PyGWalker 소개: Streamlit 시각화를 향상시키세요
PyGWalker (opens in a new tab)는 파이썬 데이터프레임을 직관적이고 tableau-esque한 인터페이스로 변환해주는 탁월한 파이썬 라이브러리로, 데이터 시각화를 간편하게 만들어줍니다.
PyGWalker (opens in a new tab)는 기존에는 주로 데이터 과학자들이 데이터셋을 탐색하는 데 사용되며 주피터에서 사용되었습니다. 그러나 Streamlit과 함께 사용하면 PyGWalker (opens in a new tab)의 다용도성이 발휘됩니다. Streamlit은 프론트엔드나 백엔드 기술에 대한 전문 지식이 필요하지 않고 손쉽게 데이터 애플리케이션을 만들고 공유할 수 있는 매력을 가지고 있습니다.
PyGWalker를 Streamlit과 통합하면 "웹 tableau"를 구축할 수 있습니다. 이를 통해 대시보드를 공유하고 사용자들이 직관적인 드래그 앤 드롭 UI를 통해 자유롭게 탐색할 수 있습니다. 최근의 업데이트로는 API 키를 추가함으로써 "chat-to-charts" 기능을 사용할 수 있도록 되었습니다.
PyGWalker (opens in a new tab)를 특별하게 만드는 것은 그 클라우드 네이티브 디자인입니다. 다양한 클라우드 데이터베이스, OLAP 또는 DW에 연결할 수 있는 능력을 갖추고 있으므로 많은 비용 소모적인 전통적인 BI 도구들을 능가하는 고성능 경험을 제공합니다.
Streamlit을 사용한 클라우드 기반의 PyGWalker (opens in a new tab)를 만들 준비가 되었나요? 시작해봅시다.
의존성 설정:
pip install pygwalker
pip install streamlit이 튜토리얼에서는 지진 데이터셋을 사용할 것이며, CSV 파일로부터 로드할 수 있습니다.
def get_df() -> pd.DataFrame:
df = pd.read_csv("./Significant Earthquake_Dataset_1900_2023.csv")
df["Time"] = pd.to_datetime(df["Time"]).dt.strftime('%Y-%m-%d %H:%M:%S')
return df로드된 데이터셋을 PyGWalker에 공급하세요:
from pygwalker.api.streamlit import get_streamlit_htm
html = get_streamlit_html(df, use_kernel_calc=True, spec="./spec/geo_vis.json", debug=False)이제 Streamlit을 사용하여 PyGWalker의 HTML을 간단히 렌더링하세요:
import streamlit.components.v1 as components
components.html(get_pyg_html(df), width=1300, height=1000, scrolling=True)앱을 실행하여 확인하세요:
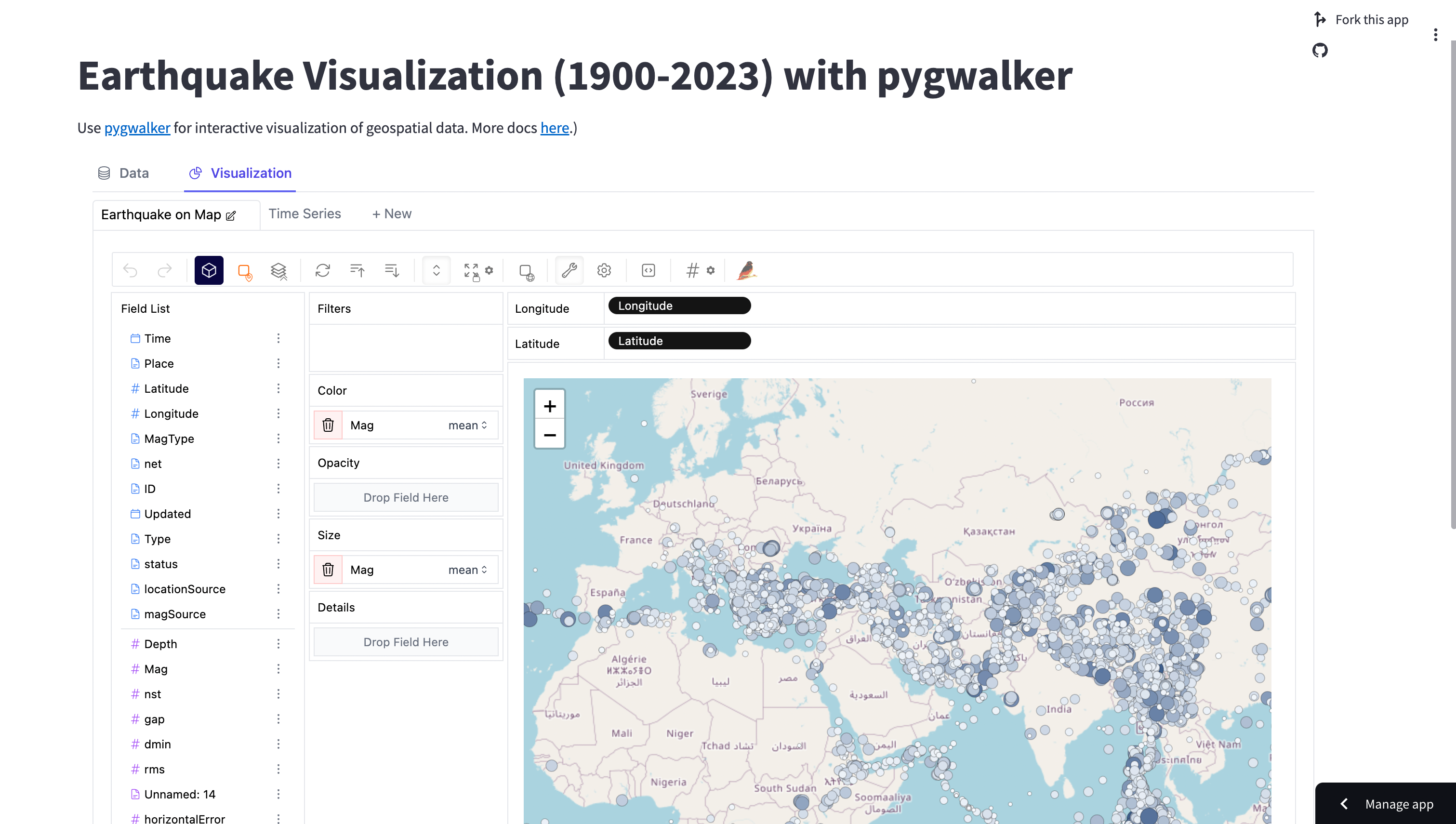
PyGWalker의 새 엔진을 활용하여 쿼리 성능 향상
v0.3부터 PyGWalker는 DuckDB 기반의 계산 엔진을 통합하여 확장성 있는 데이터 쿼리를 빠르게 수행할 수 있도록 하였습니다.
이를 활성화하려면 use_kernel_calc 매개변수를 추가하세요:
pyg.walk(df, use_kernel_calc=True)이는 주피터와 같은 환경에서는 완벽하게 작동하지만, Streamlit은 프론트엔드와 백엔드 간의 데이터 전송 제한을 가지므로 일부 제약이 있습니다. 그러나 Kanaries (opens in a new tab) 개발팀의 노력 덕분에 간단한 해결책이 마련되었습니다:
from pygwalker.api.streamlit import init_streamlit_comm
init_streamlit_comm()마무리
PyGWalker와 Streamlit을 결합하면 최소한의 코드로 동적인 온라인 대화형 데이터 시각화 앱을 만들 수 있습니다. 지금 바로 데이터 탐색을 시작해보세요!