Can ChatGPT Replace Data Analyst? Effortlessly Generate Complex SQL Queries with ChatGPT

Introduction
SQL (Structured Query Language) is a widely used programming language for managing and manipulating data in relational databases. Businesses and organizations need to store and retrieve and analyze data. However, writing SQL queries can be a time-consuming and error-prone task for humans, especially for complex queries or large databases.
In this article, we will explore the capabilities of ChatGPT, a large language model developed by OpenAI, in generating efficient SQL queries. We will demonstrate how ChatGPT can quickly generate complex queries, filter data with high precision and recall, and optimize existing queries.
Generate a sample database
To make things clear, we are a having the following sample database as the example:
Table 1: books
This table will contain information about all the books in the bookstore, including their titles, authors, publishers, and ISBNs.
CREATE TABLE books (
book_id INT PRIMARY KEY,
title VARCHAR(255),
author VARCHAR(255),
publisher VARCHAR(255),
isbn VARCHAR(13)
);Table 2: customers This table will store information about the customers who have registered with the bookstore, including their names, email addresses, and phone numbers.
CREATE TABLE customers (
customer_id INT PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255),
phone VARCHAR(20)
);Table 3: orders
This table will store information about all the orders placed by customers, including the customer who placed the order, the book(s) ordered, the order date, and the order status.
CREATE TABLE orders (
order_id INT PRIMARY KEY,
customer_id INT,
book_id INT,
order_date DATE,
status VARCHAR(20),
FOREIGN KEY (customer_id) REFERENCES customers(customer_id),
FOREIGN KEY (book_id) REFERENCES books(book_id)
);Table 4: inventory
This table will track the current inventory levels of each book in the store.
CREATE TABLE inventory (
book_id INT PRIMARY KEY,
quantity INT,
FOREIGN KEY (book_id) REFERENCES books(book_id)
);These are just the basic tables that you would need to get started with a bookstore database. Depending on your specific needs, you may want to add additional tables or columns to these tables.
ChatGPT Prompt for Data Aggregation
One of the most common tasks in working with databases is data aggregation. This refers to summarizing data based on certain conditions. For example, calculating the total sales for a specific product category or the average salary of employees in a certain department. Aggregation queries can be complex to write and may take a significant amount of time for humans.
ChatGPT, however, can generate these queries quickly and accurately. It can understand the structure of the data and the desired output, and generate an efficient query that can retrieve the required information with minimal effort. This reduces the risk of errors and saves time for the user.
Here is an example of a data aggregation query generated by ChatGPT with the following promot:
"Find the top 5 bestselling books in the last quarter, along with their authors and total sales revenue."
To perform this aggregation, you'll need to join the books, orders, and inventory tables, group the results by book and author, filter by the last quarter's orders, and calculate the total sales revenue for each book. Finally, you'll need to sort the results by revenue and limit the output to the top 5 books.
ChatGPT generates the following SQL code to accomplish this:
SELECT books.title, books.author, SUM(inventory.quantity * orders.price) AS revenue
FROM books
JOIN inventory ON books.book_id = inventory.book_id
JOIN orders ON inventory.book_id = orders.book_id
WHERE orders.order_date >= DATEADD(QUARTER, -1, GETDATE())
GROUP BY books.title, books.author
ORDER BY revenue DESC
LIMIT 5;Data Filtering
Another important task in working with databases is data filtering. This refers to extracting specific data from a database based on certain criteria. For example, extracting all the transactions made by customers in a certain location or all the employees that have been with the company for more than five years. Filtering queries can also be complex to write and may take a significant amount of time for humans.
ChatGPT can generate these queries with high precision and recall. It can understand the structure of the data and the desired output, and generate a query that can retrieve the most relevant data. This results in more accurate data for analysis and decision-making. Here is an example of a data filtering query generated by using this ChatGPT prompt:
"Find all the books published by 'Penguin Random House' and currently in stock, sorted by author name in ascending order."
To perform this filtering, you'll need to join the books and inventory tables, filter by books published by 'Penguin Random House', and select only those books that are currently in stock. Finally, you'll need to sort the results by author name in ascending order.
ChatGPT generates the following SQL code to accomplish this requirement:
SELECT books.title, books.author, books.publisher, inventory.quantity
FROM books
JOIN inventory ON books.book_id = inventory.book_id
WHERE books.publisher = 'Penguin Random House' AND inventory.quantity > 0
ORDER BY books.author ASC;Query Optimization
In addition to generating new SQL queries, ChatGPT can also assist in optimizing existing queries. By analyzing the structure and performance of a query, ChatGPT can suggest improvements that can make the query run faster and more efficiently. For example, ChatGPT can suggest using indexes or rewriting the query to take advantage of the database's capabilities.
Optimizing queries can be a difficult task for humans, especially for large and complex databases. ChatGPT can simplify this task and help improve the performance of the database. Here is an example of a query optimization generated by using this ChatGPT prompt:
"Find the top 10 customers who have spent the most on books in the last year, along with their total spending and average spending per order."
To optimize this query, you'll need to minimize the number of operations that the database needs to perform in order to produce the results. Here are a few optimization techniques you might consider:
-
Use indexes: Add indexes to the relevant columns in the customers and orders tables to speed up the joins and filtering operations.
-
Aggregate before joining: Instead of joining the customers and orders tables and then aggregating the results, you can first aggregate the orders table by customer and then join the resulting table with the customers table.
-
Use subqueries: Instead of joining the customers and orders tables directly, you can use subqueries to filter the orders table by date range and to calculate the total spending and average spending per order for each customer.
Here's an example SQL query that implements these optimizations generated by ChatGPT:
SELECT customers.name,
total_spending,
total_spending / order_count AS avg_spending_per_order
FROM (
SELECT customer_id,
SUM(price * quantity) AS total_spending,
COUNT(*) AS order_count
FROM orders
WHERE order_date >= DATEADD(YEAR, -1, GETDATE())
GROUP BY customer_id
) AS order_totals
JOIN customers ON order_totals.customer_id = customers.customer_id
ORDER BY total_spending DESC
LIMIT 10;Another Automated Data Analysis Option: RATH
In addition to ChatGPT's capabilities in generating efficient SQL queries, there is also RATH (opens in a new tab), an open-source alternative to data analysis and visualization tools such as Tableau. RATH takes data analysis to the next level by automating the Exploratory Data Analysis (EDA) workflow with an Augmented Analytic engine.
RATH supports a wide range of data sources (opens in a new tab). Here are some of the major database solutions that you can connect to RATH: MySQL, ClickHouse, Amazon Athena, Amazon Redshift, Apache Spark SQL, Apache Doris, Apache Hive, Apache Impala, Apache Kylin, Oracle, and PostgreSQL.
RATH (opens in a new tab) is Open Source. Visit RATH GitHub and experience the next-generation Auto-EDA (opens in a new tab) tool. You can also check out the RATH Online Demo as your Data Analysis Playground!

Highlighted RATH features include:
| Feature | Description | Preview |
|---|---|---|
| AutoEda (opens in a new tab) | Augmented analytic engine for discovering patterns, insights, and causals. A fully-automated way to explore your data set and visualize your data with one click. | 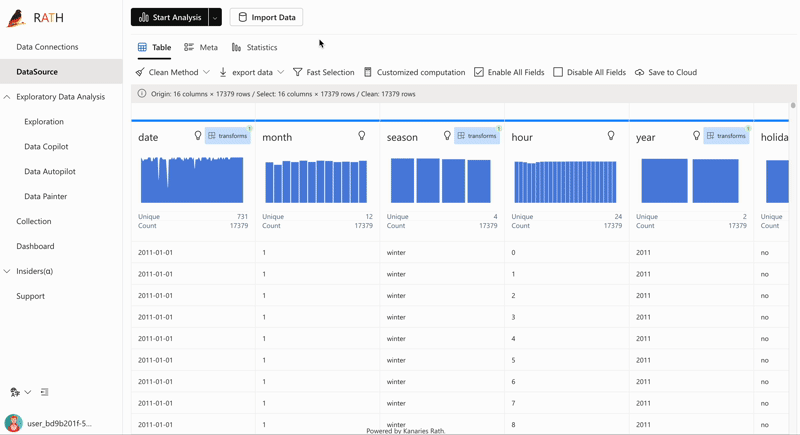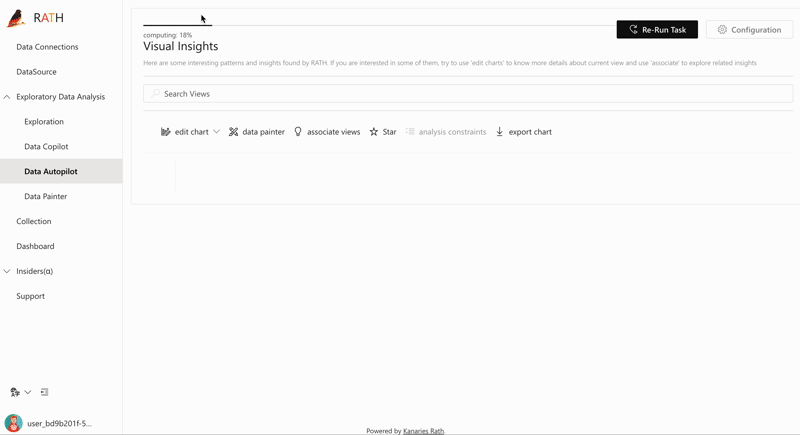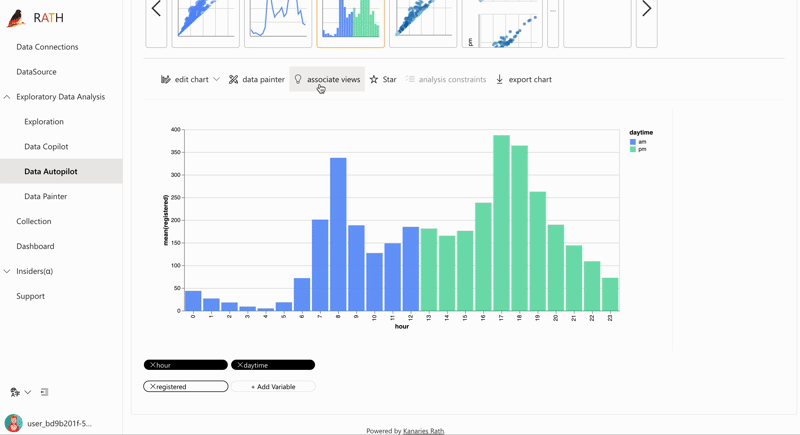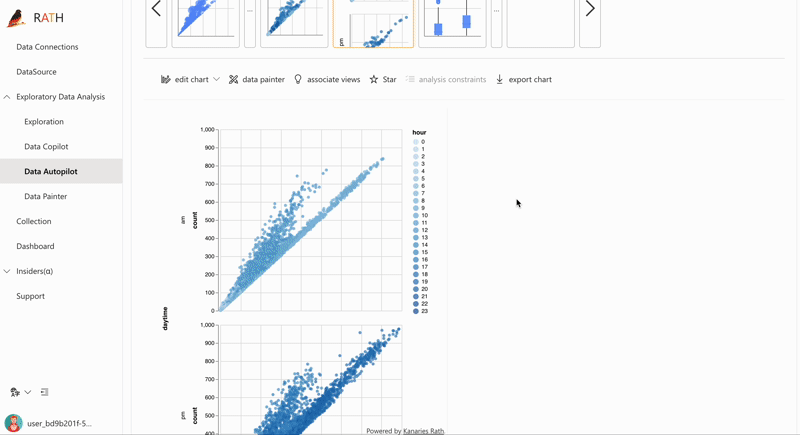 |
| Data Visualization (opens in a new tab) | Create Multi-dimensional data visualization based on the effectiveness score. | 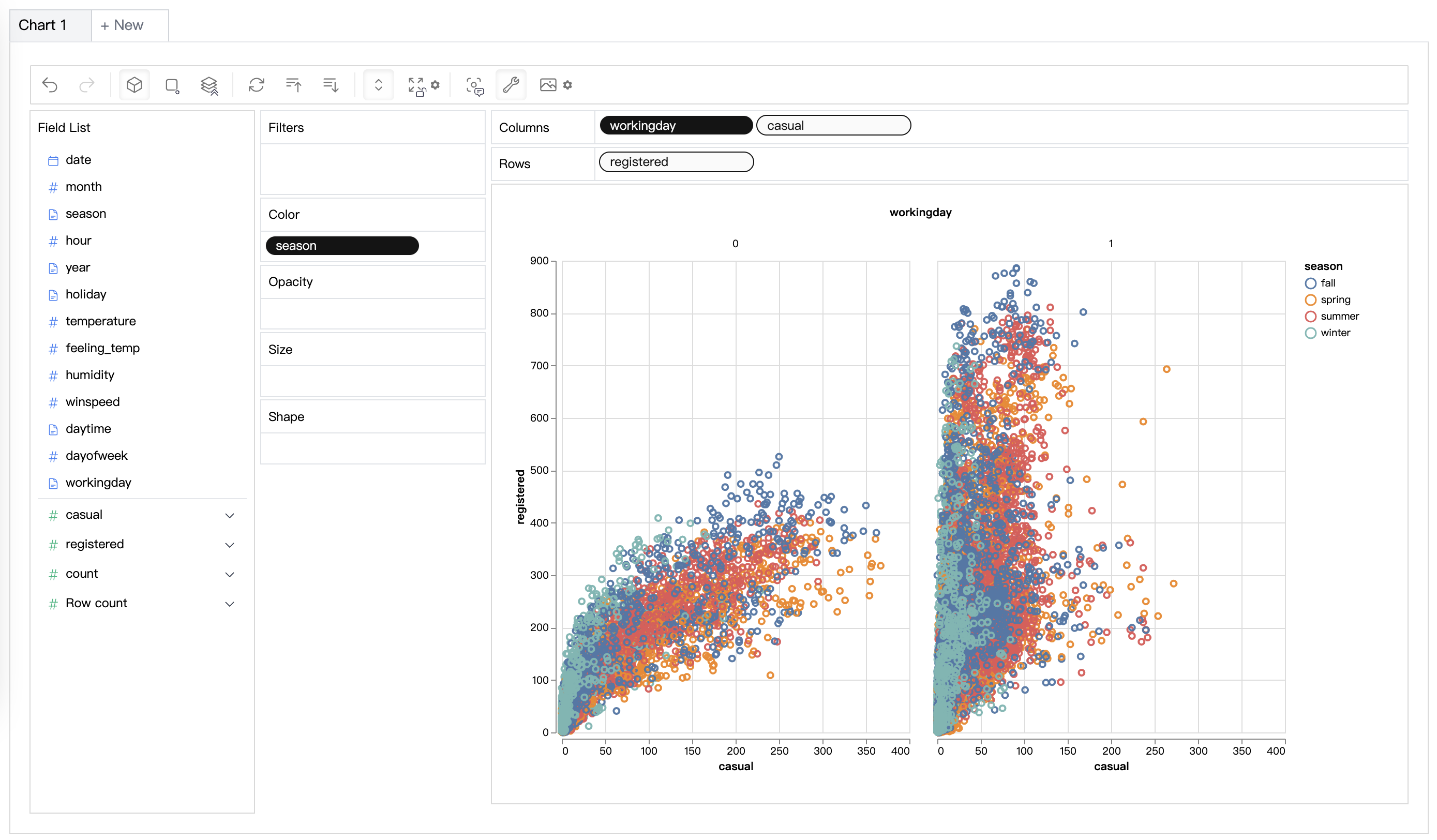 |
| Data Wrangler (opens in a new tab) | Automated data wrangler for generating a summary of the data and data transformation. | 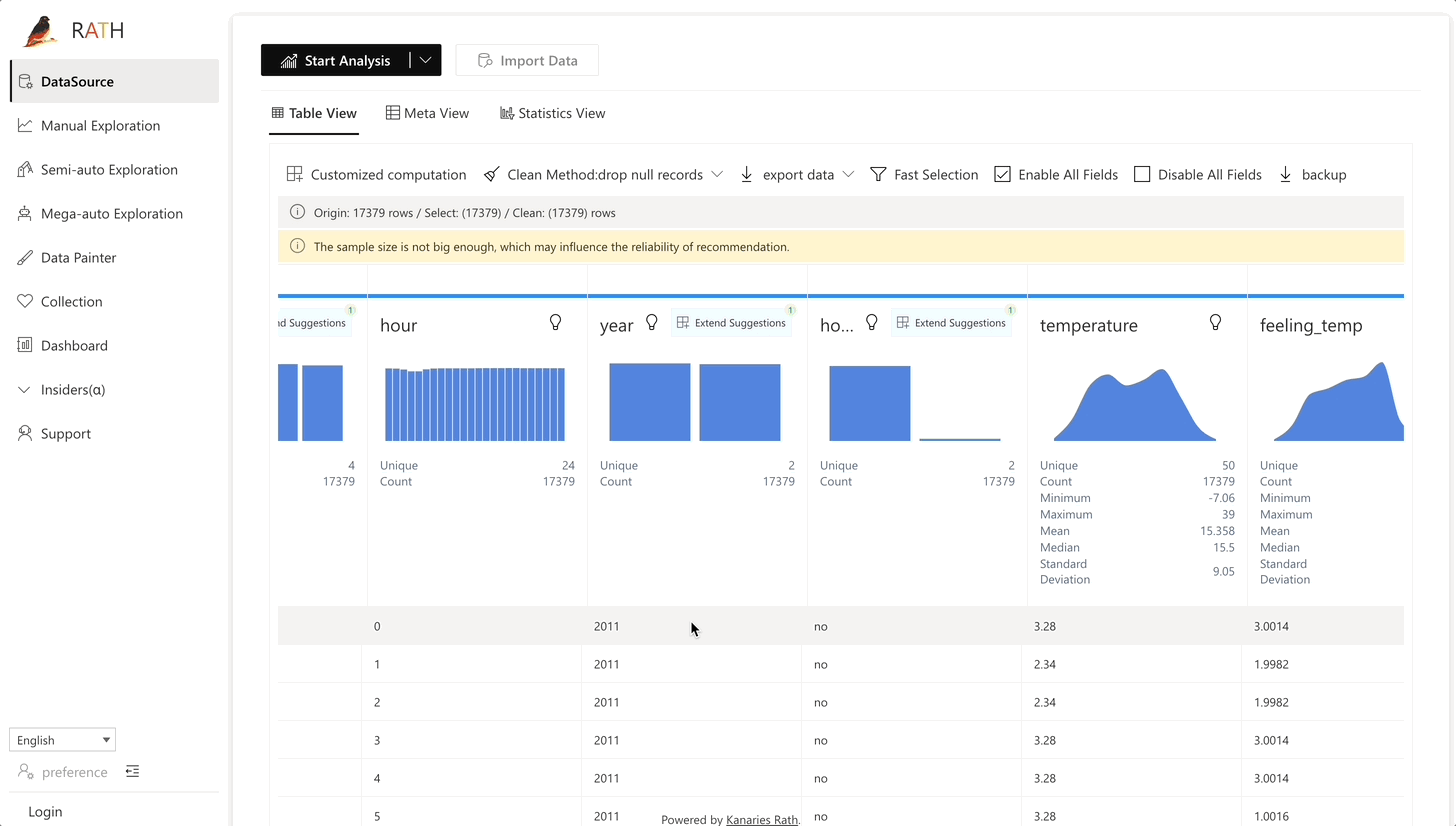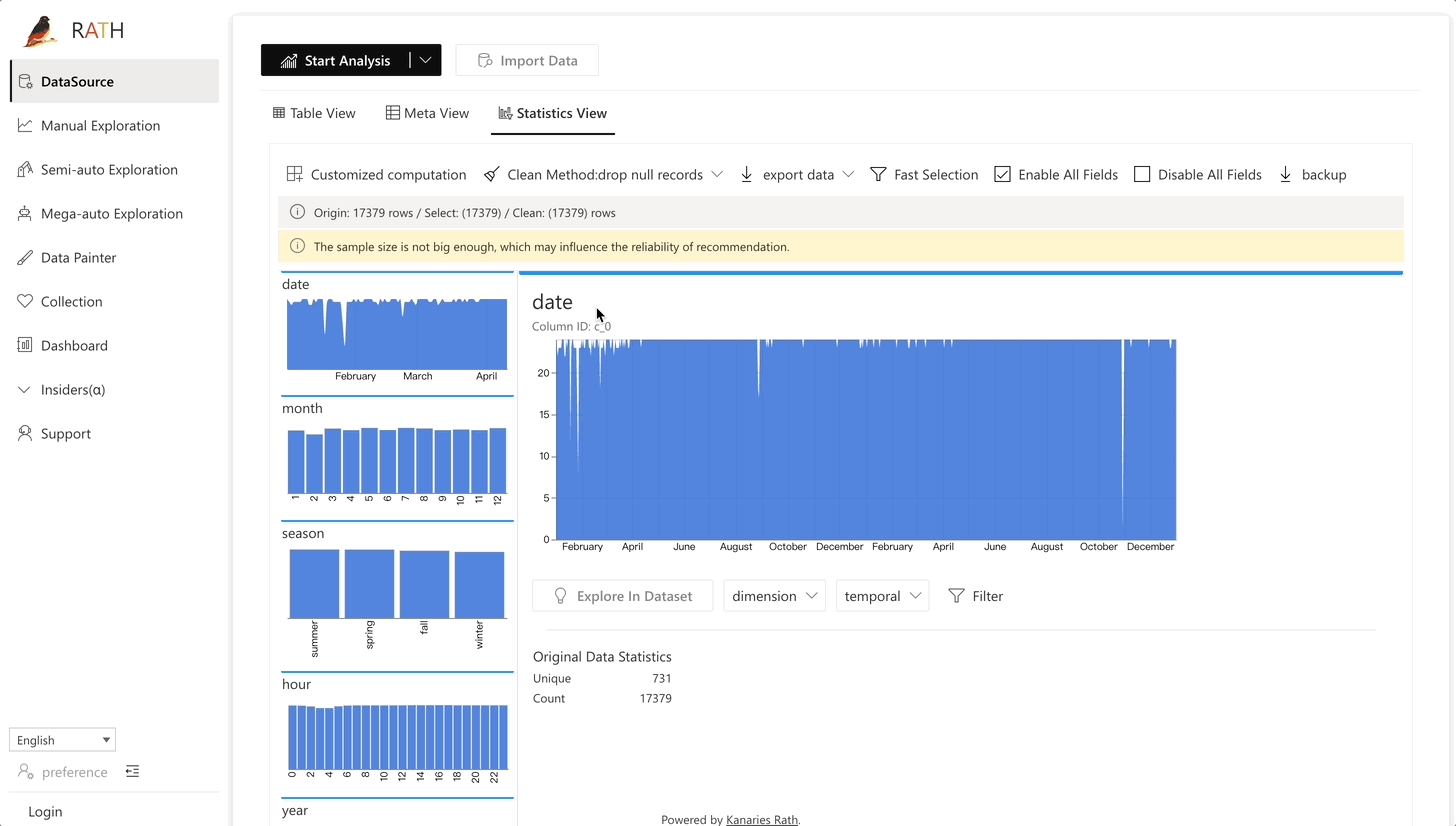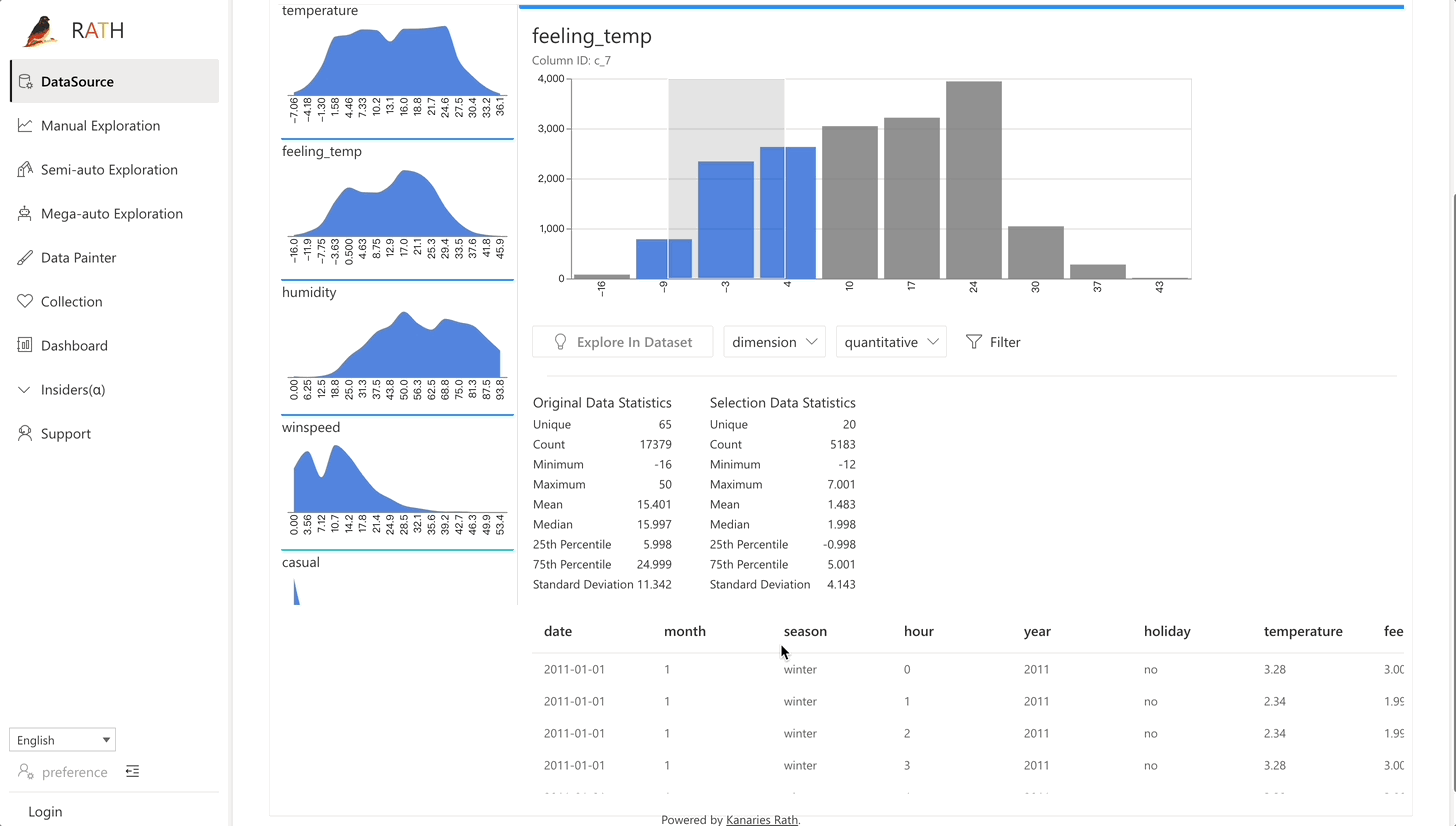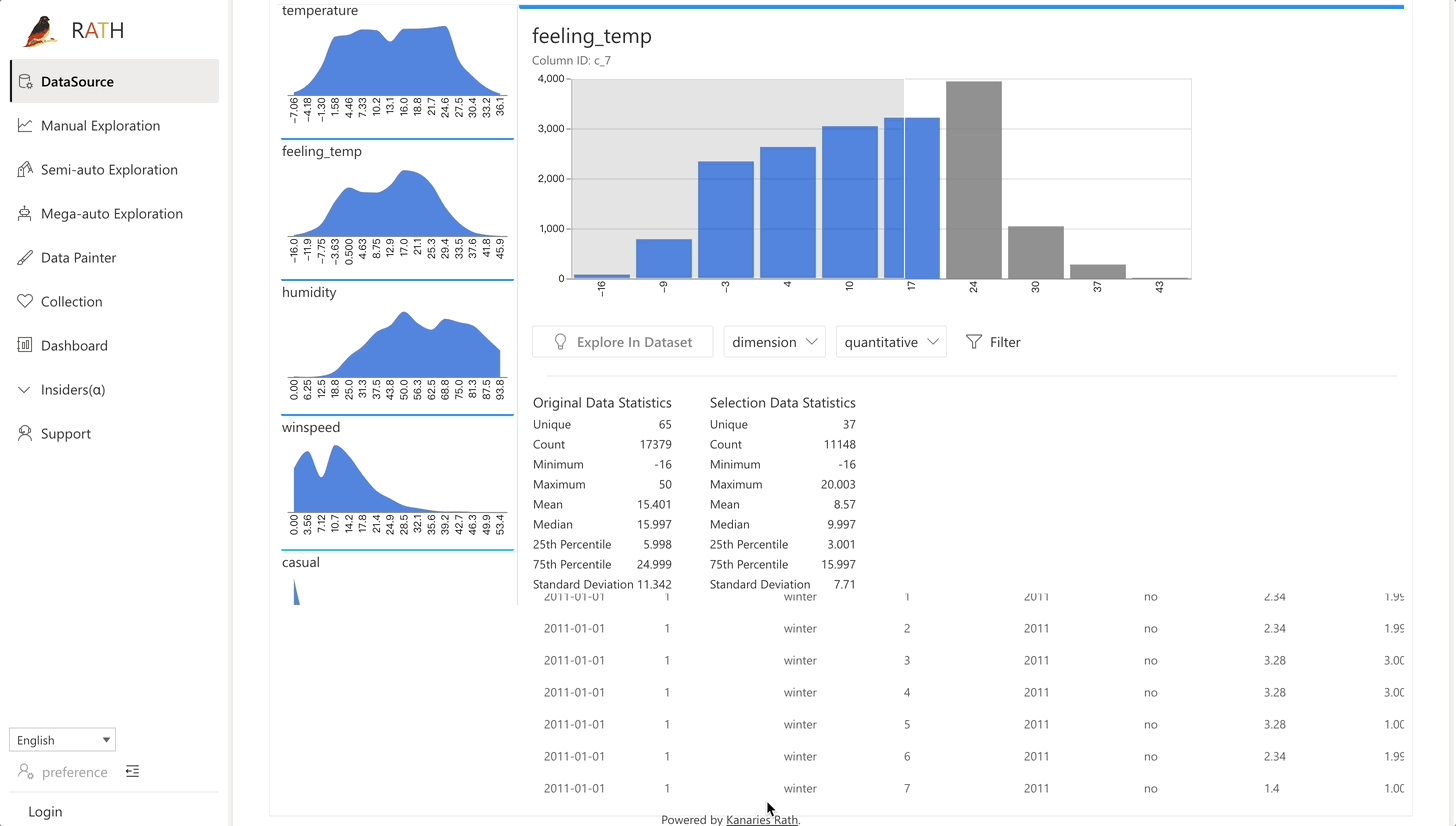 |
| Data Exploration Copilot (opens in a new tab) | Combines automated data exploration and manual exploration. RATH will work as your copilot in data science, learn your interests and uses augmented analytics engine to generate relevant recommendations for you. |  |
| Data Painter (opens in a new tab) | An interactive, instinctive yet powerful tool for exploratory data analysis by directly coloring your data, with further analytical features. | 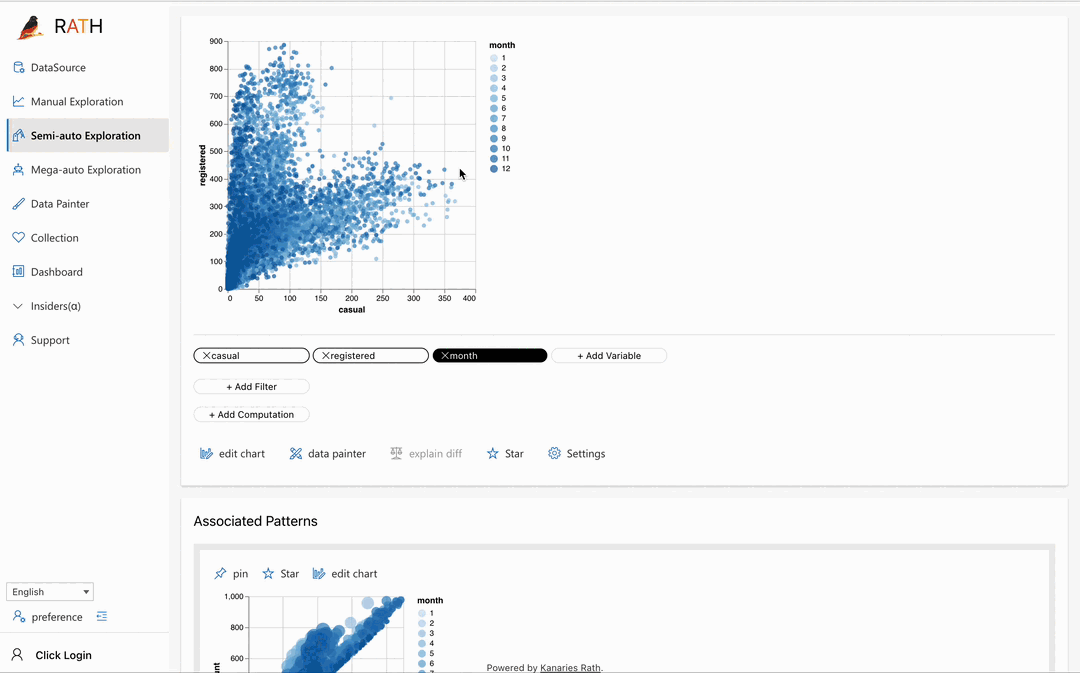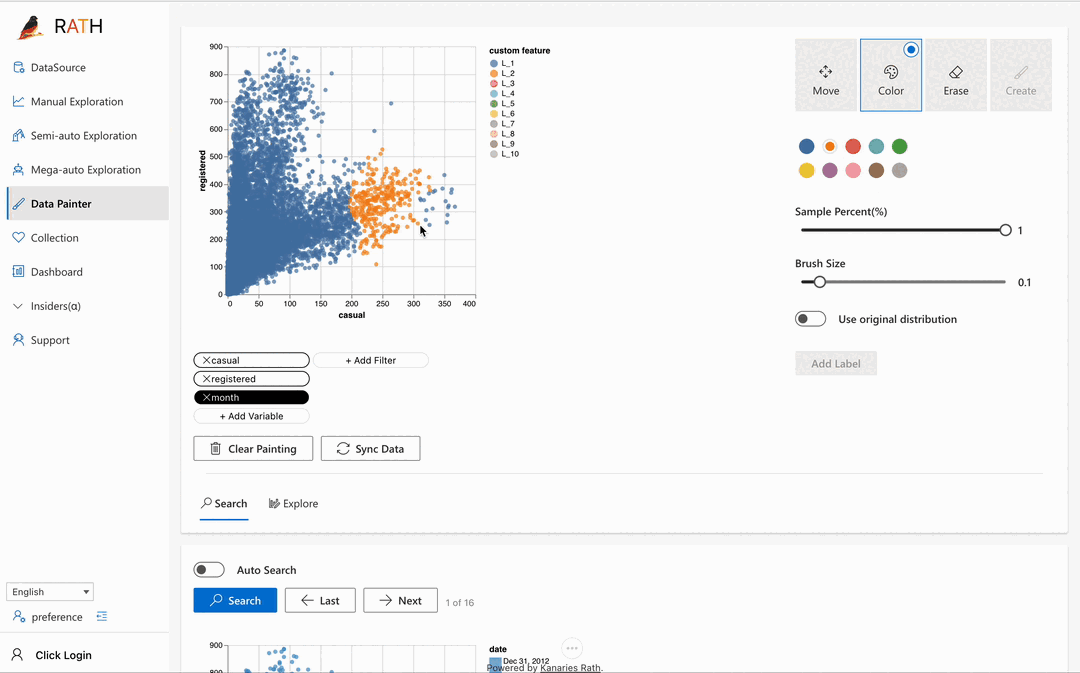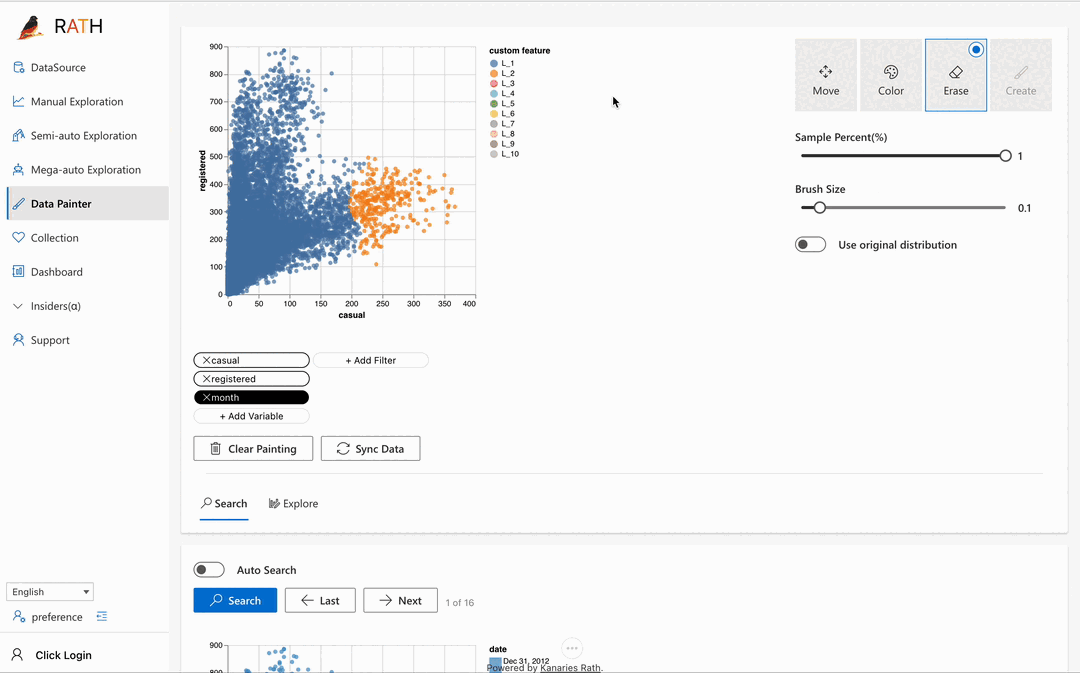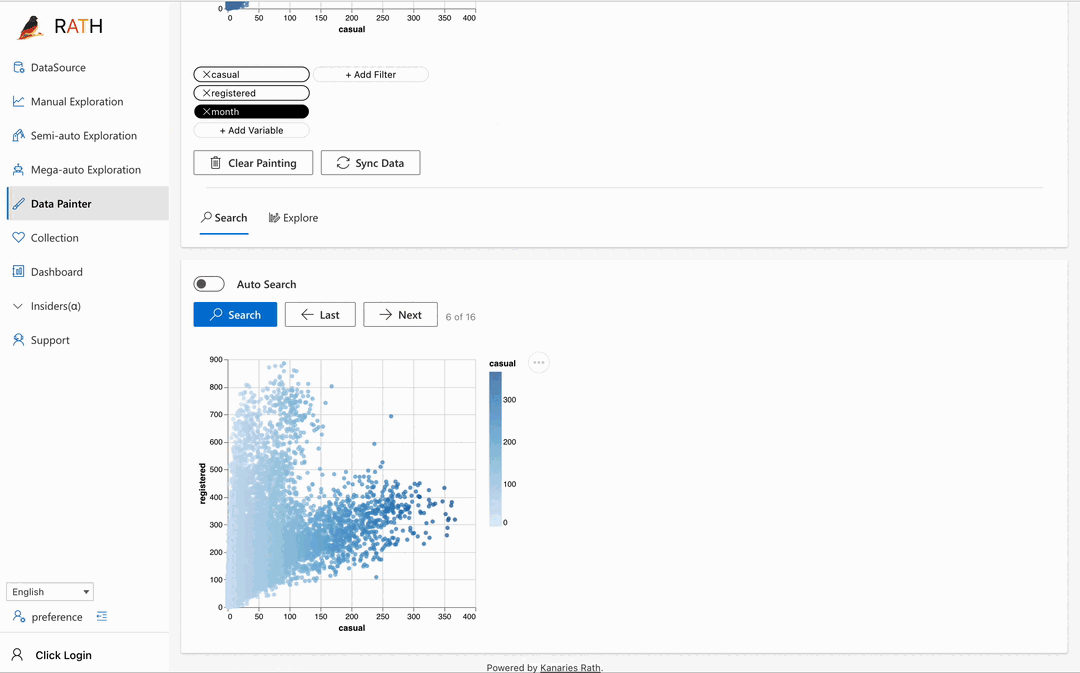 |
| Dashboard | Build a beautiful interactive data dashboard (including an automated dashboard designer which can provide suggestions to your dashboard). | 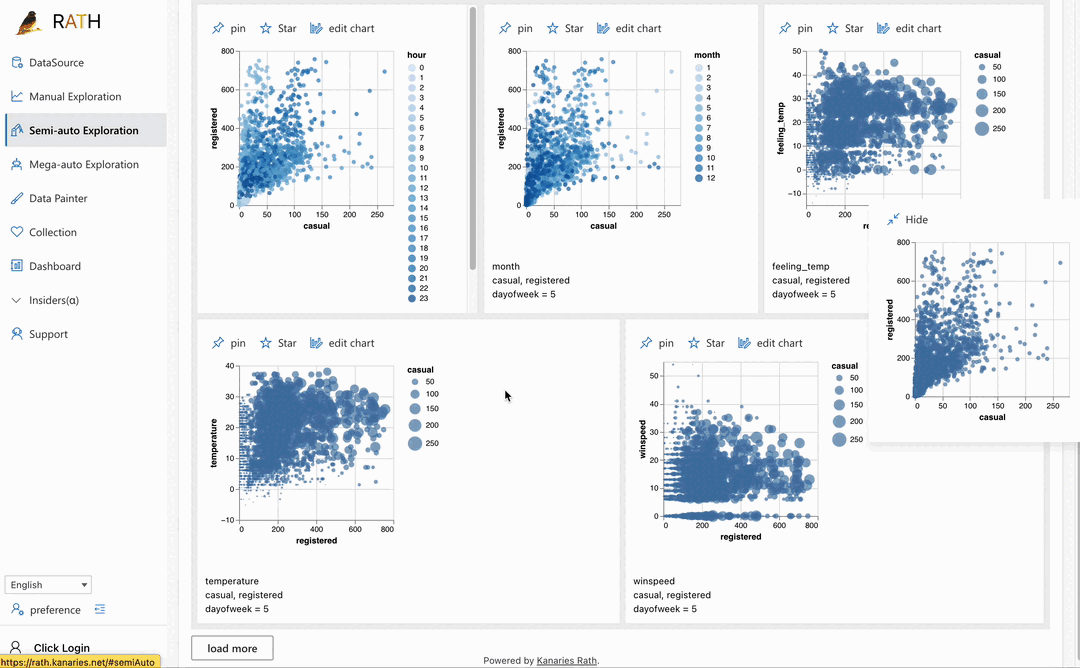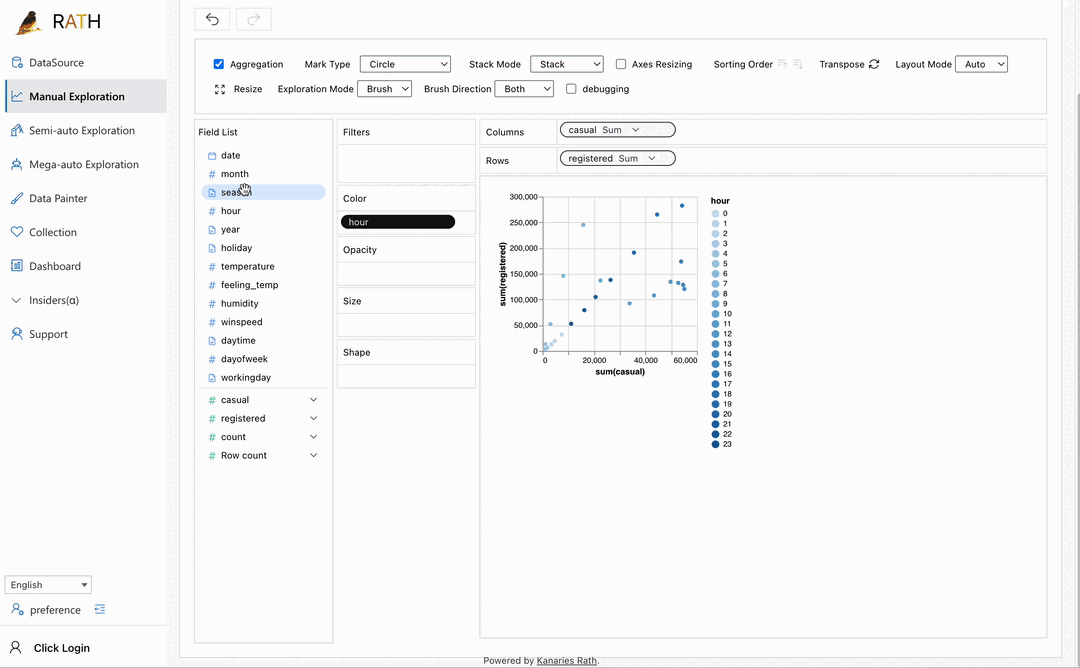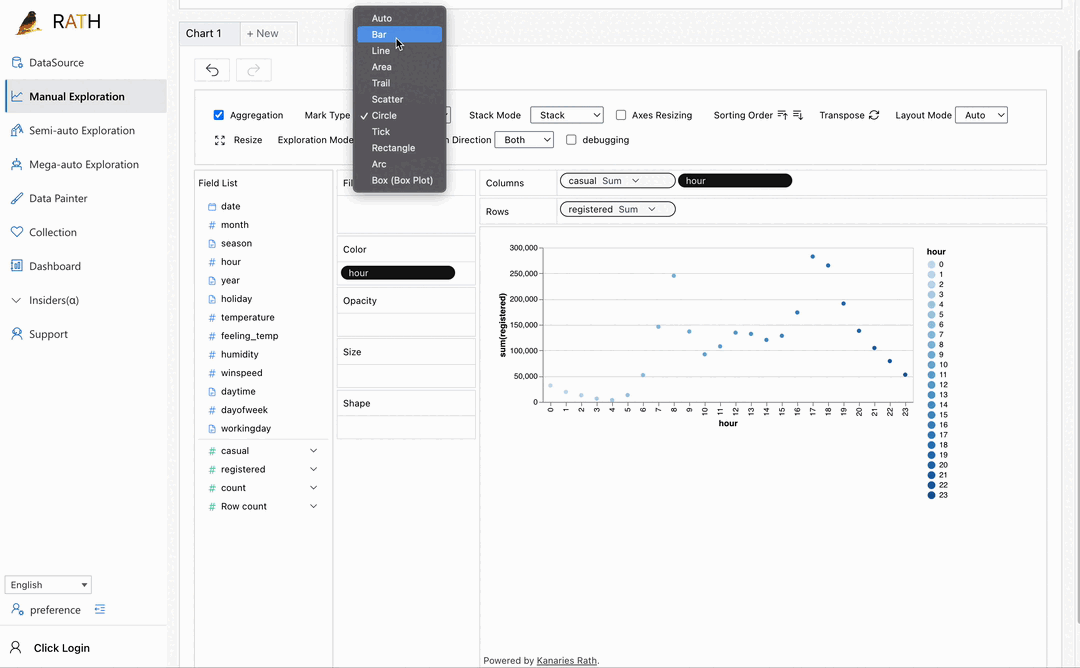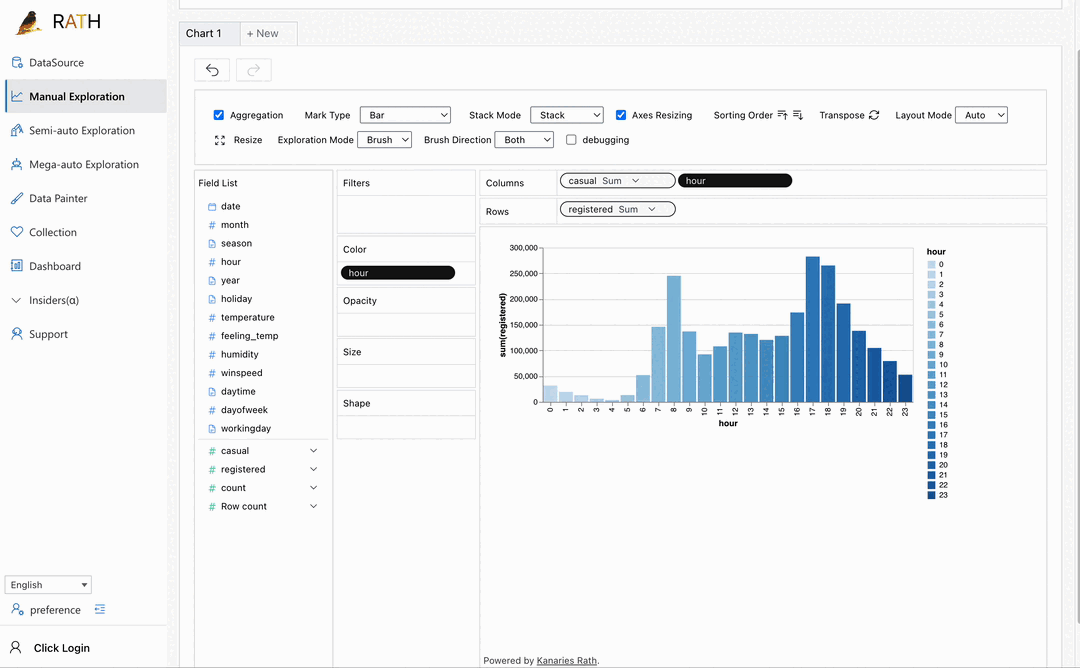 |
| Causal Analysis (opens in a new tab) | Provide causal discovery and explanations for complex relation analysis. |  |
Conclusion
In conclusion, ChatGPT is a powerful tool for generating efficient SQL queries. It can quickly generate complex queries for data aggregation, filtering, and optimization, reducing the risk of errors and saving time for the user.
In addition to ChatGPT's capabilities in generating efficient SQL queries, there is also RATH, an open-source tool that automates the Exploratory Data Analysis (EDA) workflow and provides automated data exploration, visualization and semi-automatic exploration, to make data analysis more efficient and effective.