Visual ChatGPT: Generate and Manipulate Images through Multi-Modal Interactions
- Name
- Amber de Ligt
Published on
In the realm of artificial intelligence, the ability to generate and manipulate images through multi-modal interactions has been a significant breakthrough. This has been made possible by the development of Visual ChatGPT, a powerful chatbot system developed by OpenAI. This article aims to provide an in-depth understanding of Visual ChatGPT, its applications, and how it stands out in the field of generative AI.
Visual ChatGPT is a unique blend of Natural Language Processing (NLP) and image manipulation capabilities. It leverages Visual Foundation Models (VFMs) to generate visuals and converse with users, providing a multi-modal interaction experience. This innovative technology has opened up new avenues in creative and technical writing, making it a game-changer in the AI industry.
What is Visual ChatGPT?
Visual ChatGPT is an advanced AI chatbot developed by OpenAI. It connects ChatGPT and a series of Visual Foundation Models (VFMs) to enable sending and receiving images during chatting. Instead of training a new model, the researchers linked ChatGPT to 22 different Visual Foundation Models (VFMs), including Stable Diffusion. This allows Visual ChatGPT to understand and generate images in a way that is contextually relevant to the conversation. For instance, if a user asks Visual ChatGPT to generate an image of a "red apple on a green table," it will produce an image that matches the description. This ability to understand and generate visuals based on textual input sets Visual ChatGPT apart from other AI models.
VizGPT: Visualized Data with the Power of ChatGPT
VizGPT (opens in a new tab) is another tool to visualize data using the power of ChatGPT. Powered by the Open Source Data Visualization framework: Vega (opens in a new tab), VizGPT harness the power of AI to give you instant access for generating charts and graphs with simple prompts.
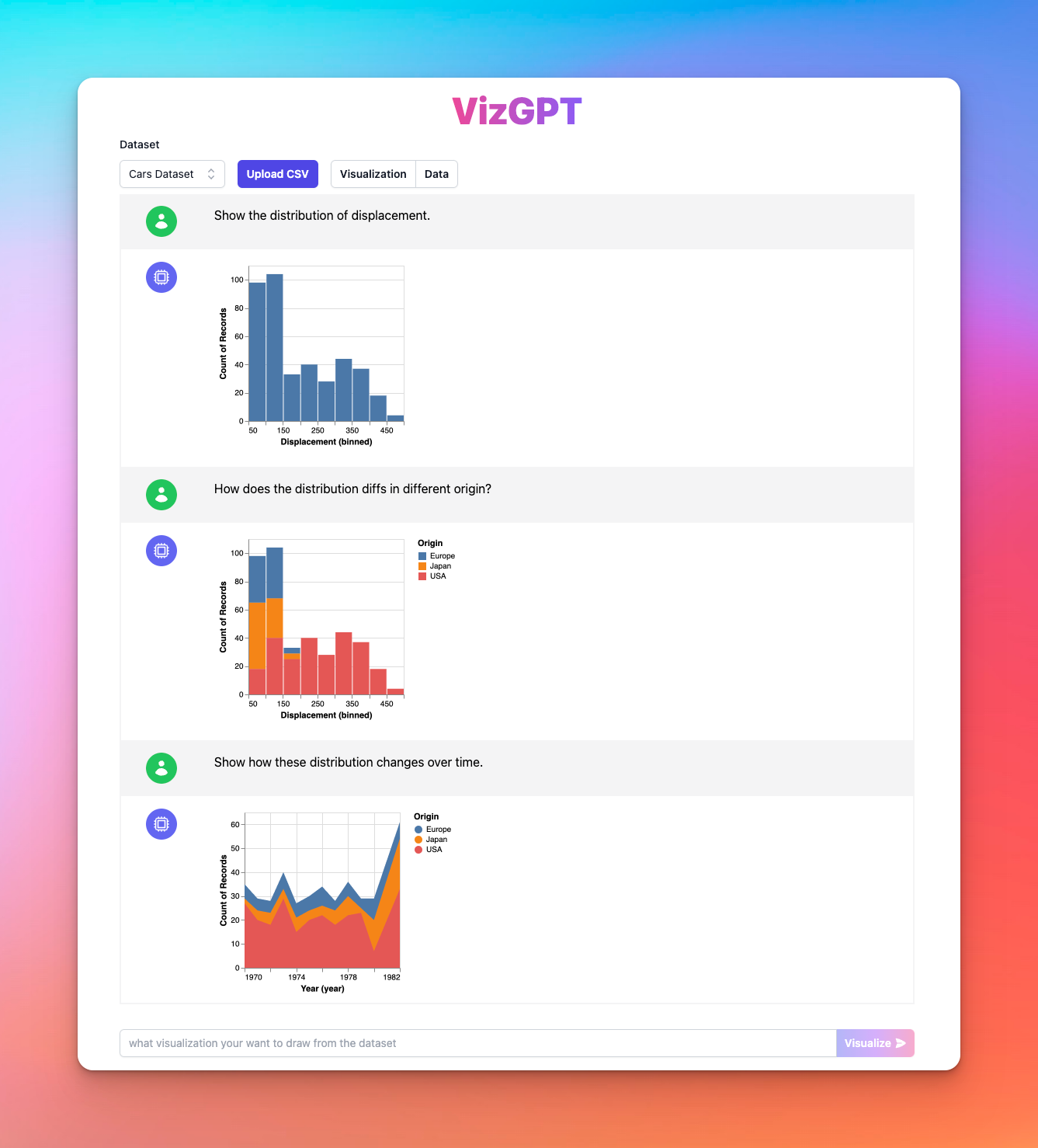
VizGPT allows you to build complex visualizations step by step through chatting, instead of designing a large prompt at once. This makes it ideal for users who are not familiar with data visualization tools or data transformations.
Some of the features VizGPT offers include:
- Natural language to data visualization using Vega-Lite (opens in a new tab)
- Chat context for editing visualizations, allowing users to make changes if the chart doesn't meet their expectations
- Step-by-step exploration of data through chat-based interaction with visualizations
- Uploading your own CSV dataset to create custom visualizations
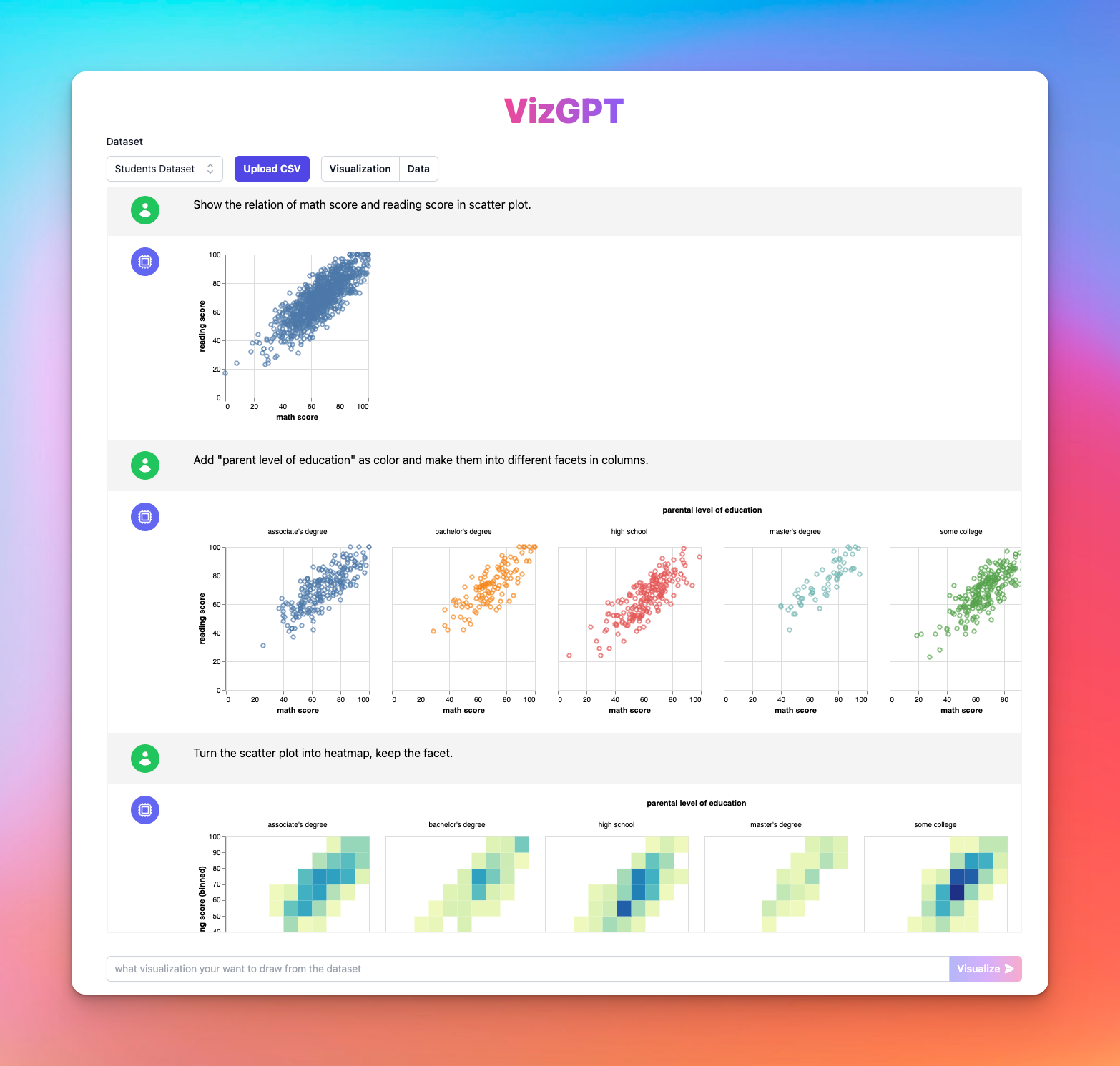
Feeling good? Try it out at VizGPT Online Playground (opens in a new tab) right now!

How to Install Visual ChatGPT?
As of now, Visual ChatGPT is not a standalone software that you can install on your computer. Instead, it's a model developed by OpenAI and the usage depends on the platform that implements this model. For developers interested in using Visual ChatGPT, they can refer to the official GitHub repository of the project. The repository provides detailed instructions on how to use the model, along with the necessary code snippets.
Is Visual ChatGPT Free to Use?
The usage policy and cost of Visual ChatGPT depend on OpenAI's pricing policy. As a research organization, OpenAI has a history of providing public access to their models, but commercial usage might come with certain costs. For the most accurate information, it's recommended to check OpenAI's official website or contact them directly.
What is the Use of Visual ChatGPT?
Visual ChatGPT opens up a new dimension in the field of AI chatbots by introducing the ability to process and generate images. This means that, in addition to text-based conversations, users can now interact with the AI using images. For instance, users can ask the AI to modify an image, generate a new image based on a description, or even ask questions about an image. This multi-modal interaction makes Visual ChatGPT a powerful tool for a wide range of applications, from education and entertainment to professional design and content creation.
How Does Visual ChatGPT Work?
Visual ChatGPT works by connecting ChatGPT with a series of Visual Foundation Models (VFMs), enabling it to send and receive images during a chat. This multi-modal interaction is a significant step forward in AI technology, allowing for more complex and engaging conversations. The VFMs used in Visual ChatGPT are pretrained on a large corpus of internet text and images, enabling the model to understand and generate contextually relevant visuals based on the conversation.
What are the Applications of Visual ChatGPT?
The applications of Visual ChatGPT are vast and varied, thanks to its ability to process and generate images in addition to text-based conversations. Here are a few examples:
- Education: Visual ChatGPT can be used as an interactive learning tool, helping students understand complex concepts through visual aids.
- Entertainment: The model can generate visuals based on user input, adding a new dimension to interactive storytelling and gaming.
- Professional Design: Designers can use Visual ChatGPT to generate initial design drafts or get creative suggestions.
- Content Creation: Content creators can leverage Visual ChatGPT to enhance their content with relevant visuals.
Can Visual ChatGPT Edit Images Too?
Yes, Visual ChatGPT can also edit images based on user instructions. For instance, if a user asks the AI to change the color of an object in an image or add a new element, Visual ChatGPT can process these instructions and generate the edited image.
FAQ
-
What is the difference between Visual ChatGPT and ChatGPT?
Visual ChatGPT is an extension of ChatGPT that incorporates Visual Foundation Models (VFMs). This allows Visual ChatGPT to send and receive images during a chat, in addition to processing text-based conversations.
-
Where can I find a demo for Visual ChatGPT?
As of now, there isn't a standalone demo for Visual ChatGPT. However, developers interested in using Visual ChatGPT can refer to the official GitHub repository of the project for detailed instructions and code snippets.
-
Who developed Visual ChatGPT?
Visual ChatGPT is developed by OpenAI, a leading research organization in the field of artificial intelligence.