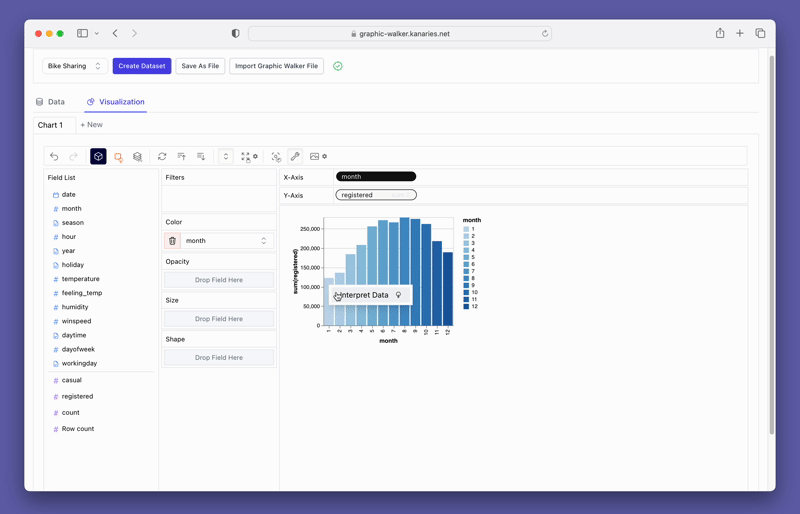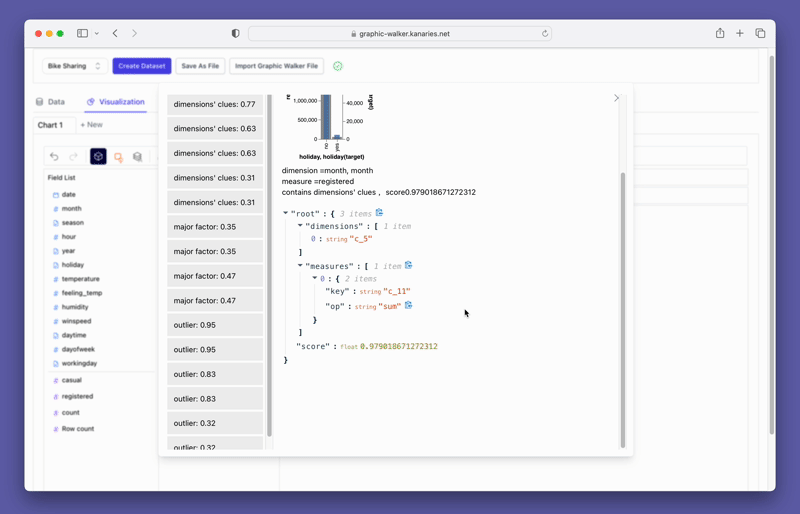
더 발전된 AI 기반 자동 데이터 분석 도구인 RATH (opens in a new tab) 를 확인하는 것도 잊지 마세요.RATH는 또한 오픈 소스이며 GitHub의 소스 코드 (opens in a new tab) 를 호스팅합니다.
결론
이 기사에서는 데이터 분석에서 CSV 파일의 중요성과 Pandas에서 피벗 테이블을 만드는 방법에 대해 설명했습니다.피벗 테이블을 만드는 기본 구문, pivot_table () 메서드를 사용하는 방법 및 Pandas에서 다양한 유형의 피벗 테이블 예제를 다루었습니다.또한 피벗 테이블 및 사용자 지정 방법에 대한 몇 가지 일반적인 질문에 답변했습니다.
이 기사가 Pandas의 피벗 테이블 세계를 소개하는 데 도움이 되었기를 바랍니다.공식 Pandas 문서와 다양한 온라인 강좌 및 튜토리얼을 포함하여 학습 여정을 계속하는 데 도움이 되는 많은 자료가 온라인에 있습니다.피벗 테이블을 계속 탐색하고 실험하여 데이터에 대한 새로운 통찰력을 얻으세요.