Pandas-Visualisierung: Eine Schritt-für-Schritt Anleitung
- Name
- Rajiv Chandra
Published on
Die Pandas-Bibliothek von Python ist ein mächtiges Werkzeug, das Datenwissenschaftler und Analysten weltweit täglich nutzen. Eine der überzeugendsten Funktionen ist die umfangreiche Datenvisualisierung. Dieser Artikel führt Sie durch den Prozess der Erstellung überzeugender Plots mit Pandas und vermittelt Ihnen die Fähigkeiten zur Umwandlung von Rohdaten in aussagekräftige Diagramme.
Die Pandas-Visualisierung geht nicht nur darum, Ihre Daten hübsch aussehen zu lassen. Es geht darum, die Geschichten zu entdecken, die in den Zahlen verborgen sind. Egal, ob Sie einen neuen Datensatz erkunden oder Ihre neuesten Erkenntnisse teilen möchten, Visualisierungen sind der Schlüssel zur Kommunikation datengetriebener Erkenntnisse.
Lassen Sie uns tiefer in jeden Abschnitt eintauchen, mit detaillierten Erklärungen und Beispielcode-Schnipseln.
Verwendung der Plot-Funktion für die Pandas-Visualisierung
Pandas bietet eine hochgradige, flexible und effiziente Datenstruktur namens DataFrame, die sich hervorragend zur Visualisierung eignet. Mit der Funktion .plot() können Sie verschiedene Arten von Diagrammen wie Linien-, Balken-, Scatter- und mehr erstellen. Diese Funktion ist ein Wrapper für die vielseitige Matplotlib-Bibliothek und vereinfacht die Erstellung komplexer Visualisierungen.
Wenn Sie beispielsweise gerade erst mit Pandas beginnen, werden Sie bald grundlegende Liniendiagramme erstellen, die wertvolle Trends in Ihren Daten aufzeigen können. Liniendiagramme eignen sich hervorragend, um Daten im Laufe der Zeit darzustellen und sind daher perfekt für die Analyse von Zeitreihendaten.
Hier ist ein einfaches Beispiel, wie Sie ein Liniendiagramm mit Pandas erstellen können:
import pandas as pd
import numpy as np
# Erstellen Sie ein DataFrame
df = pd.DataFrame({
'A': np.random.rand(10),
'B': np.random.rand(10)
})
df.plot(kind='line')In diesem Code importieren wir zunächst die benötigten Bibliotheken. Anschließend erstellen wir ein DataFrame mit zwei Spalten, die jeweils mit zufälligen Zahlen gefüllt sind. Schließlich verwenden wir die Funktion .plot(), um ein Liniendiagramm zu erstellen.
Aber was ist, wenn Sie eine visuelle Benutzeroberfläche zum Plotten von Pandas Dataframes ohne Code verwenden möchten? Nun, zum Glück gibt es ein Pandas DataFrame, das Ihnen dabei helfen kann:
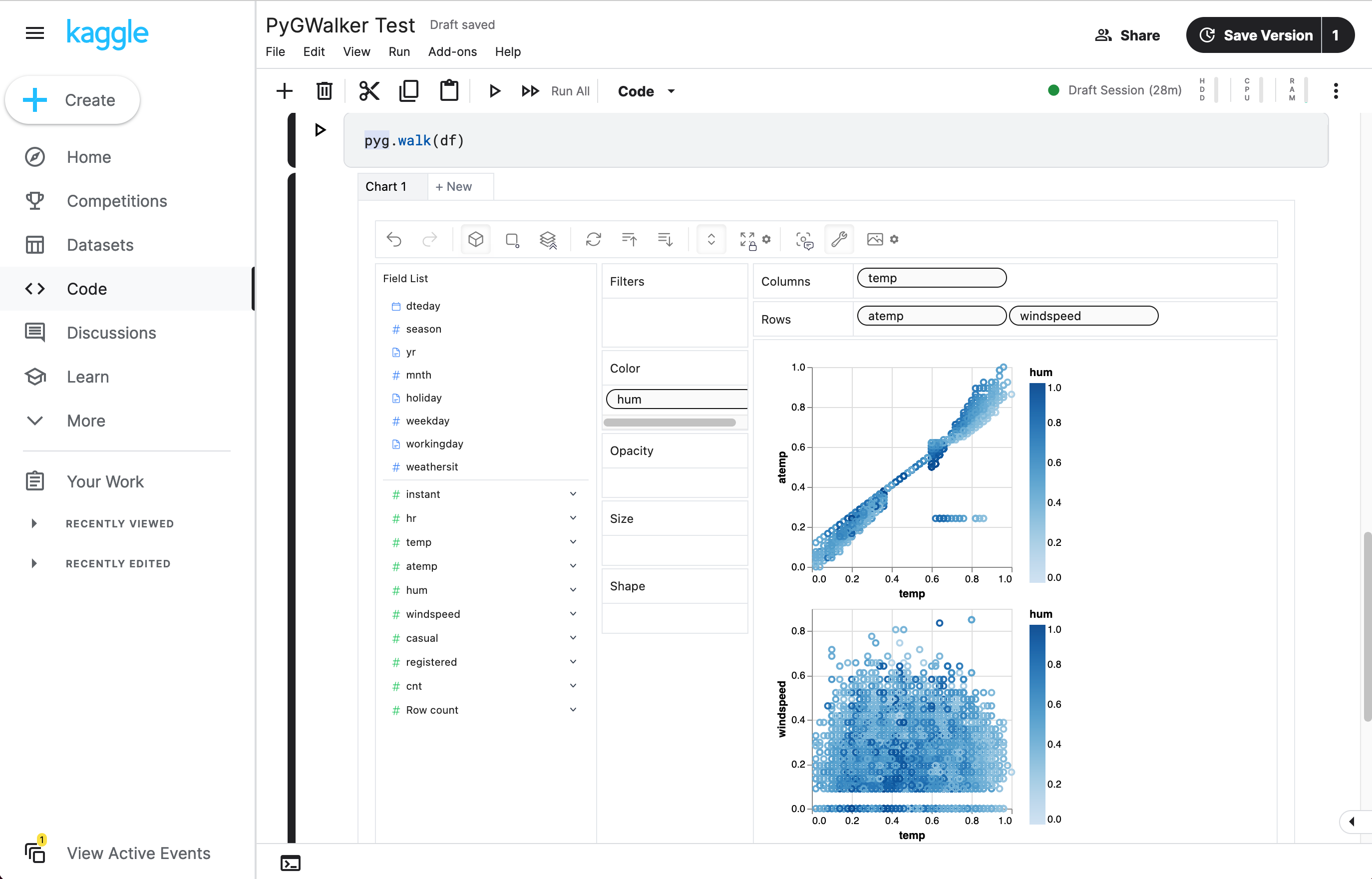
Verwendung von PyGWalker zur Pandas-Visualisierung
PyGWalker ist eine Python-Bibliothek, die für explorative Datenanalyse und einfache Datenvisualisierung entwickelt wurde. Stellen Sie sich vor, Sie führen ein Open-Source-Tableau in Ihrem Jupyter-Notebook aus. Sie können Visualisierungen einfach per Drag & Drop von Variablen erstellen, anstatt komplexe Codetutorials durchzugehen:
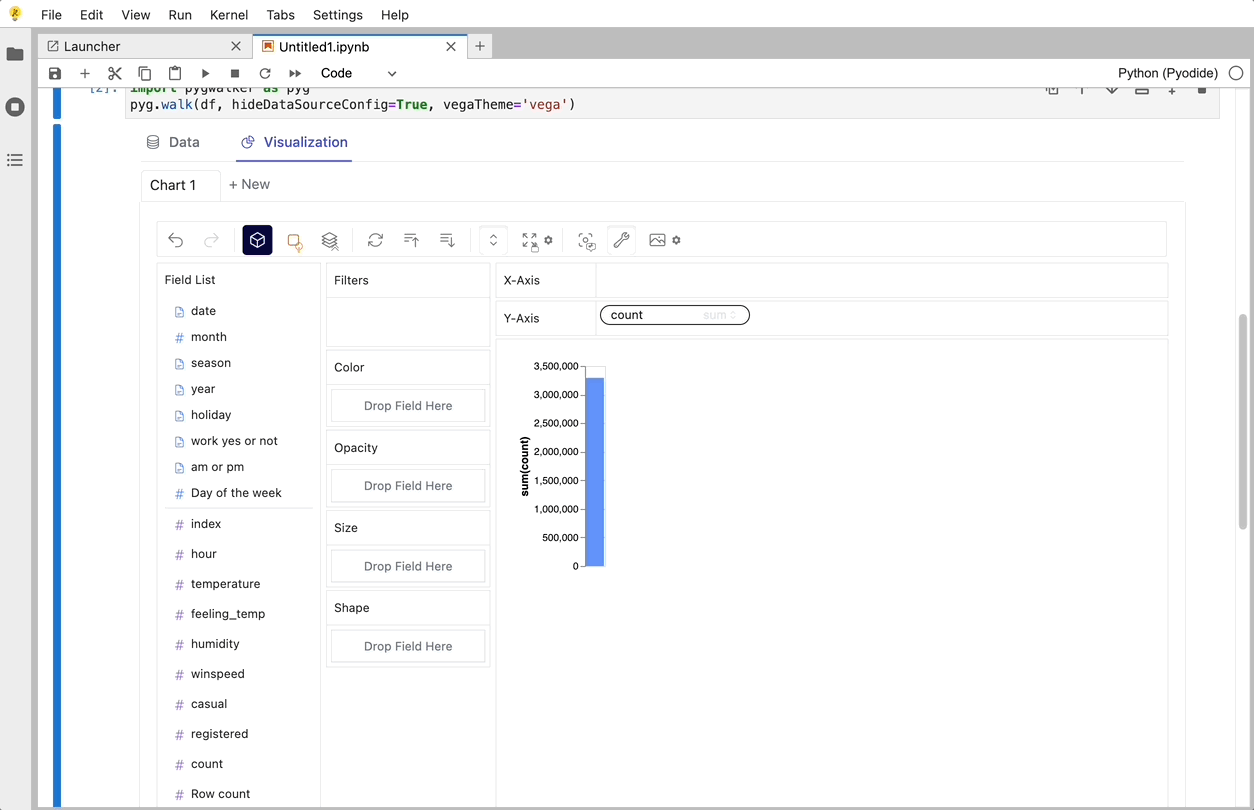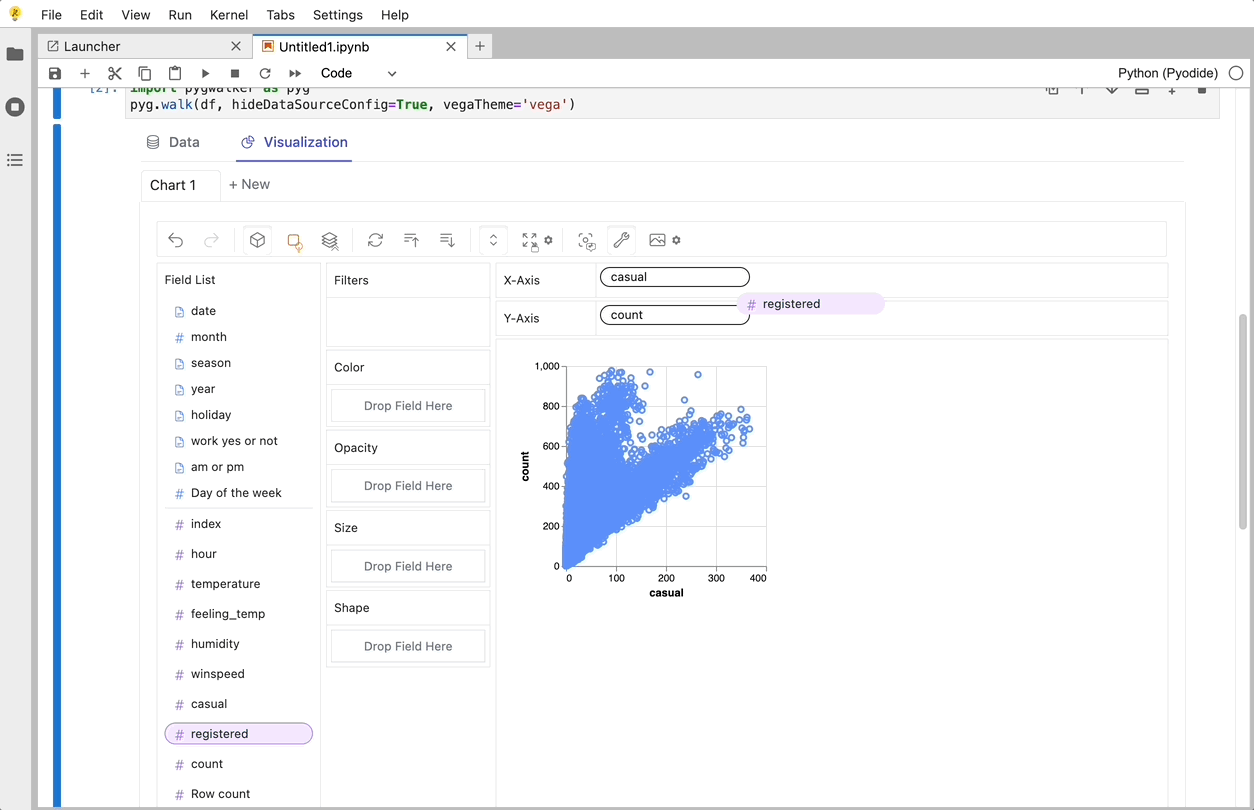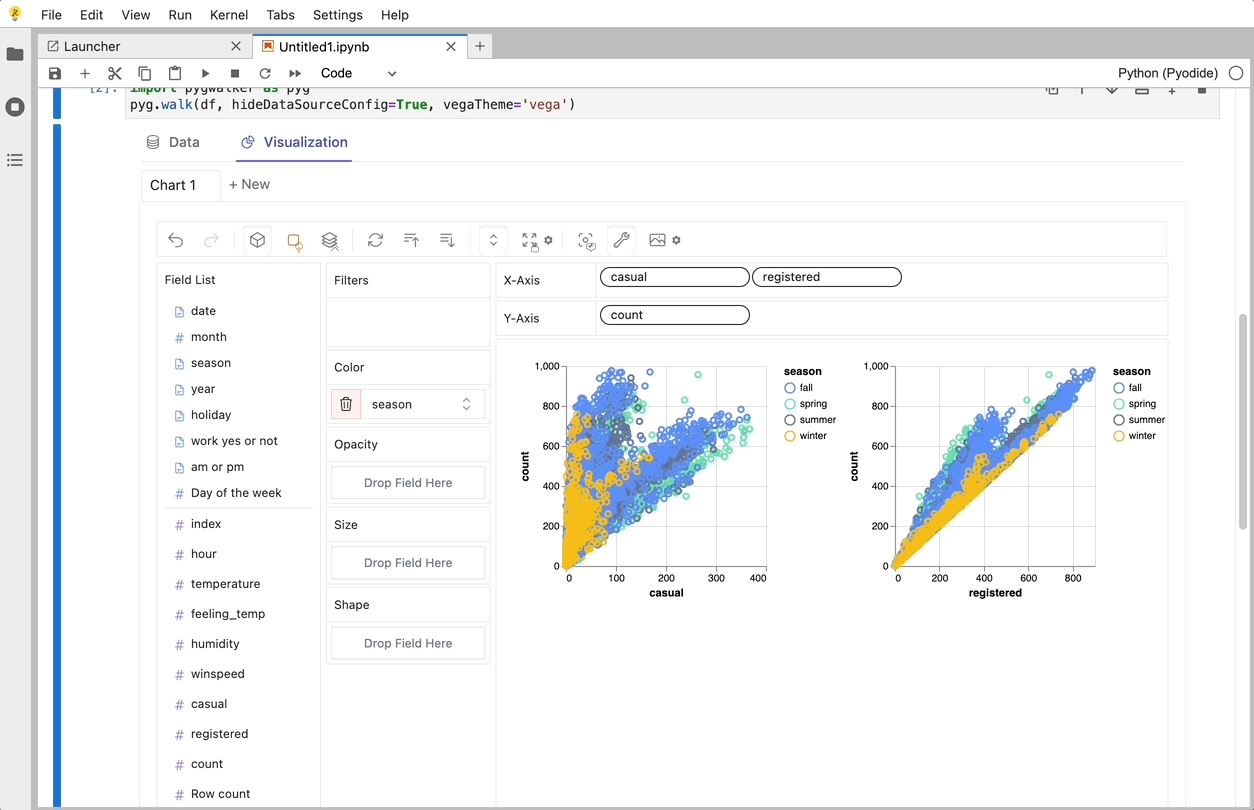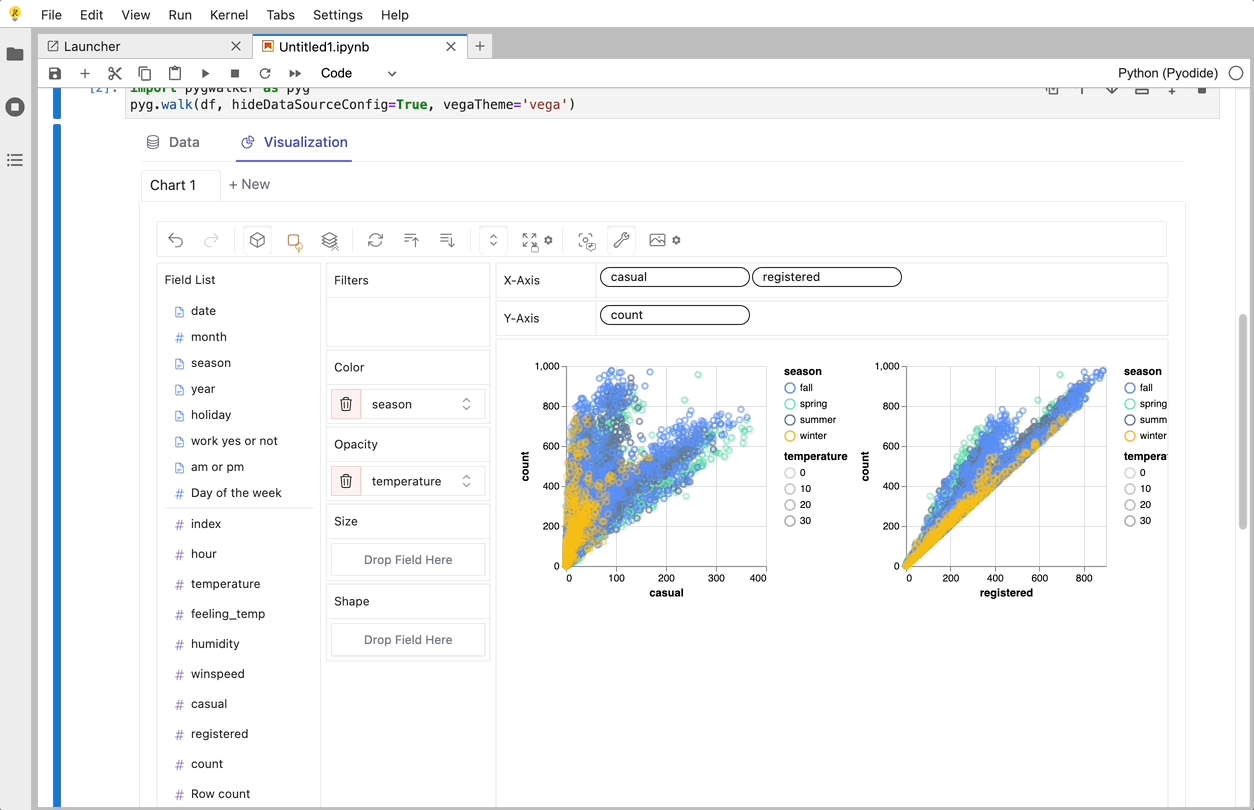
So können Sie schnell loslegen:
Importieren Sie pygwalker und pandas in Ihr Jupyter-Notebook, um loszulegen.
import pandas as pd
import pygwalker as pygSie können pygwalker verwenden, ohne Ihren bestehenden Workflow zu unterbrechen. Sie können beispielsweise Graphic Walker mit dem geladenen DataFrame wie folgt aufrufen:
df = pd.read_csv('./bike_sharing_dc.csv', parse_dates=['date'])
gwalker = pyg.walk(df)Und Sie können pygwalker mit polars verwenden (nur ab pygwalker>=0.1.4.7a0):
import polars as pl
df = pl.read_csv('./bike_sharing_dc.csv',try_parse_dates = True)
gwalker = pyg.walk(df)Jetzt haben Sie Ihr Pandas-DataFrame für die Visualisierung geladen.
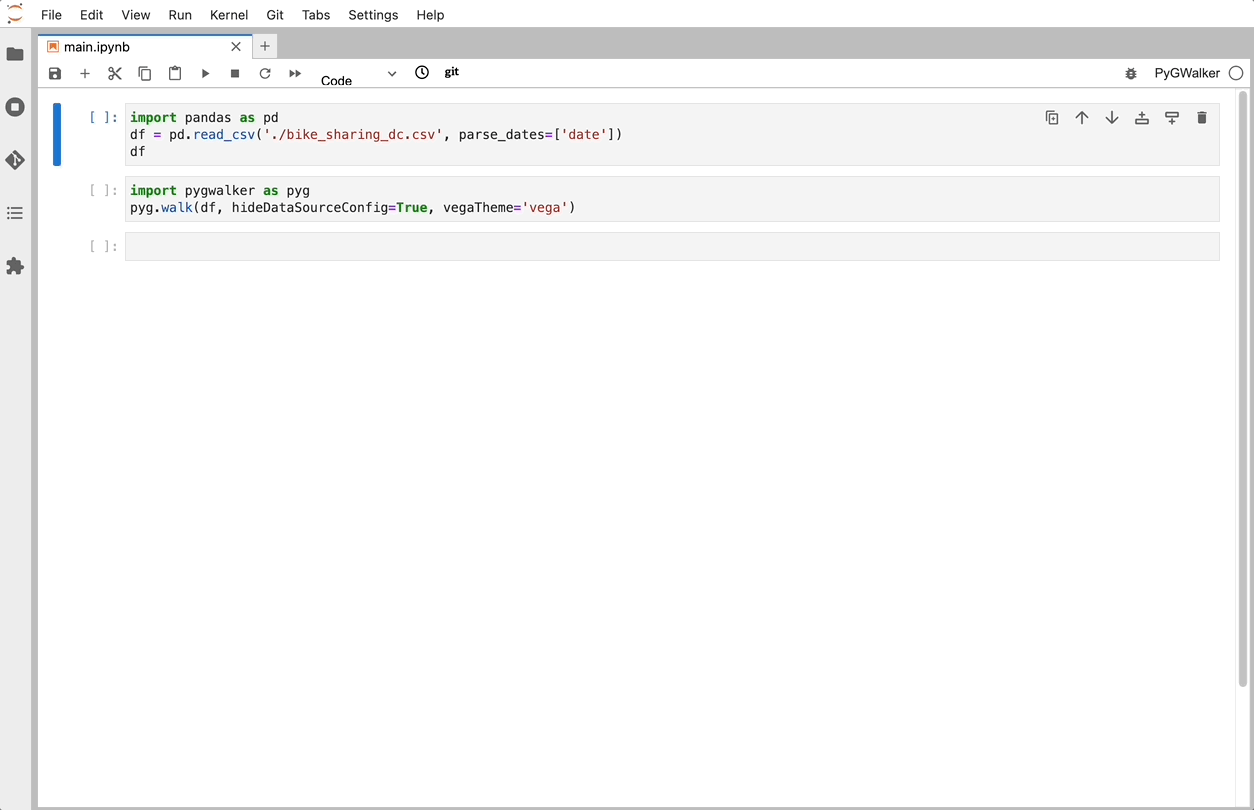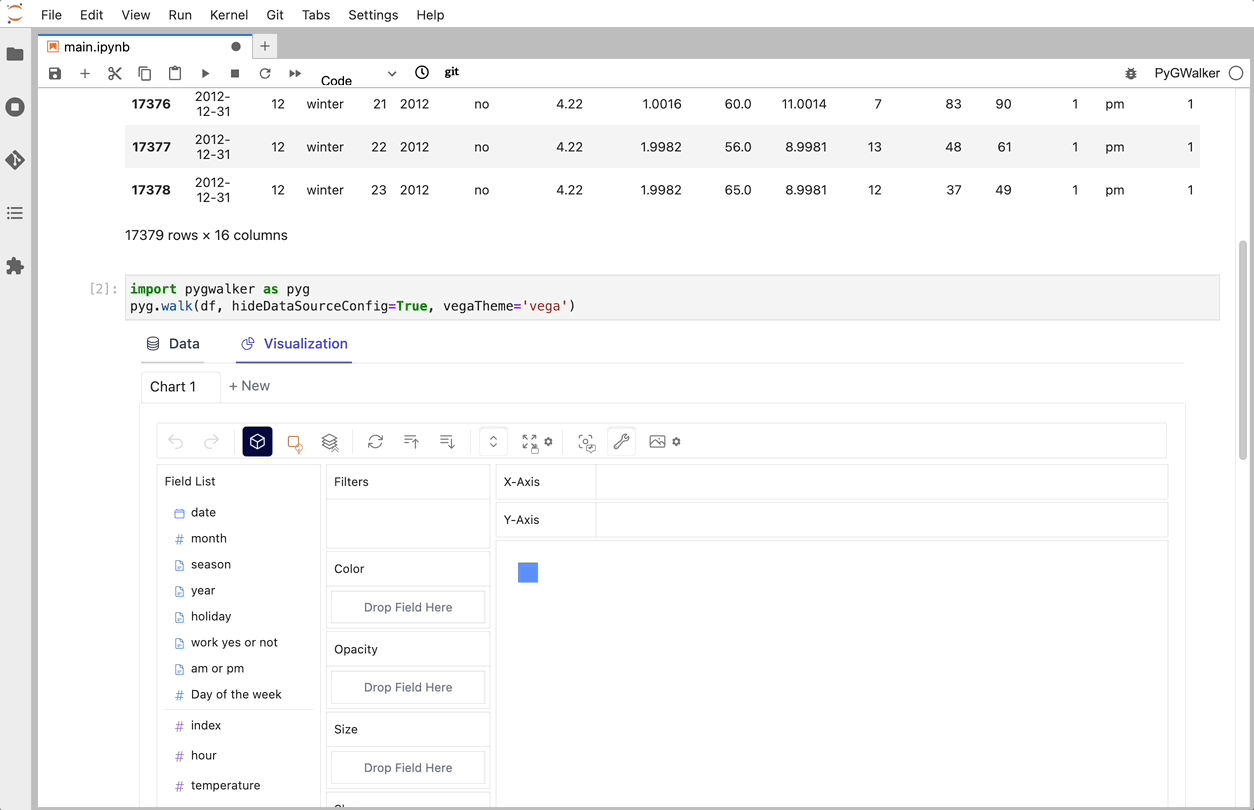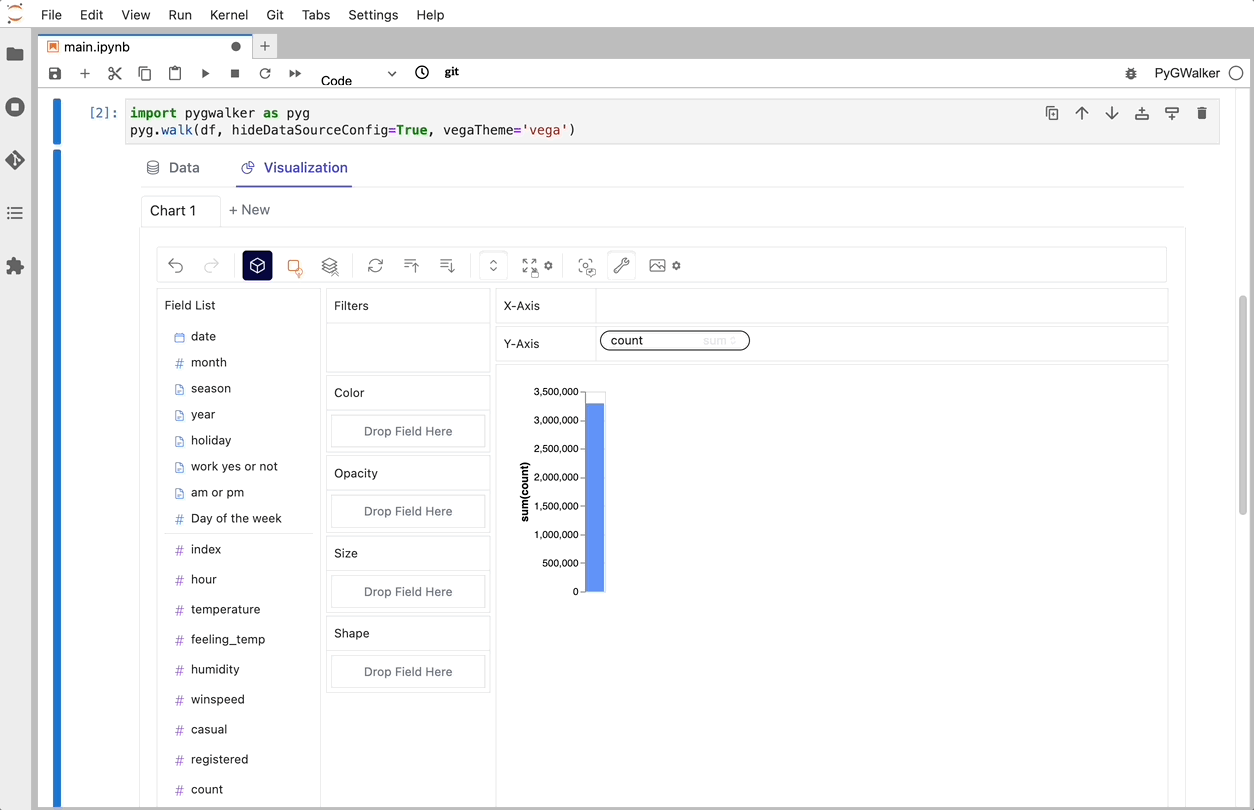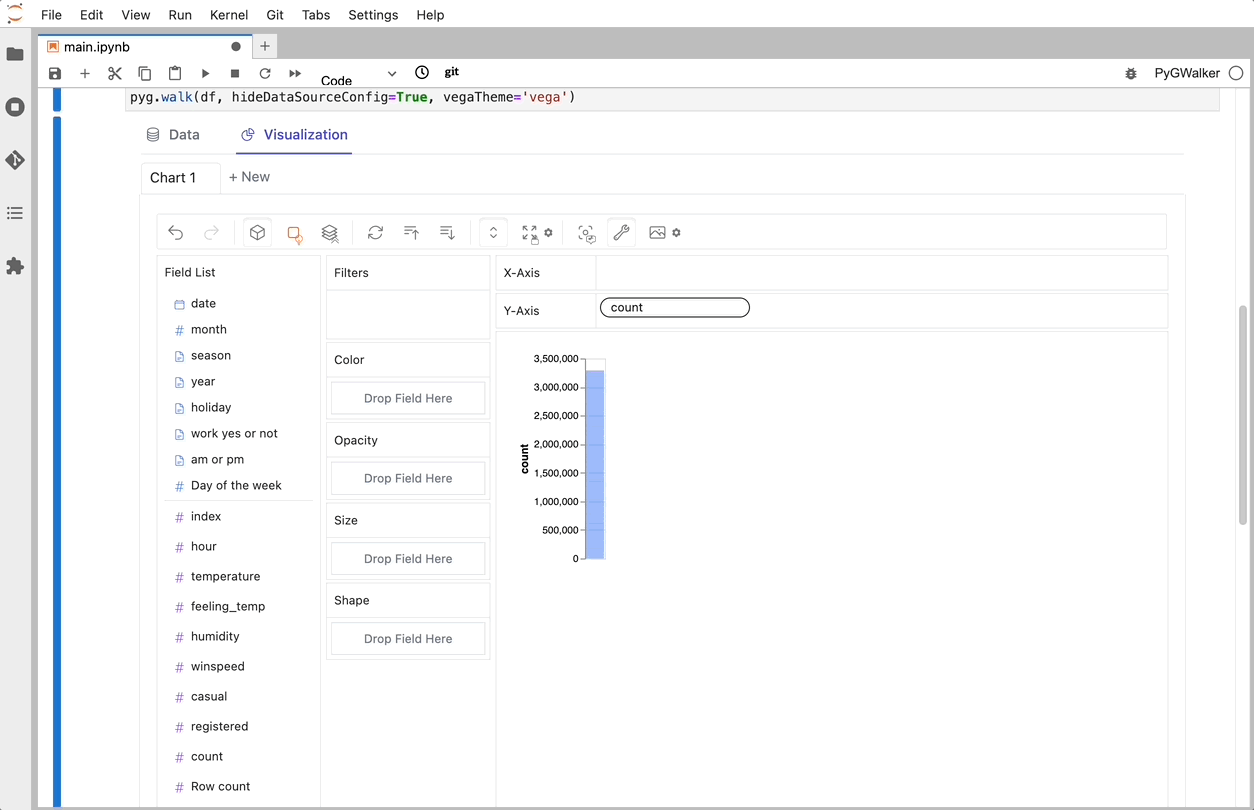
Das war's. Jetzt haben Sie eine benutzerfreundliche Oberfläche ähnlich wie Tableau, um Daten zu analysieren und zu visualisieren, indem Sie Variablen per Drag & Drop ziehen und ablegen.
PyGWalker wird von einer aktiven Entwickler- und Datenwissenschaftler-Community unterstützt. Besuchen Sie PyGWalker GitHub (opens in a new tab) und geben Sie ihm ein ⭐️!
Sie können PyGWalker jetzt mit Google Colab oder Kaggle Notebook ausprobieren:
| Mit Kaggle ausführen (opens in a new tab) | Mit Colab ausführen (opens in a new tab) |
|---|---|
 (opens in a new tab) (opens in a new tab) | 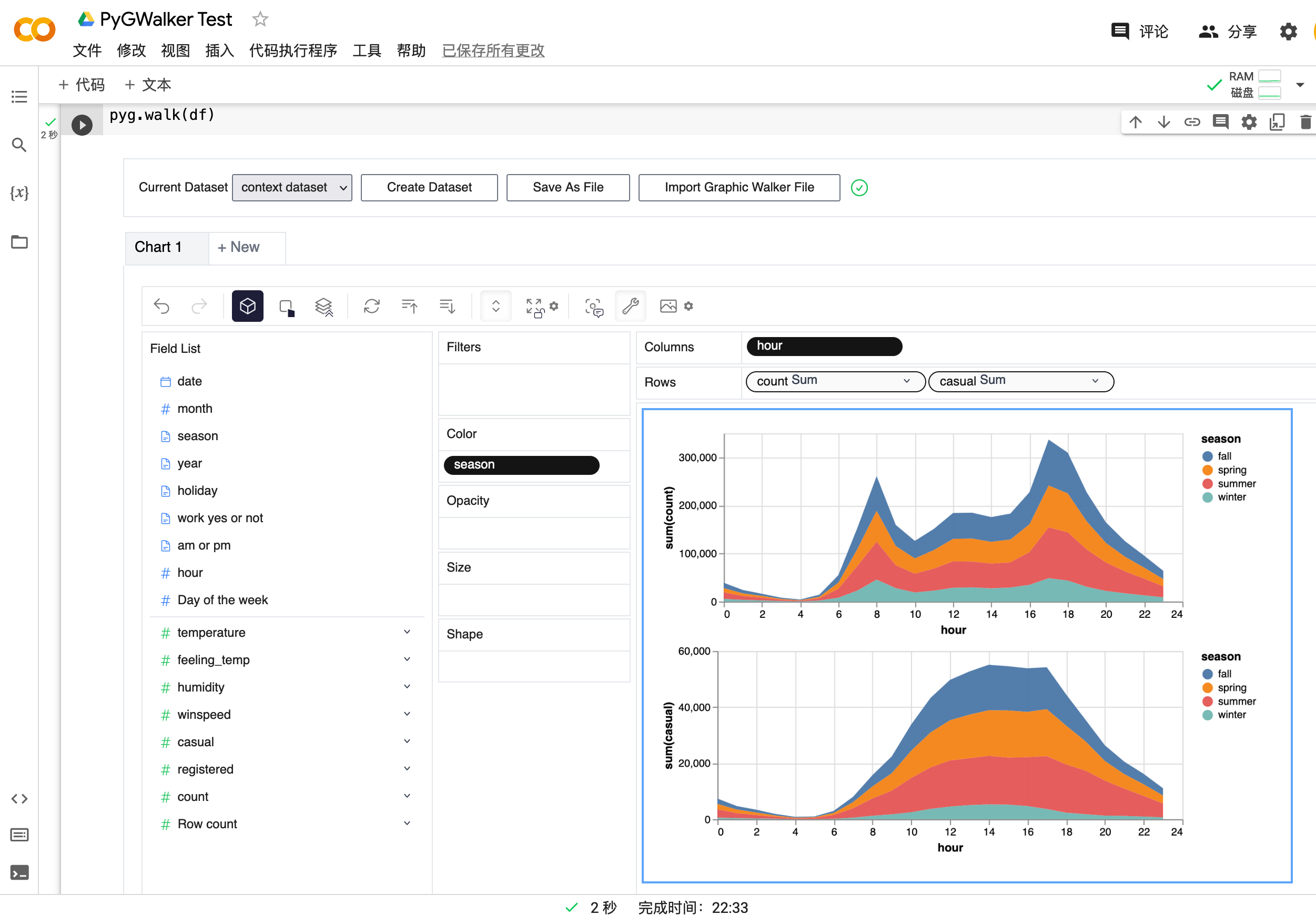 (opens in a new tab) (opens in a new tab) |
Eintauchen in verschiedene Diagrammtypen
Pandas bietet eine Vielzahl von Diagrammtypen, die jeweils für verschiedene Arten von Daten und Fragen geeignet sind. Histogramme eignen sich beispielsweise hervorragend, um einen Überblick über die Verteilung Ihrer Daten zu erhalten, während Streudiagramme Ihnen dabei helfen können, Korrelationen zwischen verschiedenen Datenpunkten zu entdecken.
Jeder Diagrammtyp in Pandas wird mit einer Reihe von Parametern geliefert, die Sie anpassen können, um Ihre Visualisierung anzupassen. Das Verständnis dieser Parameter und wann sie verwendet werden sollten, kann Ihre Fähigkeit zur Erstellung aussagekräftiger Visualisierungen erheblich verbessern.
Hier ist, wie Sie ein Histogramm und ein Streudiagramm erstellen können:
# Histogramm
df['A'].plot(kind='hist')
# Streudiagramm
df.plot(kind='scatter', x='A', y='B')Im ersten Plot erstellen wir ein Histogramm der Spalte 'A'. Im zweiten Plot erstellen wir ein Streudiagramm mit 'A' auf der x-Achse und 'B' auf der y-Achse.
Umgang mit kategorialen Daten mit Pandas
Kategoriale Daten sind ein häufiger Datentyp, der in vielen Datensätzen vorkommt. Pandas bietet mehrere leistungsstarke Tools zur Visualisierung dieser Art von Daten. Balkendiagramme können Ihnen zum Beispiel helfen, verschiedene Kategorien zu vergleichen, während Tortendiagramme sich hervorragend zur Visualisierung von Verhältnissen zwischen Kategorien eignen.
Darüber hinaus können Sie in Pandas Ihre Daten basierend auf Kategorien gruppieren, was äußerst nützlich sein kann, wenn Sie Ihre Daten aggregieren und Erkenntnisse auf Kategorieebene gewinnen möchten.
Hier ist ein Beispiel, wie Sie ein Balkendiagramm und ein Tortendiagramm erstellen können:
# Erstellen Sie ein DataFrame mit kategorialen Daten
Bitte geben Sie die deutsche Übersetzung für diese Markdown-Datei an. Wenn es ein Frontmatter gibt, stellen Sie sicher, dass das Sprachparameter auch auf "de" übersetzt wird. Hier ist die Datei: df = pd.DataFrame({
'Fruit': ['Apfel', 'Banane', 'Kirsche', 'Apfel', 'Kirsche', 'Banane', 'Apfel', 'Kirsche', 'Banane', 'Apfel'],
'Anzahl': np.random.randint(1, 10, 10)
})
# Balkendiagramm
df.groupby('Fruit')['Anzahl'].sum().plot(kind='bar')
# Tortendiagramm
df.groupby('Fruit')['Anzahl'].sum().plot(kind='pie')In diesem Code erstellen wir zunächst ein DataFrame mit kategorialen Daten. Wir gruppieren dann die Daten nach der Spalte "Fruit" und summieren die Anzahl für jede Frucht. Schließlich erstellen wir ein Balkendiagramm und ein Tortendiagramm der summierten Anzahlen.
Anpassung Ihrer Plots
Eine der leistungsstärksten Funktionen der Pandas-Datenvisualisierung ist die Möglichkeit, Ihre Plots anzupassen. Dies beinhaltet das Ändern von Farbe und Stil Ihrer Plots, das Hinzufügen von Beschriftungen und Titeln und vieles mehr.
Hier ist ein Beispiel, wie man einen Linienplot anpassen kann:
# DataFrame erstellen
df = pd.DataFrame({
'A': np.random.rand(10),
'B': np.random.rand(10)
})
# Linienplot mit Anpassungen erstellen
df.plot(kind='line',
color=['rot', 'blau'],
style=['-', '--'],
title='Mein Linienplot',
xlabel='Index',
ylabel='Wert')In diesem Code erstellen wir zuerst ein DataFrame mit zwei Spalten, die jeweils mit Zufallszahlen gefüllt sind. Dann erstellen wir einen Linienplot und passen ihn an, indem wir die Farbe und den Stil der Linien festlegen und einen Titel sowie Beschriftungen für die x- und y-Achsen hinzufügen.
Umgang mit komplexeren Datenstrukturen
Pandas ist nicht darauf beschränkt, einfache Datenstrukturen zu verarbeiten. Es kann auch komplexere Datenstrukturen wie Multi-Index DataFrames und Zeitreihendaten verarbeiten.
Hier ist ein Beispiel, wie man einen Linienplot aus einem Multi-Index DataFrame erstellt:
# Multi-Index DataFrame erstellen
index = pd.MultiIndex.from_tuples([(i,j) for i in range(5) for j in range(5)])
df = pd.DataFrame({
'A': np.random.rand(25),
'B': np.random.rand(25)
}, index=index)
# Linienplot erstellen
df.plot(kind='line')In diesem Code erstellen wir zuerst einen Multi-Index DataFrame mit zwei Spalten, die jeweils mit Zufallszahlen gefüllt sind. Dann erstellen wir einen Linienplot aus diesem DataFrame.
Fortgeschrittene Visualisierung mit Seaborn
Obwohl Pandas eine solide Grundlage für die Datenvisualisierung bietet, benötigen Sie manchmal fortgeschrittenere Werkzeuge. Seaborn ist eine Python-Datenvisualisierungsbibliothek auf Basis von Matplotlib, die eine benutzerfreundliche Schnittstelle für die Erstellung schöner und informativer Visualisierungen bietet.
Hier ist ein Beispiel, wie man einen Seaborn-Plot aus einem Pandas DataFrame erstellt:
import seaborn as sns
# DataFrame laden
df = pd.read_csv('bikesharing_dc.csv', parse_dates=['date'])
# Seaborn-Plot erstellen
sns.lineplot(data=df, x='date', y='count')In diesem Code importieren wir zuerst die Seaborn-Bibliothek. Dann laden wir ein DataFrame und erstellen einen Linienplot mit der 'date'-Spalte auf der x-Achse und der 'count'-Spalte auf der y-Achse.
Interaktive Visualisierung mit Plotly
Für interaktive Visualisierungen ist Plotly eine gute Wahl. Plotly ist eine Python-Grafikbibliothek, die interaktive und qualitativ hochwertige Grafiken ermöglicht.
Hier ist ein Beispiel, wie man einen Plotly-Plot aus einem Pandas DataFrame erstellt:
import plotly.express as px
# DataFrame laden
df = pd.read_csv('bikesharing_dc.csv', parse_dates=['date'])
# Plotly-Plot erstellen
fig = px.line(df, x='date', y='count')
fig.show()In diesem Code importieren wir zuerst das Plotly Express-Modul. Dann laden wir ein DataFrame und erstellen einen Linienplot mit der 'date'-Spalte auf der x-Achse und der 'count'-Spalte auf der y-Achse. Der Befehl fig.show() zeigt den interaktiven Plot an.
Fazit
Pandas ist ein leistungsstolles Werkzeug für die Datenanalyse und -visualisierung in Python. Mit seinen robusten Plotting-Fähigkeiten und der Kompatibilität mit anderen Visualisierungsbibliotheken wie Matplotlib, Seaborn, Plotly und PyGWalker können Sie eine Vielzahl von Visualisierungen erstellen, um Erkenntnisse aus Ihren Daten zu gewinnen. Egal, ob Sie ein Anfänger sind oder erfahrener Datenwissenschaftler, das Beherrschen der Pandas-Visualisierung ist eine wertvolle Fähigkeit, die Ihren Datenanalyse-Workflow verbessern wird.
FAQs
-
Was ist Pandas in Python?
- Pandas ist eine Softwarebibliothek, die für die Programmiersprache Python geschrieben wurde, um Datenmanipulation und -analyse durchzuführen. Es bietet Datenstrukturen und Funktionen, die für die Manipulation strukturierter Daten benötigt werden.
-
Wie wird Pandas für die Datenvisualisierung verwendet?
- Pandas ermöglicht die Datenvisualisierung, indem es die Verwendung seiner plot()-Funktion und verschiedener Plotting-Methoden ermöglicht, um Daten direkt aus DataFrame- und Series-Objekten zu plotten.
-
Welche sind einige der beliebtesten Pandas Visualisierungsbibliotheken?
- Einige der beliebtesten Bibliotheken für Datenvisualisierung in Pandas sind Matplotlib, Seaborn, Plotly und PyGWalker. Diese Bibliotheken bieten eine Vielzahl von Tools und Funktionen zur Erstellung statischer, animierter und interaktiver Plots in Python.