An Introduction to PyGWalker: Supercharge Your Streamlit Visualizations
PyGWalker (opens in a new tab) is an exceptional Python library that transforms Python dataframes into an intuitive, tableau-esque interface, making data visualization a breeze.
Traditionally used in Jupyter to help data scientists delve into their datasets, PyGWalker's versatility shines when combined with Streamlit. Streamlit's charm lies in its ability to build data applications effortlessly without requiring expertise in frontend or backend technologies. Simply put, you can create and share dashboards without the fuss.
Integrating PyGWalker (opens in a new tab) with Streamlit allows you to establish your own "web tableau". This enables sharing of dashboards and lets users freely explore with PyGWalker (opens in a new tab)'s intuitive drag-and-drop UI. Recent updates have also introduced a "chat-to-charts" feature, enabled by simply adding an API key.
What sets PyGWalker (opens in a new tab) apart is its cloud-native design. With its ability to connect to a multitude of cloud databases, OLAP, or DW, you're guaranteed a high-performance experience, outshining many costly traditional BI tools.
Ready to craft a cloud-based PyGWalker (opens in a new tab) with Streamlit? Let's dive in.
Setting up Dependencies:
pip install pygwalker
pip install streamlitFor this tutorial, we'll utilize an earthquake dataset, which can be loaded from a CSV file.
def get_df() -> pd.DataFrame:
df = pd.read_csv("./Significant Earthquake_Dataset_1900_2023.csv")
df["Time"] = pd.to_datetime(df["Time"]).dt.strftime('%Y-%m-%d %H:%M:%S')
return dfOnce loaded, feed the dataset to PyGWalker:
from pygwalker.api.streamlit import get_streamlit_htm
html = get_streamlit_html(df, use_kernel_calc=True, spec="./spec/geo_vis.json", debug=False)Now, simply render PyGWalker's HTML using Streamlit:
import streamlit.components.v1 as components
components.html(get_pyg_html(df), width=1300, height=1000, scrolling=True)Get your app up and running:
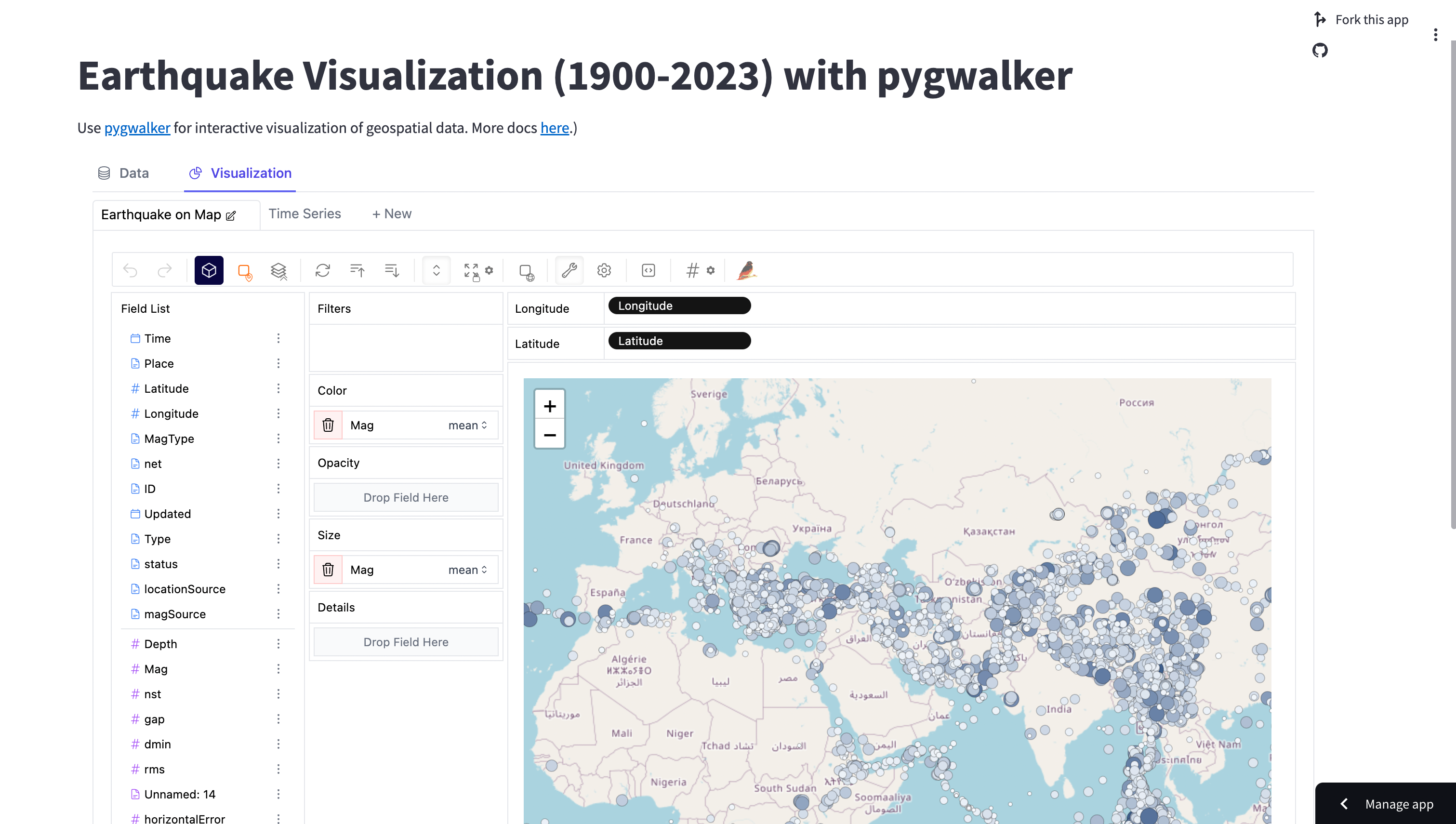
Turbocharge Your Queries with PyGWalker's New Engine
Since v0.3, PyGWalker has incorporated the DuckDB-based computation engine, ensuring swifter data queries, even with expansive datasets.
To activate this, simply add the use_kernel_calc parameter:
pyg.walk(df, use_kernel_calc=True)While this works seamlessly in environments like Jupyter, Streamlit imposes certain data transfer limits between the frontend and backend. However, thanks to Kanaries (opens in a new tab)' development team, there's a simple solution:
from pygwalker.api.streamlit import init_streamlit_comm
init_streamlit_comm()Wrapping Up
Combining PyGWalker (opens in a new tab) with Streamlit paves the way for creating dynamic online interactive data visualization apps with minimal code. Dive in and transform your data explorations today!