Vicuna-13B: An Open-Source ChatGPT Alternative That Impresses GPT-4

The world of chatbots has seen significant advancements in recent years with the development of large language models (LLMs) like OpenAI's ChatGPT. However, the details of ChatGPT's architecture and training remain elusive, making it difficult for researchers to build upon its successes. This is where Vicuna comes in—an open-source chatbot alternative to ChatGPT that's backed by a robust dataset and scalable infrastructure. In this article, we'll dive deep into Vicuna's capabilities, how it was developed, and its potential for future research.
What is Vicuna, or Vicuna-13B?
Vicuna (opens in a new tab) is an open-source chatbot model called Vicuna-13B, created by a team of researchers from UC Berkeley, CMU, Stanford, and UC San Diego. It's built by fine-tuning the LLaMA model on user-shared conversations from ShareGPT, and preliminary evaluations show that it achieves more than 90% of ChatGPT's quality. Notably, the cost of training Vicuna-13B is approximately $300.
How Does Vicuna Perform?
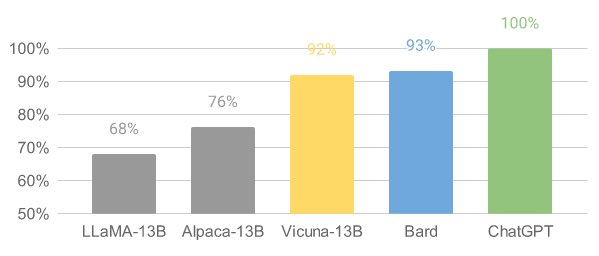
Vicuna has demonstrated impressive performance in preliminary evaluations. By fine-tuning Vicuna with 70,000 user-shared ChatGPT conversations, the model becomes capable of generating detailed and well-structured answers. Its quality is on par with ChatGPT and surpasses other models like LLaMA and Stanford Alpaca in over 90% of cases.
Vicuna's Development: Training and Serving Infrastructure
The Vicuna team collected around 70,000 conversations from ShareGPT.com and enhanced the training scripts provided by Alpaca. They used PyTorch FSDP on 8 A100 GPUs for training and implemented a lightweight distributed serving system. The team also conducted a preliminary evaluation of the model quality by creating a set of 80 diverse questions and utilizing GPT-4 to judge the model outputs.
To train Vicuna, the team fine-tuned the LLaMA base model using user-shared conversations. They ensured data quality by converting HTML back to markdown and filtering out inappropriate or low-quality samples. They also made various improvements to the training recipe, such as memory optimizations, multi-round conversation handling, and cost reduction via spot instances.
The serving system built for Vicuna is capable of serving multiple models with distributed workers. It supports flexible plug-ins for GPU workers from both on-premise clusters and the cloud. By using a fault-tolerant controller and managed spot feature in SkyPilot, the serving system can work well with cheaper spot instances from multiple clouds, reducing serving costs.
The Vicuna team has released the training, serving, and evaluation code on GitHub (opens in a new tab).
Evaluating Chatbots with GPT-4
Evaluating chatbots is a challenging task, but the Vicuna team proposes an evaluation framework based on GPT-4 to automate chatbot performance assessment. They devised eight question categories to test various aspects of chatbot performance and found that GPT-4 can produce relatively consistent scores and detailed explanations of those scores. However, this proposed evaluation framework is not yet a rigorous approach, as large language models like GPT-4 are prone to hallucination. Developing a comprehensive, standardized evaluation system for chatbots remains an open question requiring further research.
Limitations and Future Research
Vicuna, like other large language models, has limitations in tasks involving reasoning or mathematics. It also may have difficulties identifying itself accurately or ensuring the factual accuracy of its outputs. Additionally, it has not been sufficiently optimized for safety, toxicity, or bias mitigation.
Nonetheless, Vicuna serves as an open starting point for future research to address these limitations, together with other latest breakthroughs in the AI field such as Auto-GPT and LongChain.
FAQ
-
How can I obtain and use the Vicuna 13-b model weights? To use the Vicuna 13-b model, you need to download the original LLaMa 13B model and apply the delta weights provided by the Vicuna team. The delta weights can be found at https://huggingface.co/lmsys/vicuna-13b-delta-v0 (opens in a new tab).
-
How do I apply the delta weights to the LLaMa 13B model? You can apply the delta weights by following the command in the FastChat repository: python3 -m fastchat.model.apply_delta --base /path/to/llama-13b --target /output/path/to/vicuna-13b --delta lmsys/vicuna-13b-delta-v0. This command will automatically download and apply the delta weights to the base model.
-
Can I convert the Vicuna 13-b model to the llama.cpp/gpt4all format? Yes, the Vicuna 13-b model can be quantized to the llama.cpp/gpt4all format. The model only tweaks the existing weights slightly, without changing the structure.
-
Are there any licensing issues with using Vicuna 13-b? The Vicuna team releases the weights as delta weights to comply with the LLaMa model license. However, using the model for commercial purposes may still be a bad idea due to potential legal complications.