Pandas에서 CSV 파일을 읽는 방법 - 초보자를 위한 필수 가이드

데이터 과학자라면 다양한 형식의 대규모 데이터세트를 다룰 것입니다.데이터를 저장하는 데 가장 많이 사용되는 형식 중 하나는 CSV (쉼표로 구분된 값) 파일입니다.이 글에서는 데이터 조작 및 분석을 위한 인기 있는 Python 라이브러리인 Pandas에서 CSV 파일을 읽는 방법을 보여드리겠습니다.
판다는 무엇인가요?
Pandas (opens in a new tab) 는 사용하기 쉬운 데이터 구조와 데이터 분석 도구를 제공하는 오픈 소스 파이썬 라이브러리입니다.NumPy 라이브러리 위에 구축되었으며 CSV, Excel, SQL 데이터베이스 등 다양한 형식의 데이터와 함께 작동하도록 설계되었습니다.
팬더에서 CSV 파일 읽기
팬더에서 CSV 파일을 읽으려면 read_csv () 함수를 사용합니다.예를 들면 다음과 같습니다.
코드_블록_플레이스홀더_0
이 코드는 data.csv라는 CSV 파일을 읽고 이를 df라는 판다스 데이터프레임에 저장합니다.read_csv () 함수는 열의 데이터 유형을 자동으로 유추하고 추가 분석에 사용할 수 있는 DataFrame 객체를 만듭니다.
열 선택
CSV 파일에서 특정 열만 읽어야 하는 경우 usecols 매개 변수를 사용하여 읽을 열 이름 또는 인덱스 목록을 지정할 수 있습니다.예를 들면 다음과 같습니다.
코드_블록_플레이스홀더_1
이 코드에서는 CSV 파일의 col1 및 col2 열만 읽습니다.
열 및 행 건너뛰기
경우에 따라 Pandas에서 CSV 파일을 읽는 동안 특정 열이나 행을 건너뛰고 싶을 수 있습니다.read_csv () 함수의 usecols 및 skiprows 매개 변수를 사용하여 이 작업을 수행할 수 있습니다.
usecols 매개 변수는 CSV 파일에서 읽을 열을 지정하는 데 사용됩니다.열 이름 또는 열 인덱스 목록을 사용할 수 있습니다.
코드_블록_플레이스홀더_2
이 예에서는 이름이 열 1과 열 3인 열만 CSV 파일에서 읽습니다.
skiprows 매개 변수는 CSV 파일을 읽는 동안 특정 수의 행을 건너뛰는 데 사용됩니다.건너뛸 행 수 또는 건너뛸 행 인덱스 목록을 지정하는 정수 값을 사용할 수 있습니다.
코드_블록_플레이스홀더_3
이 예에서는 CSV 파일의 처음 두 행을 읽는 동안 건너뛰게 됩니다.
데이터 유형 지정
기본적으로 Pandas는 CSV 파일을 읽을 때 열의 데이터 유형을 유추합니다.그러나 dtype 매개 변수를 사용하여 데이터 유형을 수동으로 지정할 수도 있습니다.예를 들면 다음과 같습니다.
코드_블록_플레이스홀더_4
이 코드에서는 col1은 정수, col2는 부동 소수점, col3은 문자열이어야 한다고 지정합니다.
인코딩 문제
경우에 따라 CSV 파일에는 Pandas에서 읽을 때 문제가 발생할 수 있는 인코딩 문제가 있을 수 있습니다.이 문제를 해결하려면 encoding 매개 변수를 사용하여 파일 인코딩을 지정할 수 있습니다.예를 들면 다음과 같습니다.
코드_블록_플레이스홀더_5 이 코드에서는 CSV 파일이 UTF-8 형식으로 인코딩되도록 지정합니다.
CSV를 문자열로 읽기
기본적으로 Pandas는 CSV 파일을 숫자 및 문자열 유형으로 읽습니다.CSV 파일을 문자열로 읽으려면 dtype 매개 변수를 사용하고 모든 열의 데이터 유형을 문자열로 설정할 수 있습니다.예를 들면 다음과 같습니다.
코드_블록_플레이스홀더_6
이 문장에서 계속 쓰세요. 기본적으로 Pandas는 CSV 파일을 숫자 및 문자열 유형으로 읽습니다.CSV 파일을 문자열로 읽으려면 dtype 매개 변수를 사용하고 모든 열의 데이터 유형을 문자열로 설정할 수 있습니다.예를 들면 다음과 같습니다.
다음은 Pandas에서 dtype 매개 변수를 사용하여 CSV 파일을 문자열로 읽는 방법의 예입니다.
코드_블록_플레이스홀더_7
이 코드는 data.csv 라는 CSV 파일을 읽고 모든 열의 데이터 유형을 문자열로 설정합니다.결과로 생성되는 DataFrame 객체 df에는 모든 데이터가 문자열 형식으로 포함됩니다.
여러 CSV 파일 읽기
또한 판다에서는 read_csv () 함수를 사용하여 여러 CSV 파일을 한 번에 읽을 수 있습니다.파일 경로 목록을 함수에 전달하면 모든 파일의 데이터가 포함된 DataFrames 목록이 반환됩니다.
코드_블록_플레이스홀더_8
이 예시에서는 data1.csv, data2.csv, data3.csv라는 세 개의 CSV 파일을 읽고 결과 목록 데이터프레임에는 모든 파일의 데이터가 포함된 DataFrames가 포함됩니다.
피그워커로 CSV 파일 시각화하기
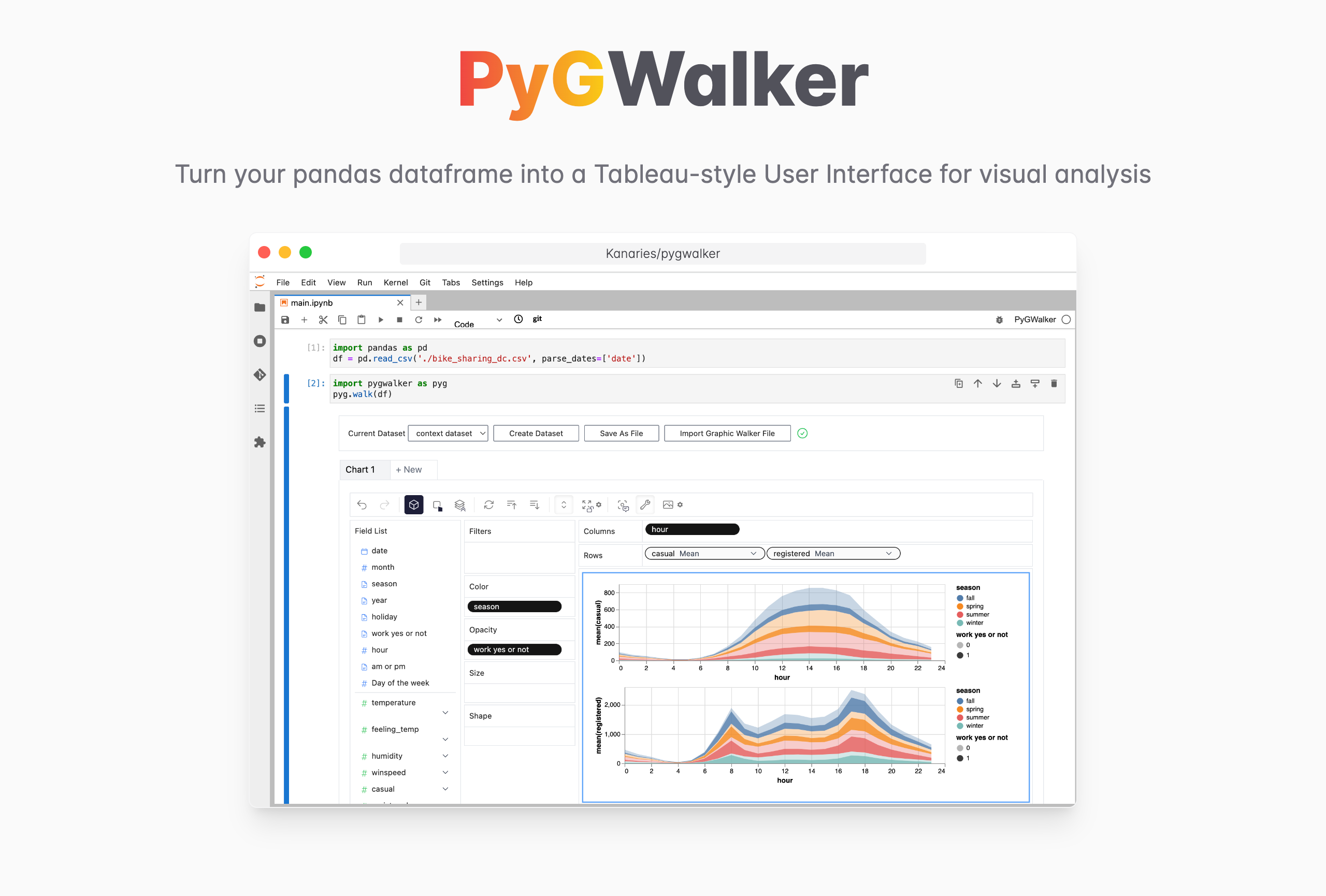
CSV 파일을 읽는 것에서 그치지 않겠습니까?PygWalker (opens in a new tab) 라는 이름의 오픈 소스 도구를 사용하면 복잡한 코드를 배우지 않고도 사용자 친화적인 인터페이스로 멋진 데이터 시각화를 쉽게 만들 수 있습니다.
PygWalker (opens in a new tab) 는 판다 데이터 프레임 (및 폴라 데이터 프레임) 을 시각적 탐색을 위한 Tableau 스타일의 사용자 인터페이스로 전환하여 데이터 분석 및 데이터 시각화 워크플로를 단순화할 수 있습니다.주피터 노트북 (또는 기타 주피터 기반 노트북) 을 Tableau의 다른 유형의 오픈 소스 대안인 그래픽 워커 (opens in a new tab) 와 통합합니다.이를 통해 데이터 과학자는 간단한 드래그 앤 드롭 조작으로 데이터를 분석하고 패턴을 시각화할 수 있습니다.
| 런 인 캐글 (opens in a new tab) | 콜랩에서 실행 (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) |  (opens in a new tab) (opens in a new tab) |
구글 콜랩 (opens in a new tab), 캐글 코드 (opens in a new tab), 바인더 (opens in a new tab) 또는 그래픽 워커 온라인 데모 또는 그래픽 워커 온라인 데모 를 방문하여 PygWalker를 테스트해 보세요! https://graphic-walker.kanaries.net/ (opens in a new tab)
주피터 노트북에서 파이그워커 사용하기
피그워커와 판다를 주피터 노트북으로 가져와서 시작하세요.
코드_블록_플레이스홀더_9
기존 워크플로를 중단하지 않고 PygWalker를 사용할 수 있습니다.예를 들어 Pandas 데이터프레임을 시각적 UI에 로드할 수 있습니다.
코드_블록_플레이스홀더_10
그리고 Pygwalker를 폴라와 함께 사용할 수 있습니다 (Pygwalker>=0.1.4.7A0 이후).
코드_블록_플레이스홀더_11
바인더 (opens in a new tab), 구글 콜랩 (opens in a new tab) 또는 Kaggle Code (opens in a new tab) 를 방문하여 온라인으로도 시도해 볼 수 있습니다.
결론
이 글에서는 read_csv () 함수를 사용하여 Pandas에서 CSV 파일을 읽는 방법을 배웠습니다.또한 CSV 파일을 문자열로 읽고, 열과 행을 건너뛰고, 여러 CSV 파일을 한 번에 읽는 방법도 살펴보았습니다.또한 Pandas 데이터프레임을 데이터 시각화로 변환하는 오픈 소스 도구인 PygWalker (opens in a new tab) 를 사용하여 데이터를 시각화하는 방법을 배웠습니다.이러한 기술을 사용하면 전문가처럼 즉시 데이터 분석을 시작할 수 있습니다!